Clear Sky Science · sv
Optimerad uppmärksamhetsbaserad kaskadvis shuffle-långtidsberoende nätverk: prestandaanalys av adaptivt e‑lärande bland IT‑professionella
Smartare onlineutbildning för yrkesverksamma inom teknik
För många it‑yrkespersoner är nätkurser nu det huvudsakliga sättet att hålla färdigheterna aktuella. Men de flesta utbildningsplattformar bedömer fortfarande deltagare med trubbiga verktyg som quizzpoäng eller slutförandemärken. Denna studie presenterar ett smartare sätt att läsa av de digitala ”fotavtryck” som lärande lämnar efter sig och omvandla dem till precisa, realtidsinsikter om hur väl varje person faktiskt lär sig.
Varför standardiserade onlinekurser inte räcker
Konventionellt e‑lärande behandlar de flesta deltagare lika: alla ser samma moduler, gör samma quiz och bedöms med samma fasta tester. Det förbigår hur olika yrkespersoner utvecklas, särskilt inom snabbföränderliga områden som cybersäkerhet eller molntjänster. Tidigare forskning försökte åtgärda detta med maskininlärning—genom att kombinera quizpoäng, nedlagd tid och klickdata för att förutsäga framgång—men många modeller hade problem med brusiga eller ofullständiga data, kunde inte skala till realistiska plattformar eller misslyckades med att följa hur lärandet utvecklas över veckor och månader. Resultatet blev ofta fördröjd, grov feedback som inte enkelt kunde styra skräddarsytt innehåll eller tidiga insatser.
Att förvandla råa kursloggar till rena, rättvisa data
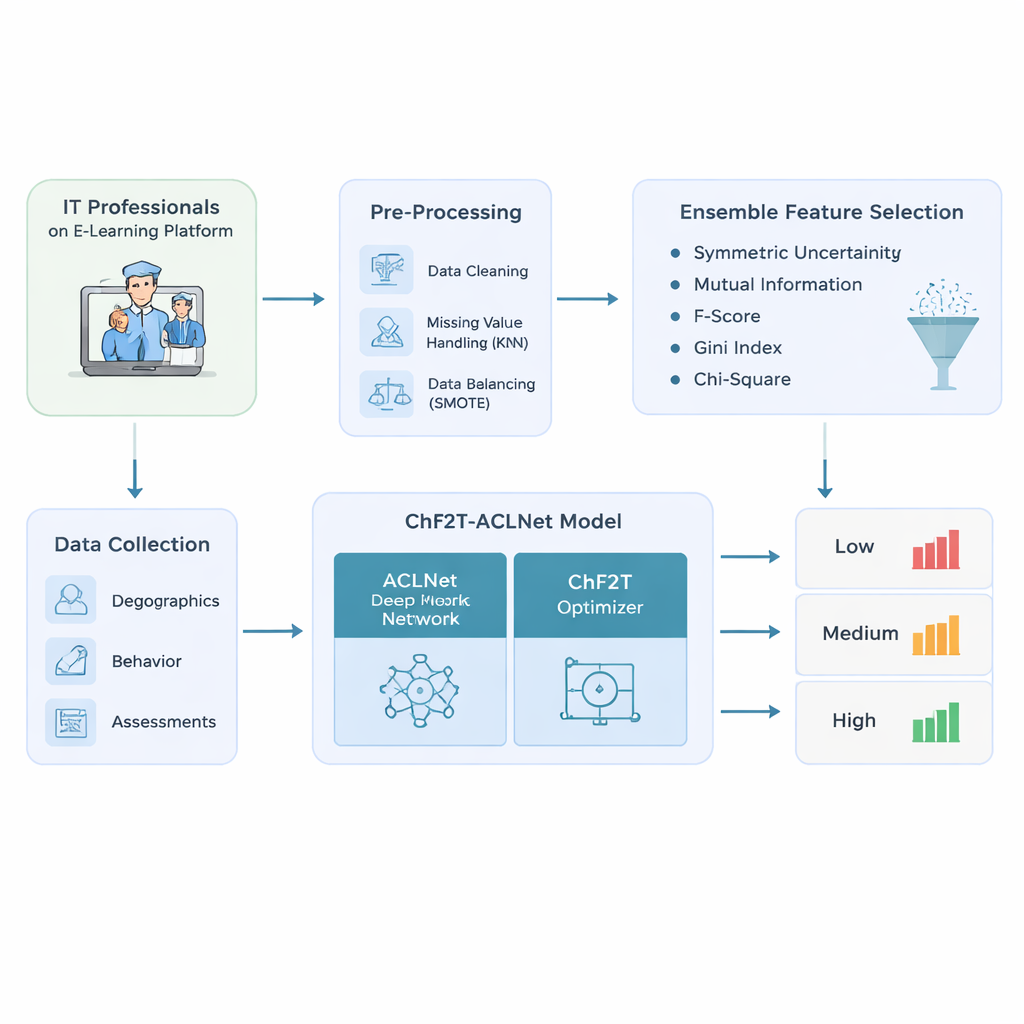
Författarna börjar med att utforma en noggrann datapipeline för IT‑yrkespersoner som använder adaptiva e‑lärandeplattformar. De samlar en rik blandning av information: grundläggande profiluppgifter som ålder och yrkesroll; beteendesspår som tid som lagts ned, åtkomstdatum och aktiva dagar; och prestationsindikatorer inklusive quizpoäng, försök, certifikat och omdömesbetyg. Innan modellering rensas data—dubbletter tas bort, saknade värden skattas genom att betrakta liknande deltagare, och skeva klassfördelningar korrigeras så att låga, medelstora och höga prestationer representeras mer rättvist. Detta balanseringssteg förhindrar modeller som är överdrivet säkra bara för de mest vanliga ”genomsnittliga” deltagarna och blinda för dem som har svårt eller utmärker sig.
Välja endast de mest talande signalerna
Ur det rengjorda datasetet matar systemet inte blint in varje tillgänglig kolumn i en svart låda. I stället använder det ett ensemble av fem enkla rankningsmetoder för att avgöra vilka funktioner som verkligen betyder något för att förutsäga läranderesultat. Varje metod undersöker sambandet mellan en kandidatfunktion—som antal quizförsök eller nedlagd tid—och den slutliga prestationsklassen. Genom att kombinera deras rankningar med ett medianvärde filtrerar tillvägagångssättet bort brusiga eller redundanta signaler och behåller bara de mest informativa. Detta minskar inte bara den beräkningsmängd den efterföljande modellen behöver, utan hjälper också modellen att fokusera på mönster som meningsfullt skiljer låga, medelstora och höga presterare.
Ett hybridnätverk tränat som ett sportlag
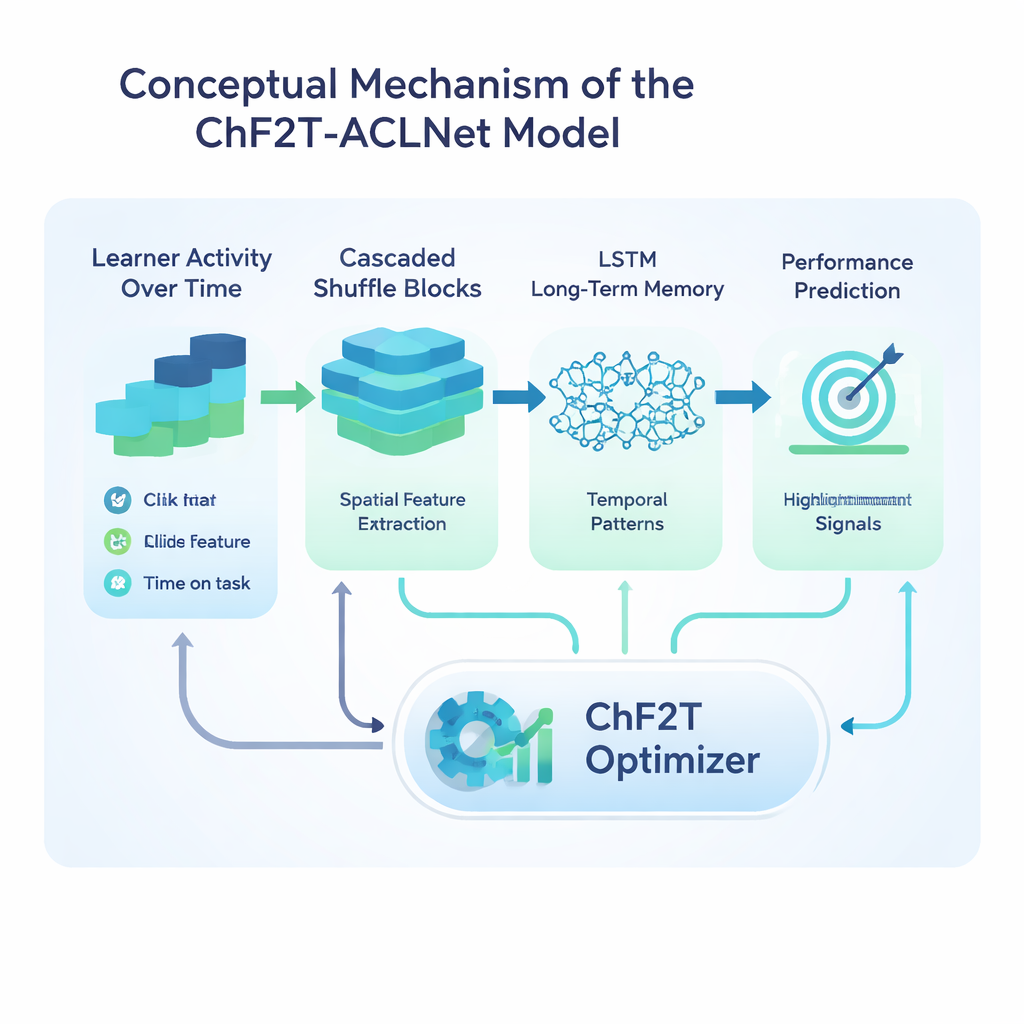
Studien kärna är en hybrid djuplärandemodell kallad ACLNet, tillsammans med en okonventionell träningsstrategi inspirerad av lagsport. ACLNet använder först lätta ”shuffle”‑block för att komprimera och blanda insignaler effektivt, och skickar dem sedan in i en minnesmodul som spårar hur en deltagares beteende förändras över tid. Ett uppmärksamhetslager ovanpå framhäver de mest inflytelserika kanalerna—som plötsliga aktivitetsfall eller konsekvent höga quizpoäng—innan en slutlig förutsägelse av deltagares prestationsklass görs. För att ställa in nätverkets många interna parametrar introducerar författarna en Chaotic Football Team Training (ChF2T)‑algoritm. Här utforskar virtuella ”spelare” olika parameterinställningar, imiterar starka presterare, undviker svaga och gör ibland stora, kaotiska hopp som hjälper sökningen att undkomma dåliga lokala lösningar. Denna blandning av struktur och kontrollerad slump förbättrar konvergenshastigheten och minskar överanpassning.
Hur väl systemet presterar i praktiken
Forskarlaget testar sin pipeline på ett syntetiskt men realistiskt dataset med 1 200 it‑yrkespersoner, utformat för att spegla verkliga lärplattformsregister med medvetet ojämna klassfördelningar. De jämför sin ChF2T‑ACLNet‑modell mot flera starka baslinjer, inklusive federerade lärandeupplägg, avancerade bildliknande nätverk anpassade till utbildning och andra djupa eller ensemblemodeller. I flera korsvalideringsupplägg når den föreslagna metoden omkring 98,9 % noggrannhet, med liknande höga värden för precision, recall och F‑poäng. Den uppnår också ett nästan perfekt överensstämmelsetal som korrigerar för slump och levererar starka area‑under‑curve‑värden, vilket innebär att den skiljer prestationsnivåer på ett pålitligt sätt över många trösklar. Trots sin komplexitet körs systemet snabbare än konkurrerande tillvägagångssätt, tack vare noggrann funktionsselektion, en effektiv nätverksdesign och optimizerens snabba konvergens.
Vad detta betyder för vardagligt onlinelärande
Enkelt uttryckt visar detta arbete att det är möjligt att följa hur yrkespersoner tar sig igenom nätkurser och med hög säkerhet avgöra vem som har svårt, vem som flyter med och vem som behärskar materialet—utan att vänta på ett slutprov. Ett sådant system skulle kunna trigga tidiga tips, rekommendera andra övningar eller varna handledare långt innan en deltagare halkar efter. Författarna noterar kvarstående utmaningar, inklusive att skala till mycket stora plattformar, anpassa sig till snabbt föränderliga kursdesigner och göra modellens beslut lättare att förklara. Ändå är deras tillvägagångssätt ett viktigt steg mot e‑lärandesystem som beter sig mer som uppmärksamma personliga coacher än statiska digitala läroböcker.
Citering: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Nyckelord: adaptivt e‑lärande, lärandeanalys, djuplärande, utbildning för IT‑yrkespersoner, förutsägelse av studentprestation