Clear Sky Science · sv
Superupplösning av fjärranalysbilder med kontinuerlig skala över domäner via meta‑viktinlärning
Klarare vyer från rymden
Satellitbilder driver allt från stadsplanering till katastrofinsatser, men många bilder är suddigare än önskvärt på grund av begränsningar i kamerahårdvara och datatransmission. Den här artikeln presenterar ett nytt sätt att omvandla suddiga satellitfoton till skarpare bilder vid valfri zoomnivå, med en inlärningsstrategi som kan anpassa sig till det speciella utseendet hos flygbilder utan att behöva tränas om för varje situation.
Varför skarpare satellitbilder spelar roll
Högupplösta fjärranalysbilder är avgörande för att upptäcka små objekt, följa förändringar på marken och kartlägga markanvändning i detalj. I praktiken måste satelliter kompromissa mellan upplösning, kostnad, sensorsstorlek och bandbredd, så många bilder anländer i lägre kvalitet än analytikerna skulle önska. Traditionella ”superupplösnings”metoder kan skärpa bilder men är oftast tränade för en fast förstoring, som exakt två eller fyra gånger större. Det innebär att operatörer behöver separata modeller för varje zoomnivå, vilket är ineffektivt och oflexibelt när man hanterar många satelliter och varierande uppgifter.
Bortom en universell zoom
Nyare forskning har utvecklat ”kontinuerlig skala”‑superupplösning, som behandlar en bild som en jämn signal och kan generera skarpa resultat vid vilken förstoringsfaktor som helst med en enda modell. De flesta av dessa metoder byggdes och testades på vardagsfoton, inte satellitdata. De bestämmer vanligtvis hur man blandar närliggande pixelinformation med hjälp av fasta geometriska regler—i praktiken genom att vikta grannar efter avstånd. Det fungerar hyfsat för naturliga scener som ansikten eller landskap, men satellitbilder innehåller täta byggnader, repetitiva texturer och skarpa kanter som inte följer samma mönster. När modeller tränade på naturliga foton appliceras på satellitvyer faller deras antaganden, och detaljer som tak, vägar och fordon återges inte troget.
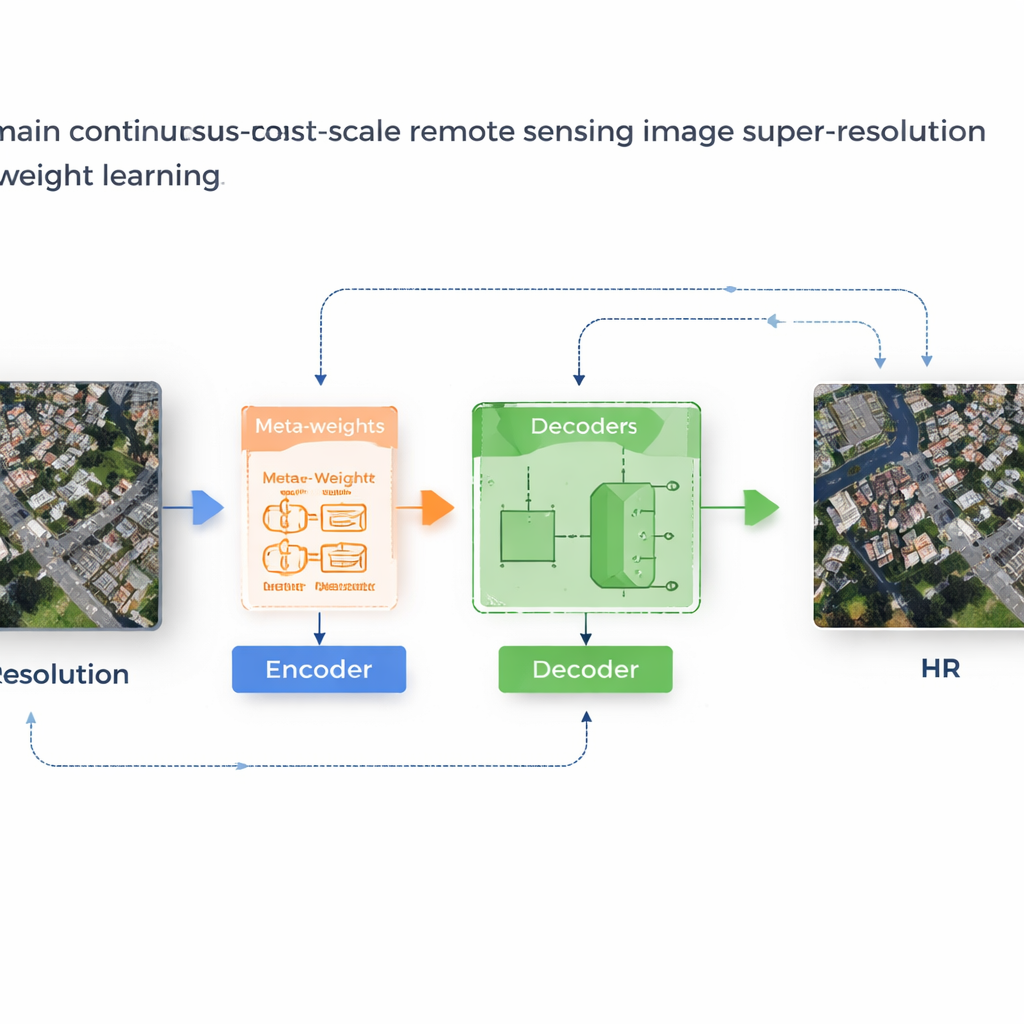
Ett inlärningssystem som anpassar sina egna regler
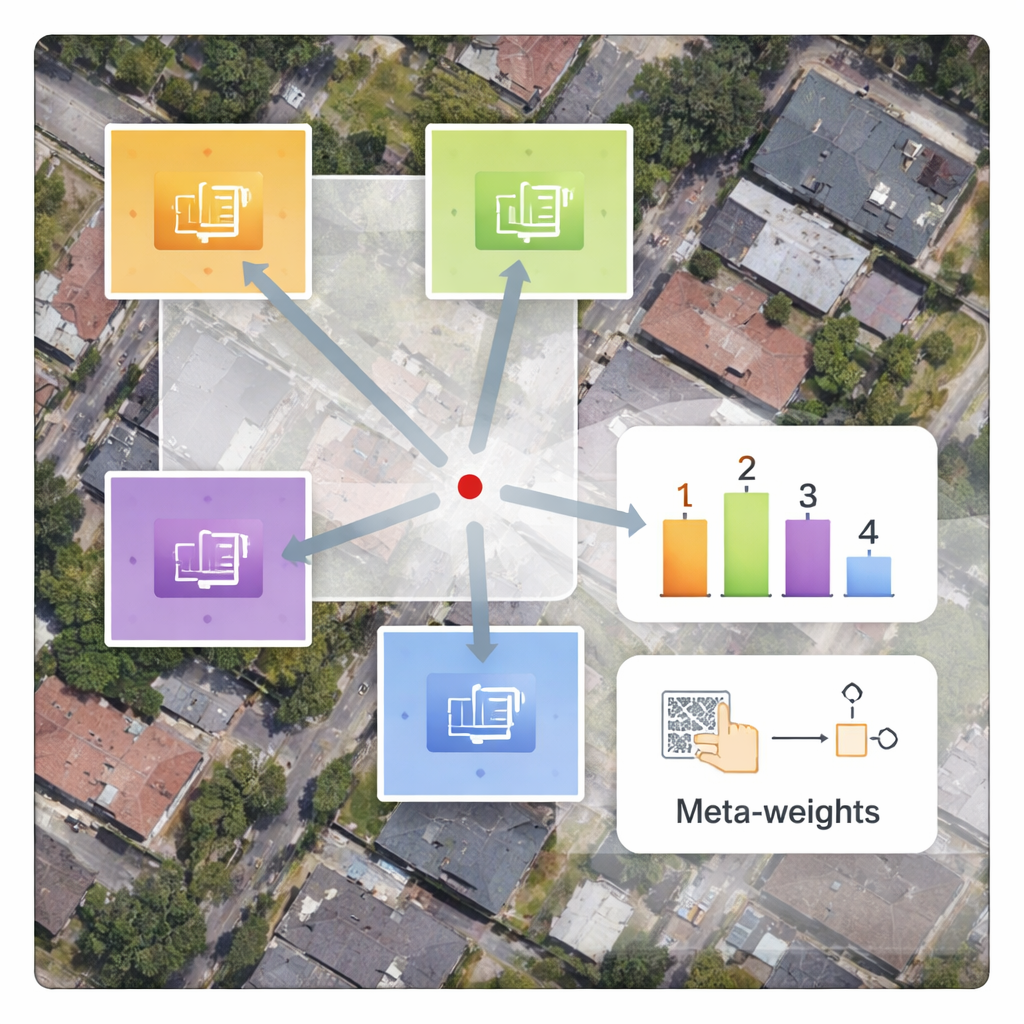
Författarna föreslår ett ramverk kallat MLIN (Meta‑Learning-based Implicit Neural Network) för att lösa detta tvärdomänsproblem. Istället för att handkonstruera hur närliggande pixelfunktioner ska kombineras lär MLIN dessa kombinationsregler från data. Den behåller en kraftfull bildeencoder som ursprungligen tränats på vardagsfoton helt frusen, så att den fortfarande kan extrahera rika visuella mönster utan att förvrängas av de mindre satellitdatamängderna. Ovanpå detta lägger MLIN till en ny ”implicit decoder” utrustad med en meta‑inlärningsmodul. För varje punkt i den högupplösta bilden som modellen vill rekonstruera undersöker denna modul omgivande funktioner och deras precisa positioner och förutspår sedan en uppsättning mjuka vikter som talar om för decodern hur starkt varje granne ska användas. Med andra ord antar systemet inte längre att bara avståndet räknas; det låter lokalt innehåll—som taktexturer, fält eller vatten—forma rekonstruktionen.
Från suddiga kvarter till skarpa strukturer
Tekniskt fungerar metoden genom att sampela ett litet 2×2‑grannskap av dolda funktioner runt varje målposition i utgångsbilden. Ett meta‑nätverk kombinerar information om dessa funktioner, deras relativa koordinater och den begärda förstoringsfaktorn för att välja vikter som summerar till ett. Decodern använder dessa vikter för att blanda prediktioner från varje granne och producerar ett slutligt färgvärde på den positionen. Eftersom denna viktning är inlärd kan MLIN behandla komplexa regioner—som täta bostadsområden, hamnar med fartyg eller flygplatser med startbanor—mycket annorlunda än släta områden som öknar eller hav. Experiment på två välanvända satellitdatamängder (WHU‑RS19 och UCMerced) visar att MLIN konsekvent levererar högre numeriska kvalitetsmått och visuellt skarpare detaljer än flera ledande metoder för kontinuerlig zoom, både vid välkända förstoringsnivåer och extrema förstoringar upp till tio gånger.
Snabbare träning utan extra försening
En praktisk fördel med utformningen är att endast den nya decodern och meta‑vikt‑nätverket behöver tränas på satellitbilder, medan den stora encodern förblir fast. Det minskar träningstiden avsevärt jämfört med metoder som tränar om alla parametrar från grunden. Även om meta‑nätverket medför extra beräkning klarar moderna grafiska processorer dessa operationer effektivt, så tiden för att bearbeta en enskild bild förblir nästan densamma som för befintliga tillvägagångssätt. Ablationsstudier—noggranna tester där delar av systemet tas bort eller förenklas—bekräftar att innehållsmedveten viktning är den avgörande ingrediensen som förbättrar både kantskärpa och texturkonsistens.
Klarare ögon på jorden
Kort sagt visar detta arbete hur man återanvänder kraftfulla bildmodeller tränade på vardagsfoton och smart anpassar dem till den mycket annorlunda världen av satellitbilder. Genom att låta systemet lära sig hur man väger information från närliggande pixlar baserat på vad som faktiskt finns i scenen producerar MLIN klarare, mer tillförlitliga satellitbilder vid vilken zoomnivå som helst från en enda modell. Det innebär bättre verktyg för forskare, planerare och räddningsinsatser som är beroende av detaljerade vyer över vår planet, samtidigt som beräknings‑ och lagringsbehov hålls hanterbara.
Citering: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Nyckelord: satellit‑superupplösning, fjärranalysbilder, meta‑inlärning, godtycklig skalförstoring, bildförbättring