Clear Sky Science · sv
En hybridmodell med ResNet50 och vision transformer med uppmärksamhetsmekanism för klassificering av flygbilder
Varför smartare ögon i skyn spelar roll
Flygbilder från drönare och satelliter styr idag insatser vid katastrofer, stadsplanering, jordbruk och till och med trafikstyrning. Men att lära datorer att tolka dessa komplexa, röriga vyer från ovan är fortfarande svårt. Den här studien presenterar två nya artificiella intelligensmodeller som kombinerar olika sätt att ”se” bilder för att känna igen tio objektklasser i drönarbilder — såsom byggnader, bilar, träd och vägar — med bättre noggrannhet än tidigare metoder. Deras angreppssätt kan göra automatiserad övervakning från luften snabbare, mer tillförlitlig och lättare att använda i verkliga tillämpningar.
Utmaningar med att titta ned på världen
Flygbilder skiljer sig från de vardagsfotografier vi tar med telefoner. Objekt är mindre, kan dyka upp i konstiga vinklar och ligger ofta tätt packade. En bil delvis dold av ett träd, en smal gångstig eller högar av skräp efter ett jordskred kan vara svåra även för människor att snabbt upptäcka. Trots det förlitar sig regeringar, räddningstjänster och miljömyndigheter i allt högre grad på drönar- och satellitbilder för att följa översvämningar, skogsbränder, stadsutbredning och infrastrukturens skador. Med tusentals satelliter i omloppsbana och en växande marknad för flygfotografering ökar datamängderna för snabbt för att människor ska kunna granska dem manuellt, vilket ökar behovet av mer precisa och effektiva automatiska klassificeringsmetoder.
Att blanda två sätt maskiner lär sig att se
De flesta framgångsrika bildigenkänningssystem idag bygger på djupinlärning. En familj, konvolutionella neurala nätverk, är mycket bra på att hitta lokala mönster som kanter, texturer och små former. En annan, nyare familj kallad vision transformers behandlar en bild som en sekvens av patchar och är särskilt skicklig på att fånga långräckviddsrelationer, till exempel hur en väg, en klunga tak och ett närliggande öppet fält hör samman i en scen. Detta arbete kombinerar båda: en välkänd konvolutionsmodell kallad ResNet-50 och en vision transformer. Var och en bearbetar samma flygbild och extraherar sin egen uppsättning numeriska egenskaper — kompakta sammanfattningar av vad nätverket lärt sig om scenen. Dessa två informationsströmmar förenas sedan och skickas in i en ”uppmärksamhets”-modul som lär sig vilka egenskaper som är viktigast för att avgöra mellan de tio målklasserna.
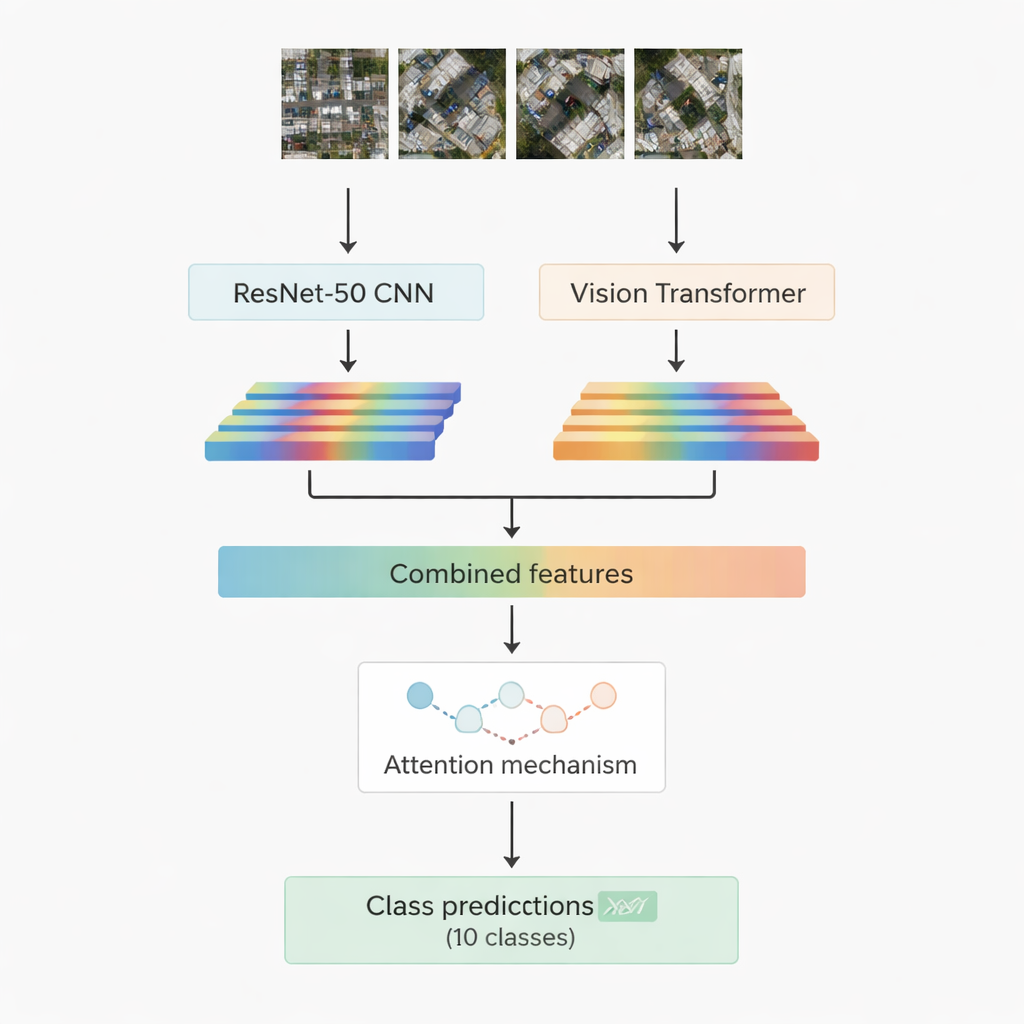
Två uppmärksamhetsstrategier för att fokusera på det som räknas
Forskarna utformar och testar två versioner av sitt hybridssystem. I den första slår de helt enkelt ihop egenskaperna från ResNet-50 och transformern och matar dem in i en multi-head attention-modul. Denna mekanism kan liknas vid många små strålkastare som var och en granskar egenskaperna ur en något annan vinkel och sedan kombinerar sina iakttagelser. I den andra versionen använder de cross-attention: egenskaperna från det konvolutionella nätverket fungerar som en fråga som ber transformerns egenskaper att peka ut var man ska titta, vilket gör att en informationsström kan styra den andra. I båda fallen skickas uppmärksamhetsutgången genom standardlager som slutligen tilldelar bildpatchen till en av tio klasser, inklusive byggnader, bilar, skräp, gångstigar, metallvägar, öppna fält, skuggor, tankar, träd och tak.
Testning på verkliga drönarbilder
För att bedöma hur väl deras modeller fungerar använder författarna en offentlig dataset från den indiska delstaten Sikkim, insamlad av en drönare som flög 60 till 120 meter över marken. Datamaterialet täcker floder, skogar, kullar och bebyggda områden, uppdelat i små patchar så att varje bild tillhör en av de tio kategorierna. Datasetet är balanserat, med lika många tränings- och testbilder per klass, vilket gör det till en rättvis testmiljö. Forskarna tränar båda hybridmodellerna under identiska förhållanden och jämför sedan deras prestanda med hjälp av allmänt använda mått: noggrannhet, precision, recall, F1-score, förväxlingsmatriser och ROC-kurvor. De jämför också sina resultat med flera välkända nätverk och nyare transformer-baserade metoder från aktuell litteratur.

Skarpare klassificering och praktisk potential
Båda hybridmodellerna överträffar tidigare system på detta dataset och når totala noggrannheter på 95,52 % respektive 95,80 %, där multi-head attention-versionen ligger något i ledningen. Deras prestanda förblir stark och stabil över alla tio objekttyper, och detaljerade analyser visar att även de svagare klasserna fortfarande känns igen i höga frekvenser. Detta tyder på att en blandning av konvolutionella nätverk, vision transformers och uppmärksamhetsmekanismer är ett kraftfullt recept för att förstå komplexa flygscener. För en allmän läsare är slutsatsen att datorer blir mycket bättre på att svara på frågor som ”Var finns vägarna?” eller ”Vilka patchar visar skräp eller byggnader?” i mycket stora samlingar av drönarbilder. Allteftersom sådana modeller förfinas och tillämpas på nya dataset kan de ligga till grund för smartare katastrofinsatser, miljöövervakning och smarta stadstjänster som kräver snabb och pålitlig tolkning av bilder från ovan.
Citering: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Nyckelord: klassificering av flygbilder, drönarbilder, deep learning, vision transformer, fjärranalys