Clear Sky Science · sv
Multiuppgiftsoptimering och konvergensstabilitet med hierarkisk funktionsinlärning för självstyrd optimering
Smartare AI som kan jonglera flera uppgifter samtidigt
Moderna applikationer förlitar sig i allt större utsträckning på artificiell intelligens som måste göra flera saker på en gång—till exempel förstå bilder och text tillsammans, stödja medicinska beslut eller hjälpa fordon att uppfatta vägen. Men när en AI-modell lär sig för många färdigheter samtidigt kan träningen bli instabil och färdigheterna kan störa varandra. Denna artikel introducerar ett nytt ramverk för djupinlärning, kallat Unified Multitask and Multiview Deep Architecture (UMDA), utformat för att låta en modell lära från många datatyper och lösa många uppgifter utan att bli förvirrad eller instabil.
Varför dagens mångsidiga AI ofta har problem
De flesta nuvarande system som lär sig flera uppgifter (multiuppgiftsinlärning) eller kombinerar flera datatyper, såsom bilder och text (multiview-inlärning), lider av tre stora problem. För det första kan olika uppgifter konkurrera med varandra under träning: att förbättra prestandan för en uppgift kan i hemlighet skada en annan, ett problem som kallas negativ överföring. För det andra förloras ofta subtila men viktiga relationer mellan datakällorna när man enkelt staplar eller medelvärdesbildar information. För det tredje kan själva träningsprocessen bli ostadig, med stora svängningar i riktningen för hur modellens parametrar uppdateras. Dessa problem är särskilt allvarliga i verkliga tillämpningar som medicinsk diagnostik eller industriell inspektion, där data är komplexa och besluten måste vara pålitliga.
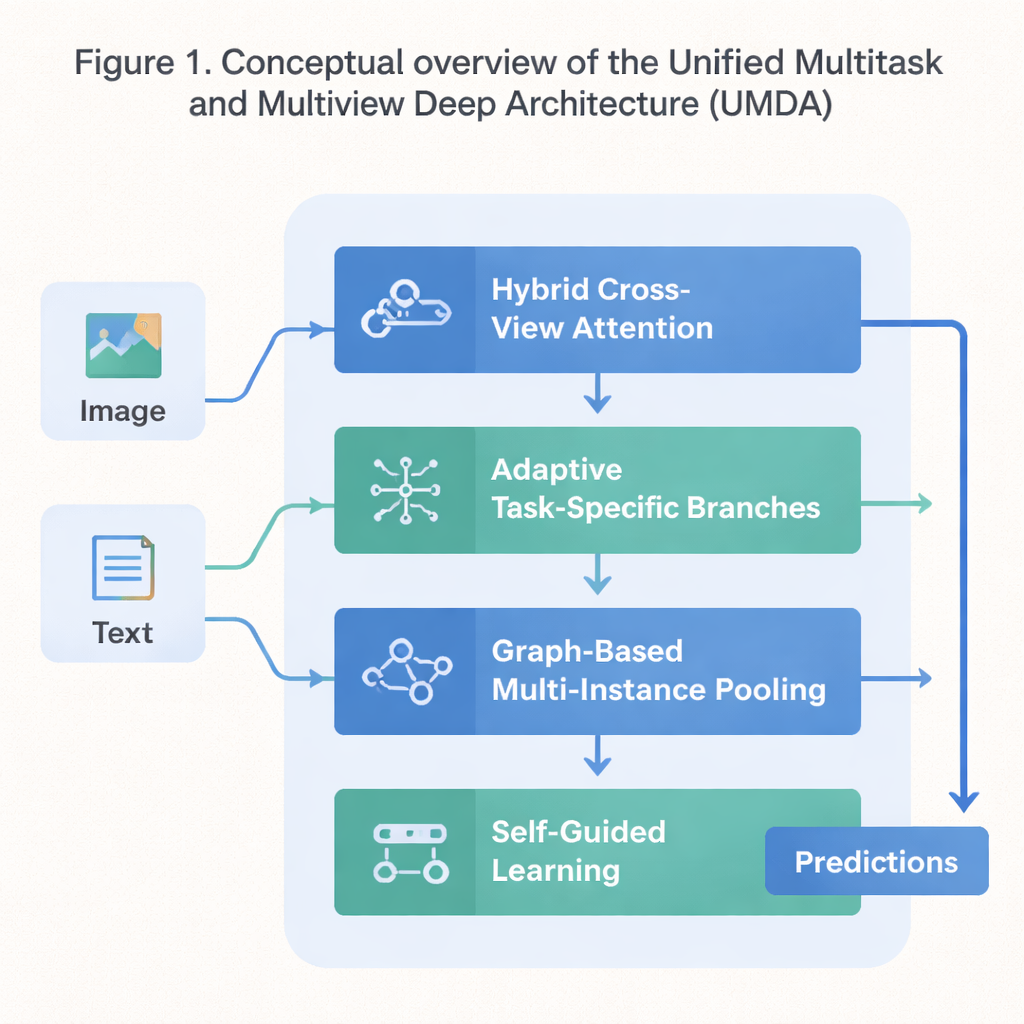
Ett fyrdelat schema för kooperativ inlärning
UMDA angriper dessa svagheter genom att dela upp inlärningsprocessen i fyra tätt sammanlänkade delar som delar information på ett kontrollerat sätt. Den första delen, kallad Hybrid Cross‑View Attention, tittar på olika vyer av samma data—till exempel text och bilder som beskriver en film—och lär sig vilken vy som bör påverka en annan i varje steg. Den använder matematiska verktyg som uppmuntrar modellen att undvika att överförlita sig på en enda vy, att hålla varje vy distinkt, och samtidigt få dem att i stora drag vara överens. Enkelt uttryckt lär det modellen att lyssna på alla sina “sinnen” utan att låta ett av dem dränka de andra.
Hålla uppgifter distinkta men ändå kooperativa
Den andra delen, Adaptive Task‑Specific Branching, separerar generisk kunskap som många uppgifter delar från den speciella kunskap som varje uppgift unikt behöver. Istället för att tvinga alla uppgifter att använda exakt samma funktioner bygger UMDA separata “grenar” för varje uppgift som fortfarande kan kommunicera med varandra genom noggrant viktade kopplingar. Extra strafftermer i träningsmålet driver dessa grenar att bli tillräckligt olika för att specialisera sig, men inte så olika att de driver isär och slutar samarbeta. Denna balans hjälper till att minska skadlig interferens mellan uppgifter samtidigt som de fortfarande kan dra nytta av vad de andra lär sig.
Se struktur i samlingar av exempel
Många verkliga datamängder kommer som samlingar av relaterade objekt—till exempel flera bildfält från ett enda medicinskt preparat eller många ramar från en video. Den tredje delen av UMDA, kallad Graph‑Based Multi‑Instance Pooling, modellerar uttryckligen relationerna mellan dessa objekt genom att behandla dem som noder i ett nätverk. Den kopplar samman liknande objekt, låter information flöda längs dessa kopplingar och sammanfattar sedan hela samlingen till en enda kompakt representation. Extra regularisering puffar närbelägna objekt att vara överens med varandra samtidigt som tillräcklig mångfald bibehålls, vilket gör att modellen kan fånga strukturella mönster som enkel medelvärdesbildning skulle missa.
Självjusterande träning för stadiga framsteg
Den sista delen, Self‑Guided Learning, fokuserar på hur modellen tränas snarare än på dess interna struktur. Den mäter kontinuerligt hur starka och hur lika varje uppgifts träningssignaler är och justerar sedan automatiskt inlärningstakten för varje uppgift. Den jämnar också ut och omviktar gradienterna—signalerna som talar om för modellen hur den ska förändras—så att uppgifter med liknande mål förstärker varandra och uppgifter som drar åt mycket olika håll inte destabiliserar träningen. När den testades på en standarddatamängd som blandar filmhandlingar och affischer uppnådde UMDA högre genomsnittlig noggrannhet än ett dussin toppmoderna konkurrenter, bibehöll relationen mellan vyerna mer konsekvent och minskade en nyckelmetrik för träningsinstabilitet med mer än hälften.
Vad detta betyder för AI-system i verkligheten
För icke‑specialister är huvudbudskapet att UMDA erbjuder ett sätt att bygga enskilda AI‑modeller som kan hantera flera datatyper och mål mer tillförlitligt. Genom att lära modellen när den ska dela information och när den ska hålla den separat, och genom att låta den automatiskt ställa in hur den lär sig, ger ramverket bättre prediktioner, mer sammanhängande interna representationer och jämnare träning. Detta gör det till en lovande byggsten för framtida system inom medicin, autonom körning och andra komplexa tillämpningar där AI måste tolka många signaler samtidigt utan att tappa balansen.
Citering: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Nyckelord: multiuppgiftsinlärning, multimodal AI, djupinlärningsstabilitet, attention-nätverk, grafneurala nätverk