Clear Sky Science · sv
Integritetsmedveten segmentering av djup ventrombos med en multimodell-federerad inlärningsram och federated averaging-algoritmen
Varför blodproppar och dataintegritet spelar roll
Blodproppar som bildas djupt i benens vener, kända som djup ventrombos (DVT), kan tyst färdas till lungorna och orsaka livshotande tillstånd. CT-skanningar kan avslöja dessa proppar, men att omvandla tusentals gråskalebilder till tillförlitliga automatiska upptäckter är en svår uppgift för datorer. Samtidigt är sjukhus med rätta försiktiga med att dela känsliga patientdata. Denna studie undersöker hur flera sjukhus kan samarbeta för att träna ett kraftfullt AI-system för att hitta proppar—utan att någonsin slå samman eller exponera sina råa patientskanningar.
Dela hjärnor, inte kroppar
Kärnan i arbetet är en teknik som kallas federated learning, vilken låter flera institutioner träna AI-modeller gemensamt samtidigt som deras data stannar lokalt. Istället för att skicka CT-bilder till en central server tränar varje sjukhus sin egen lokala modell på sina egna skanningar. Endast modellens inlärda parametrar—i praktiken vad den har "förstått" om att känna igen proppar—skickas till en central server. Där kombinerar en metod kallad federated averaging dessa olika uppsättningar parametrar till en enda förbättrad global modell, som sedan skickas tillbaka till alla sjukhus. På så sätt får varje plats nytta av det kollektiva kunnandet från alla deltagare, samtidigt som ingen patientbild någonsin lämnar sitt ursprungliga sjukhus. 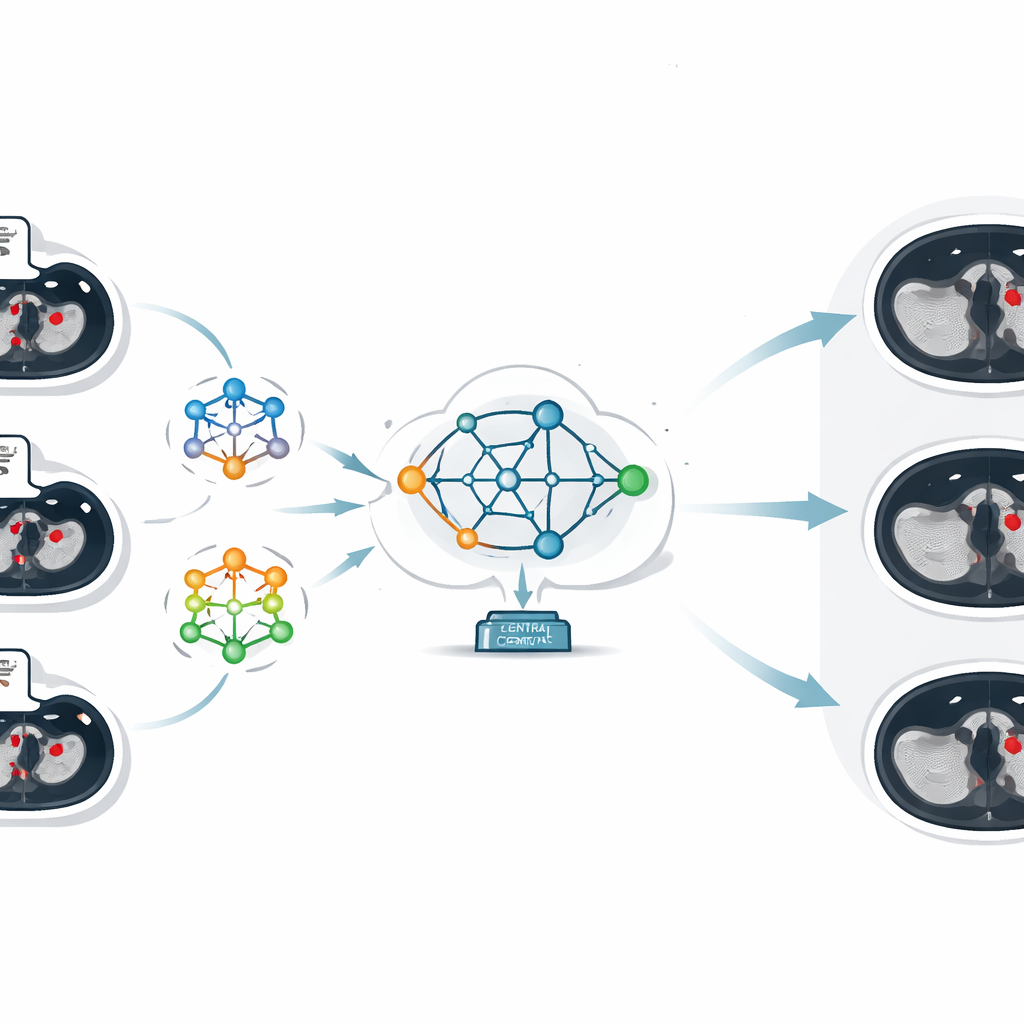
Många AI-stilar som ser samma vener
En viktig innovation i denna studie är att forskarna inte förlitade sig på bara en typ av neuralt nätverk. De satte samman sju olika modellkonstruktioner, var och en bra på att se olika aspekter av CT-bilderna. Enklare modeller, såsom grundläggande konvolutionsnät och sekventiella modeller, är snabbare och lättare att köra på begränsad hårdvara. Mer avancerade arkitekturer, inklusive U‑Net, VGG‑19 och två specialanpassade nätverk med residual-, inception-, attention- och flerskaliga bearbetningsblock, är bättre på att följa fina kärlkanter, upptäcka små proppar och hantera brusiga bilder. Genom att låta varje sjukhus använda den modell som bäst matchar dess data och beräkningskraft speglar systemet den röriga verkligheten i kliniska miljöer istället för att anta att alla platser är likadana.
Lärande från ojämna och ofullständiga data
I medicin ser data från ett sjukhus sällan exakt likadana ut som från ett annat. Skannersystem, avbildningsprotokoll och patientpopulationer skiljer sig åt, så studien arbetade medvetet med "non‑IID"-data—samlingar som är ojämna och inte identiskt fördelade. Detta gör normalt träningen mer instabil. Här omfamnade författarna den mångfalden och visade att kunskapsdelning över flera olika modeller faktiskt förbättrade den globala systemets generaliseringsförmåga. De körde tre experimentella faser, först med tre klienter, sedan fem och slutligen sju, med dataset om 1 000, 2 000 respektive 3 000 CT-bilder. Vid varje steg följde de inte bara hur ofta den globala modellen korrekt segmenterade proppar, utan också hur mycket kommunikation som krävdes, hur lång träningen tog, hur olika varje klients data var och hur väl integritetsskyddet fungerade.
Bättre upptäckt av proppar—till en beräkningskostnad
I samtliga faser överträffade den kombinerade globala modellen konsekvent varje enskild lokal modell. När antalet bilder växte och mer sofistikerade modeller anslöt sig till federation ökade segmenteringsnoggrannheten från cirka 91 % till över 96 %, och ett balanserat kvalitetsmått kallat F1‑score steg från ungefär 0,89 till 0,95. Samtidigt sjönk ett felinriktat förlustmått med mer än hälften, vilket signalerar renare och mer tillförlitliga proppkonturer. Dessa förbättringar kom inte gratis: kommunikationen mellan klienter och server ökade från några tiotal megabyte till flera gigabyte, och genomsnittlig träningstid gick från sekunder till många timmar i takt med att arkitekturerna blev mer komplexa. Ändå upprätthöll systemet en stark formell integritetsgaranti, vilket indikerar att de delade uppdateringarna läcker mycket lite information om någon enskild patient. 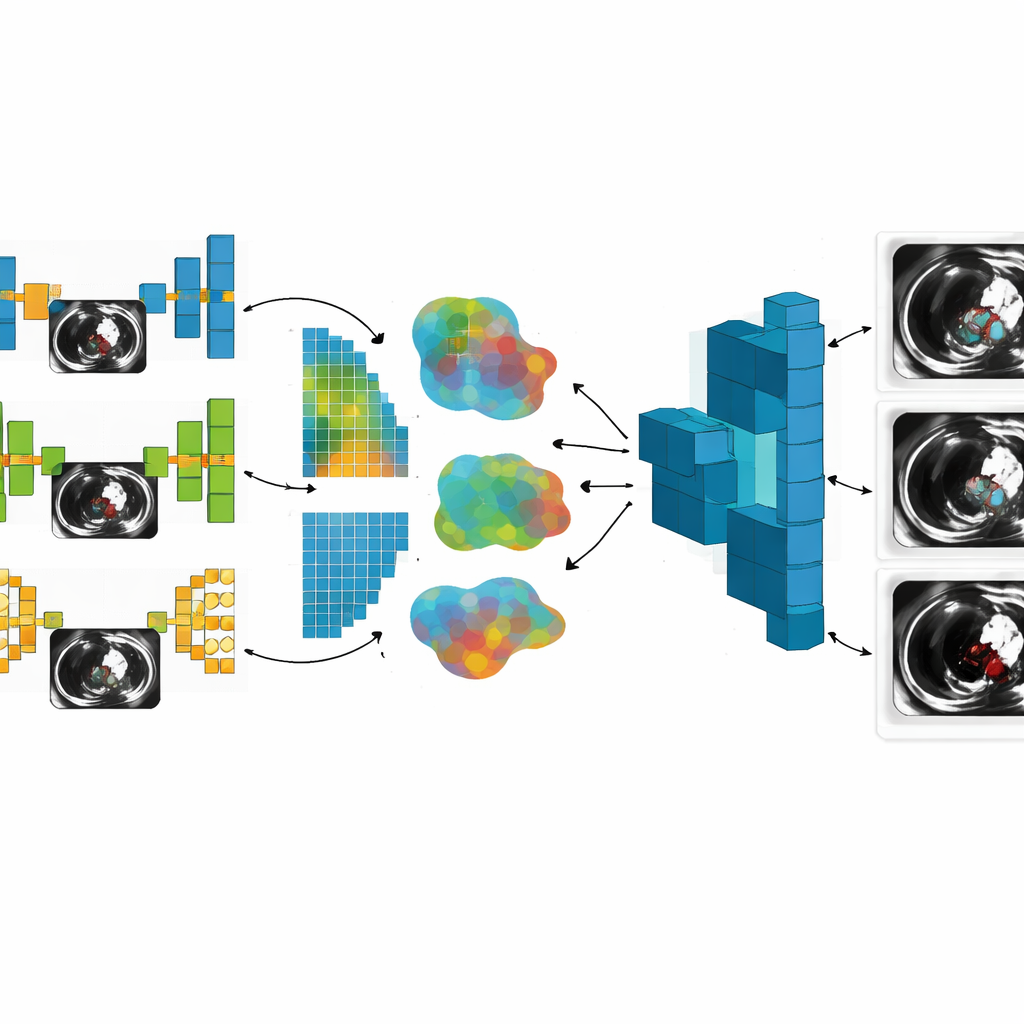
Vad detta betyder för patienter och sjukhus
För en lekman är slutsatsen att detta arbete visar hur sjukhus kan lära en gemensam AI att upptäcka farliga blodproppar mer träffsäkert, utan att överlämna kontrollen över sina känsliga data. Genom att kombinera flera kompletterande modelltyper och noggrant aggregera vad varje modell lär sig bygger författarna ett proppsegmenteringssystem som både är kraftfullt och respektfullt mot integriteten. Även om metoden kräver betydande beräkningsresurser och nätverksbandbredd pekar den mot en framtid där medicinska center rutinmässigt samarbetar kring smartare diagnostiska verktyg, förbättrar vården för patienter med risk för DVT och närliggande tillstånd samtidigt som deras personliga skanningar hålls säkert bakom institutionella väggar.
Citering: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
Nyckelord: djup ventrombos, federated learning, medicinsk bildsegmentering, integritetsbevarande AI, CT-avbildning