Clear Sky Science · sv
Semantisk medveten felsökning av tungt järnvägsunderhållsfordon och dess potential i multisensorfusionssystem
Hålla spårreparationer på rätt spår
Bakom varje jämn tågresa står en flotta av tunga maskiner som inspekterar, lyfter, packar och räfflar spåren. När dessa komplexa fordon fallerar kan förseningar och säkerhetsrisker följa. Denna artikel undersöker ett nytt sätt att diagnostisera fel i sådan utrustning genom att lära datorer att inte bara läsa numeriska sensordata, som vibration eller temperatur, utan också att ”förstå” de ord mekaniker skriver i underhållsloggar. Genom att minska klyftan mellan siffror och språk pekar arbetet mot smartare, mer tillförlitligt järnvägsunderhåll.
Varför maskiner fortfarande behöver mänskliga ord
Moderna spårunderhållsmaskiner är fulla av sensorer som övervakar ström, tryck, hastighet och mycket mer. Genom att kombinera dessa mätvärden kan ingenjörer skaffa sig en detaljerad bild av en maskins fysiska tillstånd. Ändå saknar denna bild något viktigt: betydelse. En topp i vibration kan antyda ett slitet lager eller en lös bult, men sensorn i sig kan inte säga vilket. I praktiken fyller personal i frontlinjen denna lucka genom att dokumentera symptom som ”onormalt ljud” eller ”trög drift” och notera orsaker och åtgärder i skriftliga loggar. Dessa beskrivningar fångar år av erfarenhet, men de är ostrukturerade och svåra för datorer att använda, så de flesta diagnossystem ignorerar dem.
Göra text till en ny typ av sensor
Författarna föreslår att behandla underhållsloggar som en slags ”virtuell semantisk sensor”—en mjukvarumodul som omvandlar meningar till standardiserade signaler, ungefär som en temperatursensor ger grader. Deras målmaskiner är stora, flersystemiska spårunderhållsfordon, inklusive centrala styrenheter, kraft- och bromssystem, rörelsesystem och hjälpsystem. För varje felpost samlar de korta texter som beskriver var felet inträffade, vad som observerades, varför det hände och hur det åtgärdades. Dessa texter, även om de är korta och ibland tvetydiga, innehåller viktiga ledtrådar som kompletterar signalerna från fysiska sensorer.
Hur den virtuella semantiska sensorn fungerar
För att omvandla ord till användbara signaler bygger forskarna en flerskiktsmodell som kombinerar flera framsteg från naturlig språkbehandling och djupinlärning. Först använder de BERT, en vida använd språklig modell, för att konvertera varje kinesisk felbeskrivning till rika numeriska vektorer som fångar kontext och ordens betydelse. Därefter passerar dessa vektorer genom ett konvolutionsneuronätverk (CNN), vilket är särskilt bra på att upptäcka lokala mönster och korta fraser som avslöjar feltyper. Ovanpå detta introducerar de en dubbel självuppmärksamhetsmekanism som hjälper modellen att fokusera på de mest informativa orden och funktionsmönstren—termer som ”oljepumpsfel” eller ”tryckförlust”—snarare än att behandla varje token lika. Tillsammans bildar dessa komponenter BERT-DSA-CNN-modellen, vars slutliga högdimensionella output fyller två roller: den förutsäger vilket system som felar och ger en kompakt semantisk funktionsvektor som senare kan slås samman med fysiska sensordata.
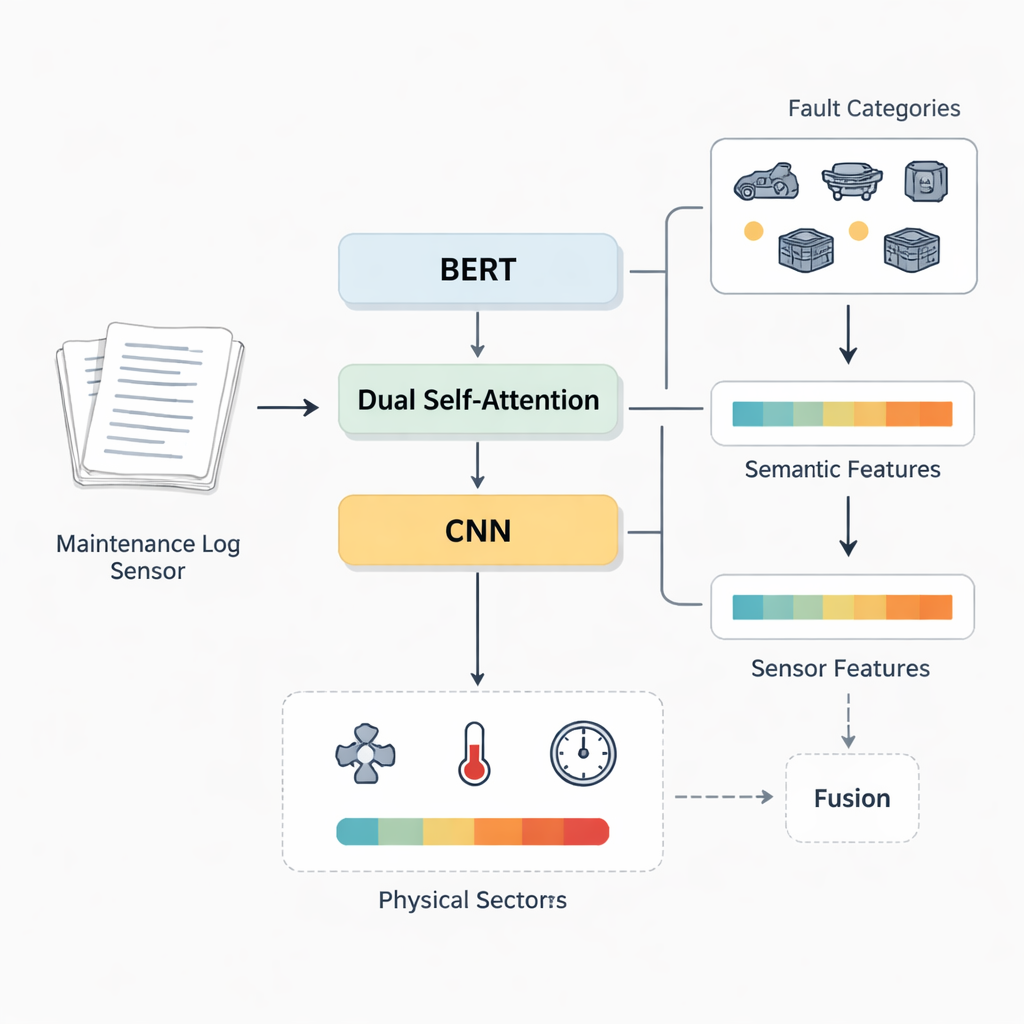
Sätta metoden på prov
Teamet utvärderar sitt tillvägagångssätt med hjälp av felloggar från 2023 till 2025 för en viss typ av tung underhållsmaskin, som täcker sju större felsystem såsom kraftöverföring, löpverk, bromsar och packningsanordningar. Eftersom vissa system fallerar oftare än andra använder de dataaugmentering—omsorgsfull omskrivning och back-translation—för att balansera träningsuppsättningen samtidigt som testuppsättningen lämnas orörd. De jämför därefter sin föreslagna modell med flera alternativ: enklare CNN utan uppmärksamhet, en BERT plus återkommande nätverk, klassiska ordinbäddningsmodeller och en traditionell support vector machine som använder bag-of-words-statistik. Vad gäller noggrannhet, precision, recall och F1-poäng presterar BERT-DSA-CNN konsekvent bäst, ofta över 97 % F1-poäng över felsystemen, och överträffar tydligt äldre maskininlärningsmetoder.
Vad resultaten avslöjar om språk och fel
Bortom rubriksiffrorna undersöker författarna hur uppmärksamhetsmekanismen beter sig. De finner att modellen naturligt lyfter fram ord som namnger nyckelkomponenter och symptom, i ekon av hur en mänsklig expert skulle läsa en felrapport. Felklassificeringar tenderar att uppstå när beskrivningarna är vaga eller när olika system delar liknande yttre symptom, som ”överdriven vibration” som förekommer både i kraftöverföring och löpsystem. Detta mönster understryker både löftet och begränsningarna med enbart text: språk bär rik kontext, men kan sudda ut gränser när olika fel ser lika ut på ytan.
Från smartare textläsning till smartare järnvägar
I vardagliga termer visar denna studie att lära datorer att läsa mekanikerns anteckningar kan göra felsökningen för spårunderhållsmaskiner mer exakt och tolkbar. Den föreslagna modellen omvandlar pålitligt korta, röriga felbeskrivningar till rena numeriska kännetecken som beter sig som en ny sensorsignal. Medan artikeln inte går så långt som att faktiskt slå samman dessa semantiska funktioner med realtidsdata från fysiska sensorer, lägger den grunden för sådan fusion. I framtida system kan mätvärden från vibrations- och temperatursensorer kombineras med den ”virtuella sensorn” härledd från text, vilket ger underhållsteamen tidigare varningar, klarare förklaringar och i förlängningen säkrare och mer punktliga tågtrafik.
Citering: Zhang, Y., Gao, C., Wang, R. et al. Semantic-aware fault diagnosis of heavy-duty railway maintenance machinery and its potential in multisensor fusion systems. Sci Rep 16, 6436 (2026). https://doi.org/10.1038/s41598-026-36456-8
Nyckelord: järnvägsunderhåll, felsökning, underhållsloggar, multisensorfusion, BERT