Clear Sky Science · sv
Förbättrad matchprognos i cricket med kärnmetoder för feature-extraktion och backpropagation-nätverk
Smartare prognoser för cricketfans
Cricketentusiaster känner till spänningen i att försöka gissa vem som vinner när en match svänger fram och tillbaka. Denna studie omvandlar den magkänslan till siffror genom att använda moderna dataverktyg för att förutse resultatet av One Day International (ODI)-matcher boll för boll. Istället för att vänta till slutet uppdaterar systemet sin gissning efter varje över och ger en löpande uppskattning av varje lags chanser medan spelet utvecklas.
Läsa matchen som en dataexpert
I arbetets kärna finns en enkel idé: varje över representerar ett ögonblicksbild av matchen. Författarna behandlar var och en av dessa ögonblicksbilder som ett separat matchtillstånd och frågar: ”Givet det vi vet just nu, hur sannolikt är det att Lag B vinner?” För att svara på detta matar de in sex typer av information i ett prognossystem: hur många bollar som återstår, med hur många runs Lag A leder, hur många wickets som återstår, hur starkt varje lag är överlag, om hemmapubliken gynnar ena sidan och vem som vann lottningen. Genom att blanda dessa delar fångar systemet både trycket på resultattavlan och den vidare kontext som kommentatorer pratar om.
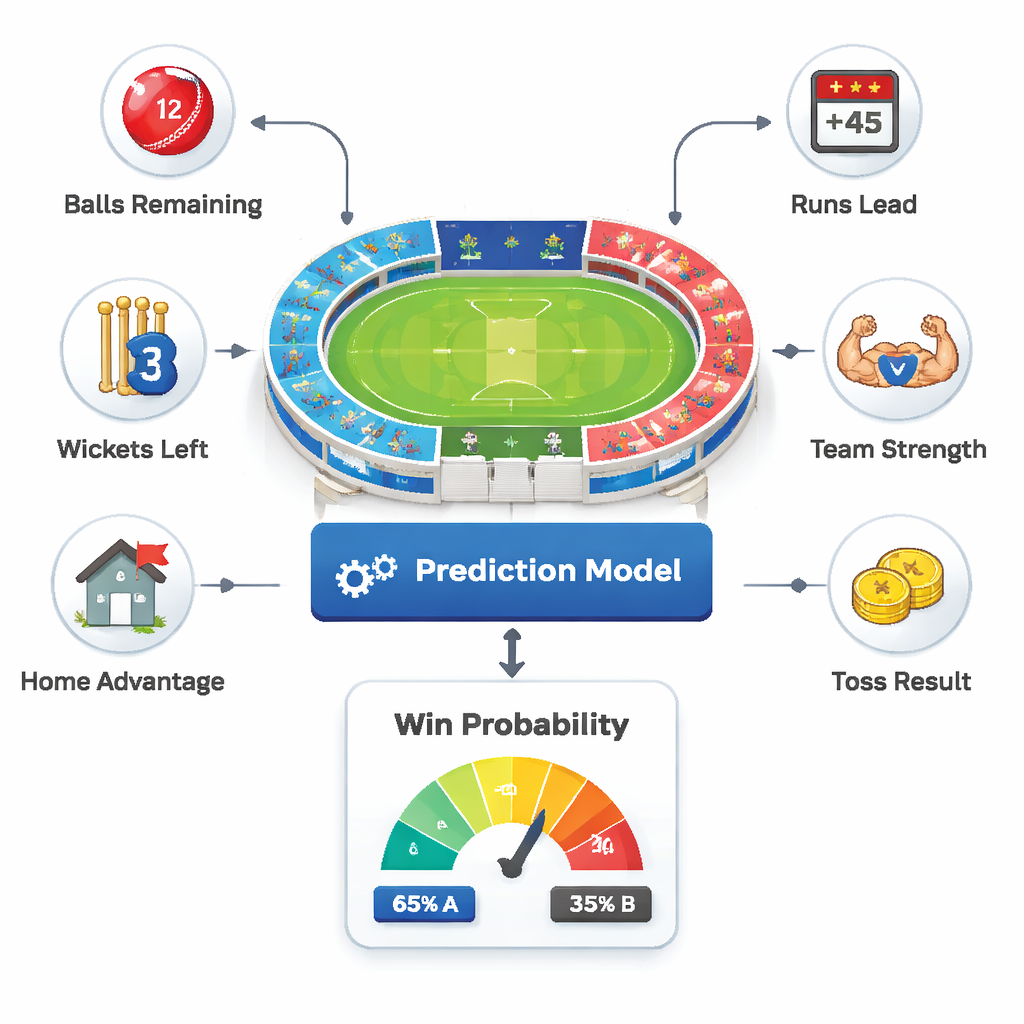
Bygga styrkepoäng från ett sekel av matcher
Modellen tränas på en omfattande samling internationella cricketdata som sträcker sig tillbaka till 1877 och omfattar ODI-, Test- och T20-formaten. För varje spelare samlar forskarna in slag-, kast- och fältningsstatistik såsom medelvärden, strike rates och economy rates. Dessa kombineras till ett ”lagstyrke”-poäng som speglar hur slagkraftigt ett lag är på papper innan en boll har kastats. Under matchen blandas denna långsiktiga styrka med kortsiktiga förhållanden som hemmaplansfördel och den aktuella jaktsituationen, vilket genererar ungefär 100 000 noggrant rengjorda matchtillståndsposter för inlärningssystemet att studera.
Låta algoritmer välja de mest talande ledtrådarna
Inte varje statistik hjälper datorn att fatta bättre beslut, och att ta med för många kan faktiskt förvirra den. För att hantera detta använder författarna en sökmetod inspirerad av sportligor, kallad League Championship Algorithm. I detta tillvägagångssätt ”tävlar” många olika delmängder av funktioner mot varandra. De delmängder som leder till bättre prognoser behandlas som vinnande lag, och svagare kopierar delar av deras strategi. Under många omgångar fokuserar denna process in sig på en liten uppsättning särskilt användbara inmatningar. Tester visar att denna urvalsmetod slår mer konventionella tekniker, vilket leder till högre noggrannhet och en enklare, mer effektiv modell.
Hur neuronätverket lär sig utse en vinnare
När de bästa funktionerna är valda skickas de in i ett backpropagation-neuronätverk, ett flexibelt mönsterigenkänningsverktyg som justerar interna vikter tills det pålitligt kan koppla matchtillstånd till utfall. Varje över blir ett träningsexempel: indata är de sex nyckelkriterierna och utdata är om Lag B så småningom vann eller förlorade. Genom att upprepade gånger jämföra sina gissningar med verkliga resultat och finjustera sina interna inställningar för att minska fel lär sig nätverket gradvis subtila kombinationer av förhållanden — såsom ett starkt jagande lag med wickets kvar och hemmaplansfördel — som ofta leder till seger.
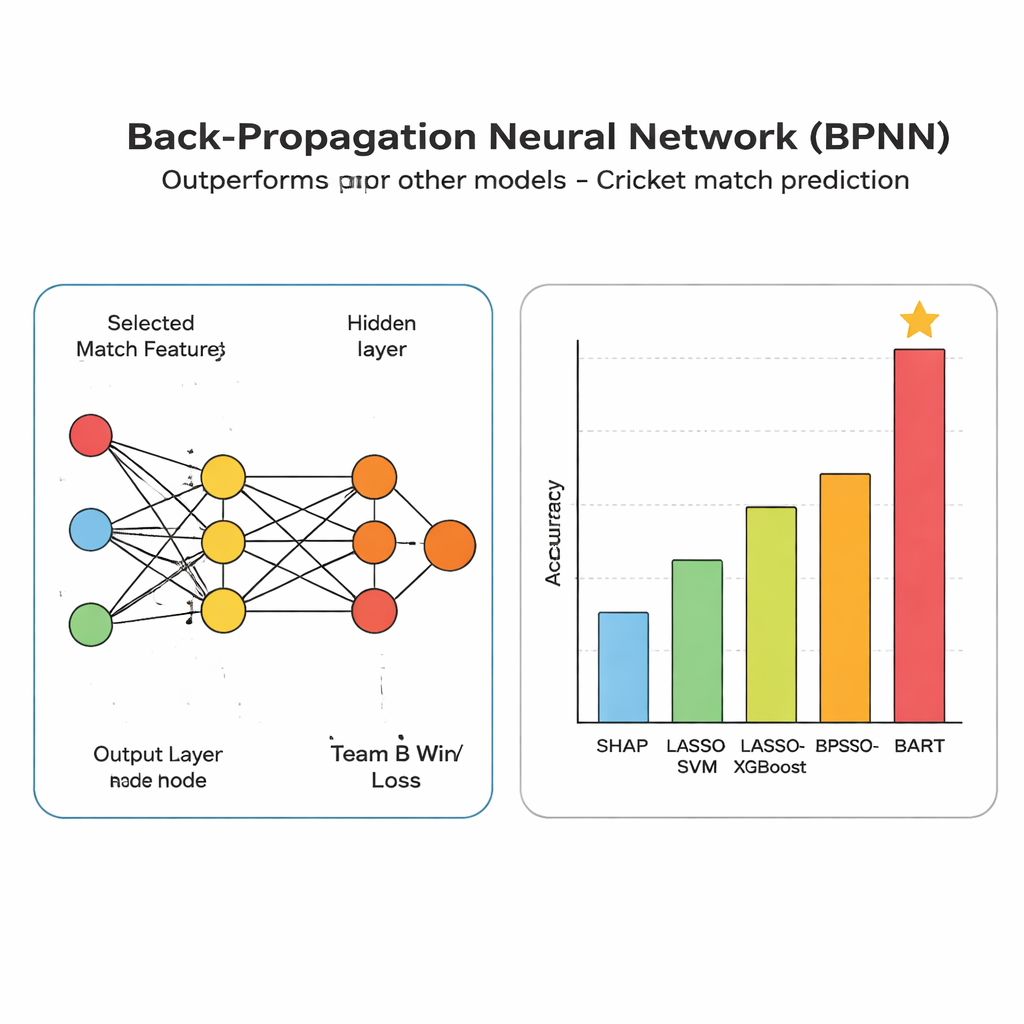
Överträffar rivaler över format
Författarna ställer sitt nätverk mot flera konkurrerande metoder, inklusive modeller som förlitar sig på handplockade funktioner och träd-baserade metoder som är vanligt förekommande i sportanalys. Över ODI-, Test- och T20-data levererar deras system högre noggrannhet, med testresultat runt mitten av 80-procentsintervallet, och starkare prestanda på mått som fångar både hur ofta det identifierar en sannolik vinnare och hur ofta dessa positiva bedömningar är korrekta. De mest inflytelserika faktorerna visar sig vara poängrelaterade statistiker såsom strike rate och totala runs, vilket bekräftar en fans intuition att snabba, konsekventa poänggörare kan påverka jämna matcher.
Vad det betyder för fans, lag och sändningar
För en allmän läsare är slutsatsen att matchens ebb och flod nu kan översättas till precisa, regelbundet uppdaterade vinstsannolikheter. Genom att blanda långsiktiga spelarrekord, omedelbara matchförhållanden och ett omsorgsfullt inställt inlärningssystem visar studien att vi kan förutse utfall med imponerande tillförlitlighet medan spelet fortfarande pågår. Sådana verktyg kan stödja livesänd kommentar, träningsbeslut och till och med mobilappar som visar hur varje boll skjuter oddsen. Enkelt uttryckt demonstrerar forskningen att när crickets rika statistik kombineras med smarta algoritmer kan vår intuitiva känsla för ”vem som ligger bäst till” omvandlas till en klar, datadriven bild.
Citering: Dhinakaran, K., Anbuchelian, S. Enhanced cricket match prediction using kernel methods for feature extraction and back-propagation neural networks. Sci Rep 16, 6478 (2026). https://doi.org/10.1038/s41598-026-36555-6
Nyckelord: cricketanalys, sportprognoser, maskininlärning, neuronätverk, matchprognostisering