Clear Sky Science · sv
Intelligent igenkänning av elevers beteenden för smarta lärmiljöer
Varför smartare klassrum behöver se vad eleverna gör
I många klassrum måste lärare gissa vem som följer med, vem som är vilse och vem som diskret är off‑task. Denna artikel undersöker hur artificiell intelligens automatiskt kan känna igen vad elever gör—som att läsa, skriva eller räcka upp handen—från vanliga klassrumsfotografier. Genom att omvandla råa bilder till pålitliga mått på klassrumsaktivitet syftar systemet till att ge lärarna realtidsfeedback om engagemang utan att förlita sig på tidskrävande observationer eller påträngande övervakning.
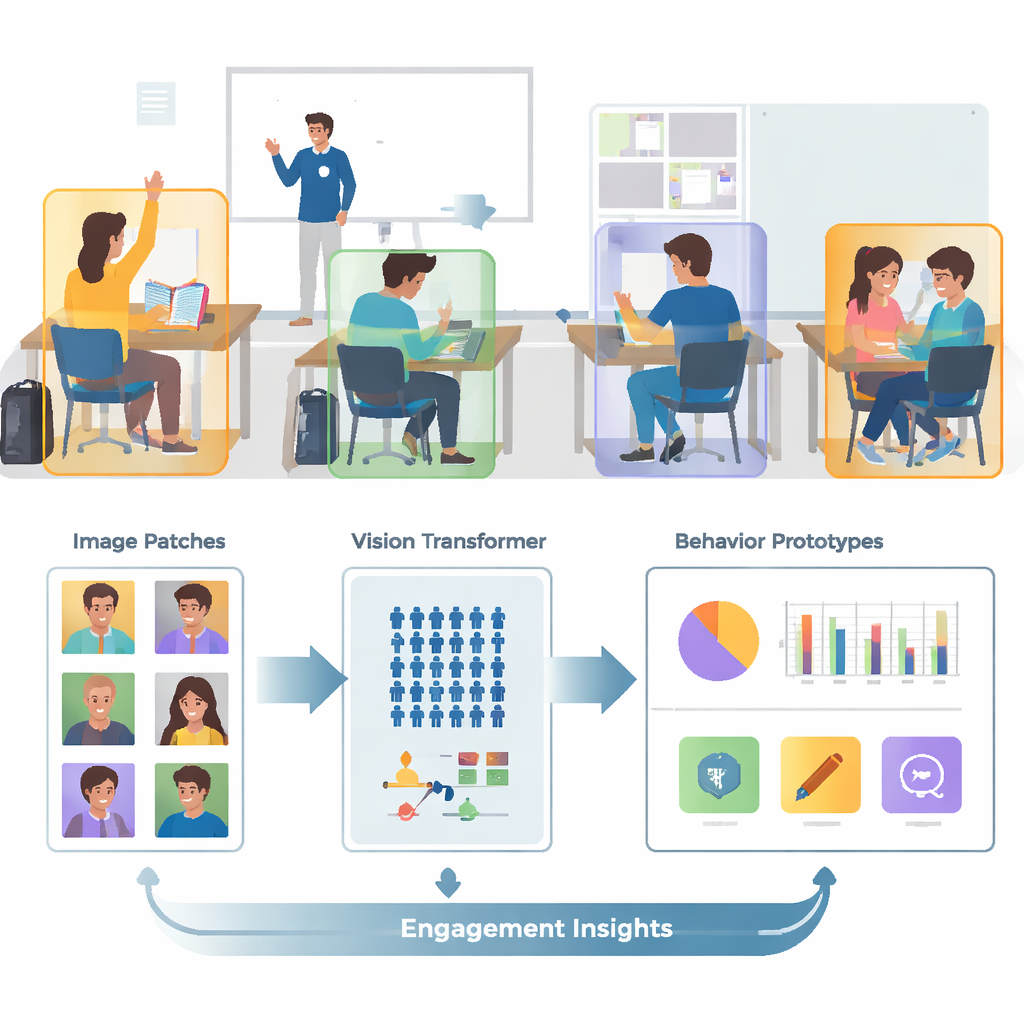
Från röriga foton till fokuserade utsnitt
Verkliga klassrum är trånga, livliga och visuellt förvirrande. En enda bild kan innehålla dussintals elever, överlappande kroppar och störande bakgrundsdetaljer som väggar, skärmar och affischer. Författarna bygger vidare på en offentlig bildsamling kallad SCB‑05, som innehåller tusentals klassrumsfoton märkta med specifika beteenden—såsom handuppräckning, läsning, skrivning, stående, pratande eller interaktion vid tavlan. Istället för att mata in hela scener till datorn använder systemet först annoteringsfiler för att beskära ut bara områdena runt varje elev eller lärare. Detta förbehandlingssteg tar bort mycket av det visuella bruset, så modellen kan fokusera på hållning, handposition och andra ledtrådar som skiljer ett beteende från ett annat.
Hur AI:n lär sig nya beteenden från mycket få exempel
Ett stort problem är att vissa klassrumsbeteenden är vanliga i data (som läsning) medan andra är sällsynta (som korta uppträdanden på scenen). Att samla tillräckligt många märkta bilder för varje möjligt beteende är kostsamt och väcker integritetsfrågor. För att övervinna detta använder författarna en strategi kallad «få‑exempel‑inlärning» (few‑shot learning), där modellen tränas att känna igen nya klasser från bara ett fåtal exempel. De organiserar träningen som många små uppgifter, där varje uppgift innehåller bara några få beteenden och några få provbilder per beteende. För varje uppgift bildar systemet en enkel ”prototyp” för varje beteende genom att genomsnittligt representera dessa exempel internt. Nya bilder klassificeras sedan genom att se vilken prototyp de ligger närmast, vilket gör att modellen snabbt kan anpassa sig även när data är knappa.
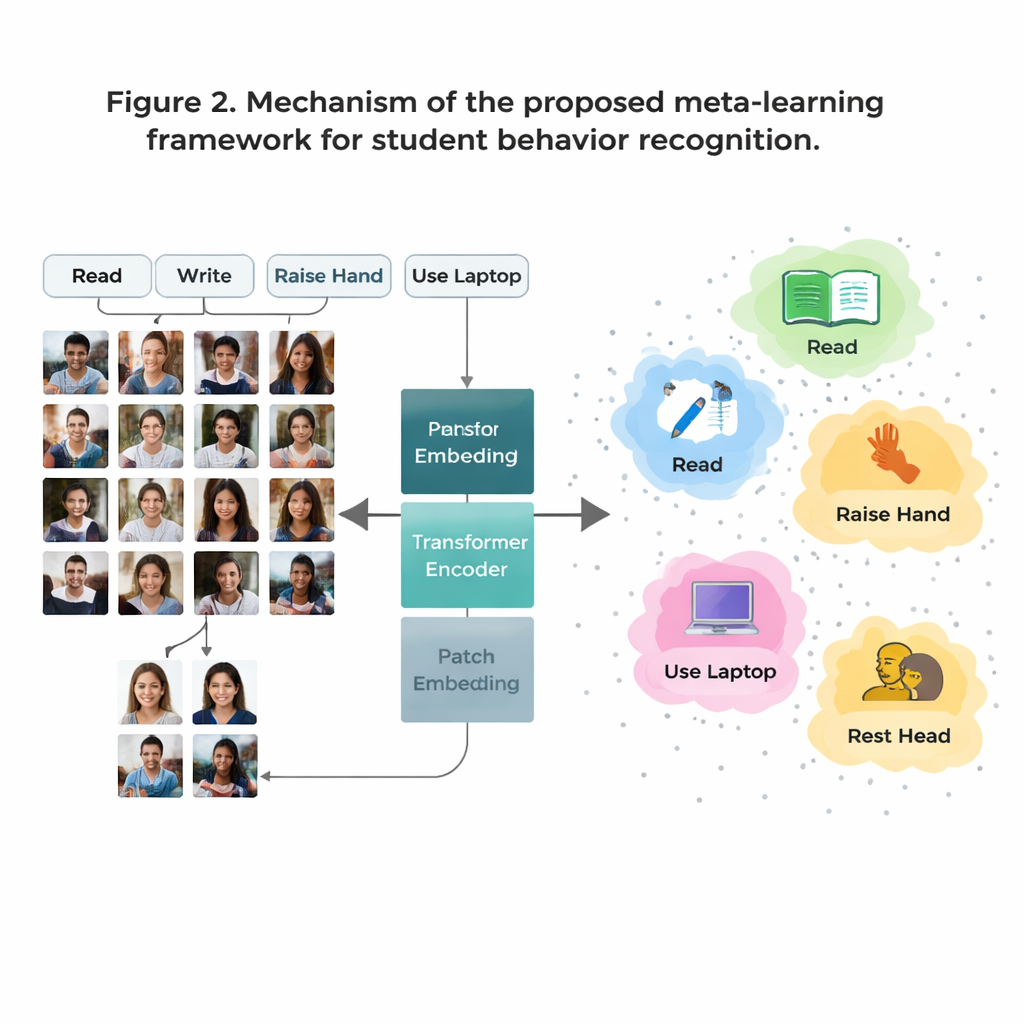
Att se hela klassrummet, inte bara små detaljer
Traditionella bildsystem kallade konvolutionella neurala nätverk tenderar att fokusera på små lokala mönster, som kanter eller texturer. Det kan vara begränsande när två beteenden, som läsning och skrivning, ser väldigt lika ut på nära håll. Detta arbete ersätter de äldre nätverken med en Vision Transformer, en modell som delar upp varje bild i patchar och lär sig hur alla patchar relaterar till varandra. Denna globala vy hjälper systemet att förstå subtila hållningsskillnader och långräckviddssignaler—såsom relationen mellan en uppsträckt hand och en lärare längst fram i rummet. Teamet förbättrar modellen ytterligare genom att träna den att dra ihop bilder av samma beteende samtidigt som den skiljer åt liknande men olika beteenden, med extra fokus på ”svåra” förväxlingsbara fall. Detta gör den interna kartan över beteenden renare och lättare att separera.
Hur väl det fungerar och varför det spelar roll
På SCB‑05‑benchmarken når den föreslagna metoden cirka 91 % total noggrannhet och starka resultat på mer krävande mått som tar hänsyn till obalanserade data. Vanliga beteenden som läsning och handuppräckning känns igen särskilt väl, medan ovanligare beteenden som att skriva på tavlan fortfarande är mer utmanande men ändå presterar bättre än tidigare system. Visuella inspektioner av modellens interna kluster visar att olika beteenden bildar täta, väl separerade grupper, vilket tyder på att AI:n har lärt sig distinkta ”signaturer” för klassrumsaktioner. När modellen testades på en annan klassrumsdatamängd med nya kameravinklar och layouter sjönk prestandan bara marginellt, vilket tyder på att den lärda representationen inte är bunden till ett enda rum eller en enda skola.
Vad detta betyder för undervisning och lärande
I vardagliga termer visar studien att datorer pålitligt kan upptäcka många viktiga elevbeteenden från stillbilder, även när de bara sett ett fåtal exempel av varje. Istället för att ersätta lärare skulle sådana system kunna tyst sammanfatta vem som är engagerad, vem som ofta söker hjälp eller vilka aktiviteter som tenderar att tappa uppmärksamhet—allt utan att spåra elevidentiteter. Med fortsatt arbete kring integritet, rättvisa och analys över tid i video kan denna typ av beteende‑medveten AI bli en kraftfull allierad för lärare som utformar mer responsiva och inkluderande lärmiljöer.
Citering: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Nyckelord: smart klassrum, elevbeteende, datorseende, få-exempel-inlärning, vision transformer