Clear Sky Science · sv
En metod för namndisemantisering i korta texter baserad på BERT‑modell och kortaste‑vägen‑algoritm
Varför det spelar roll att reda ut förvirrande namn
Varje dag söker, bläddrar och chattar vi med korta, ofta röriga textstycken—tweets, sökfrågor, chattmeddelanden. Dessa utdrag innehåller namn på personer, platser, företag och föremål som kan ha flera betydelser, som ”Apple” frukten eller ”Apple” företaget. Datorer måste avgöra vilken betydelse vi avser, och när de gissar fel blir sökresultat, rekommendationer och onlinetjänster betydligt mindre användbara. Denna artikel presenterar ett nytt sätt att hjälpa maskiner att korrekt tolka sådana tvetydiga namn i korta texter, särskilt i kinesiska sociala medier och sök, genom att kombinera moderna språkmodeller med en smart grafalgoritm.
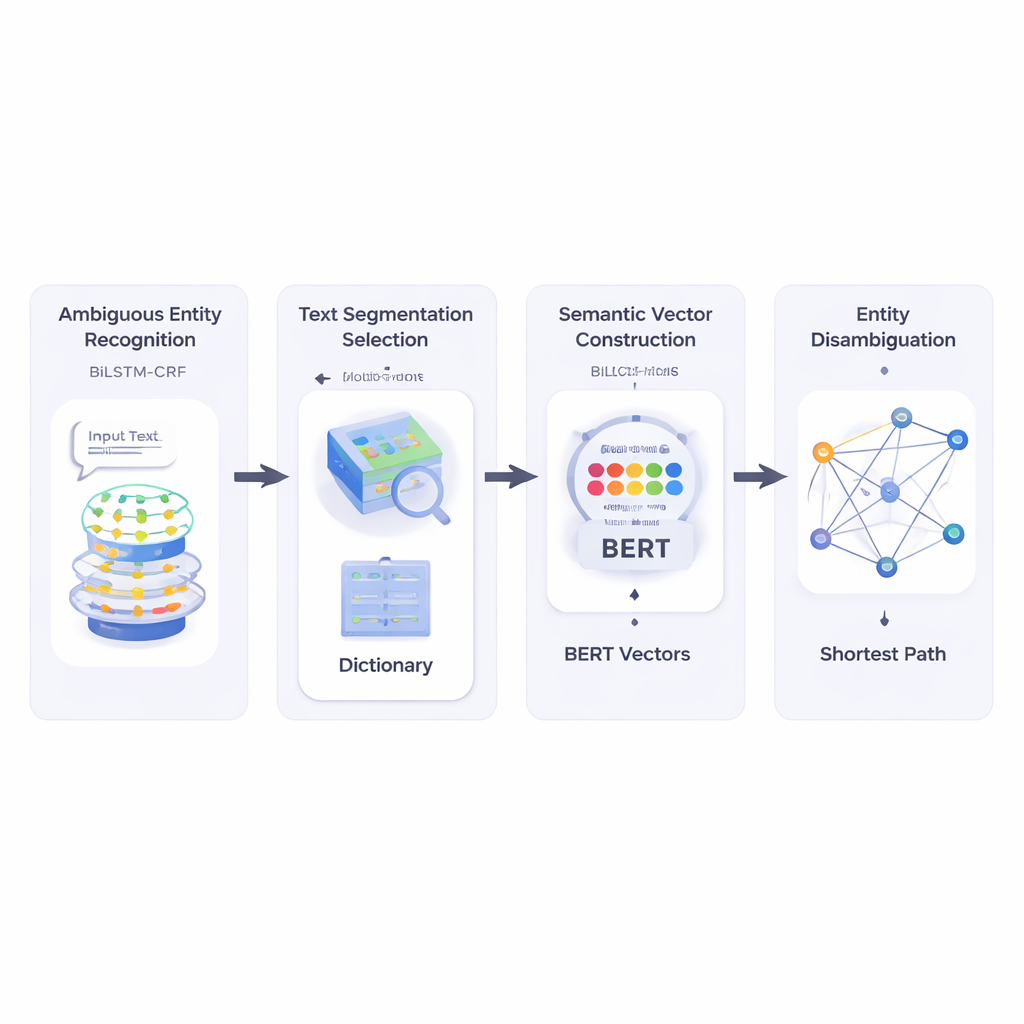
Från röriga korta texter till klara mål
Korta texter är förvånansvärt svåra för datorer att förstå. Till skillnad från långa artiklar innehåller de mycket lite kontext och är fulla av slang, förkortningar och ofullständiga meningar. Traditionella metoder försökte matcha ett namn i texten med poster i en kunskapsbas eller använde handgjorda regler och enklare maskininlärningsmodeller. Dessa angreppssätt tenderar att behandla varje ord som att det har en enda fast betydelse, vilket misslyckas när samma ord kan beteckna en yrkestitel, ett företag eller en låt beroende på användningen. Resultatet blir frekvent förvirring kring vilken faktisk enhet ett ord i en tweet eller fråga syftar på.
Lära systemet att upptäcka tvetydiga namn
Författarna bygger först ett system som läser en kort text och identifierar vilka delar som är entitetsnamn och vilka av dessa som kan vara tvetydiga. De använder en neuralt nätverkskombination kallad BiLSTM‑CRF, som är bra på att tagga ordsekvenser genom att titta på både vänster och höger kontext. När potentiella entiteter är markerade konsulterar systemet en stor lexikal resurs kallad HowNet. Om HowNet listar flera betydelser för ett ord flaggas ordet som tvetydigt; om det bara finns en betydelse behandlas ordet som redan klart. Detta steg ger systemet en fokuserad lista av namn som verkligen behöver disambiguering.
Göra betydelser till punkter i ett rum
Nästa steg bryter metoden ned den korta texten i kandidatordsegment och väljer den bästa segmenteringen genom att kontrollera hur väl varje möjlig uppdelning överensstämmer i betydelse med klart förstådda referensord i samma mening. För att mäta detta förlitar sig författarna på BERT, en kraftfull förtränad språkmodell som producerar en numerisk ”semantisk vektor” för varje ordanvändning och fångar dess kontextberoende betydelse. Genom att beräkna cosinuslikheten mellan dessa vektorer hittar systemet den segmentering vars delar är mest semantiskt kompatibla med de entydiga referenstermerna. Detta gör det möjligt för modellen att representera varje möjlig betydelse av varje ord som en punkt i ett flerdimensionellt rum.
Hitta den kortaste vägen till rätt betydelse
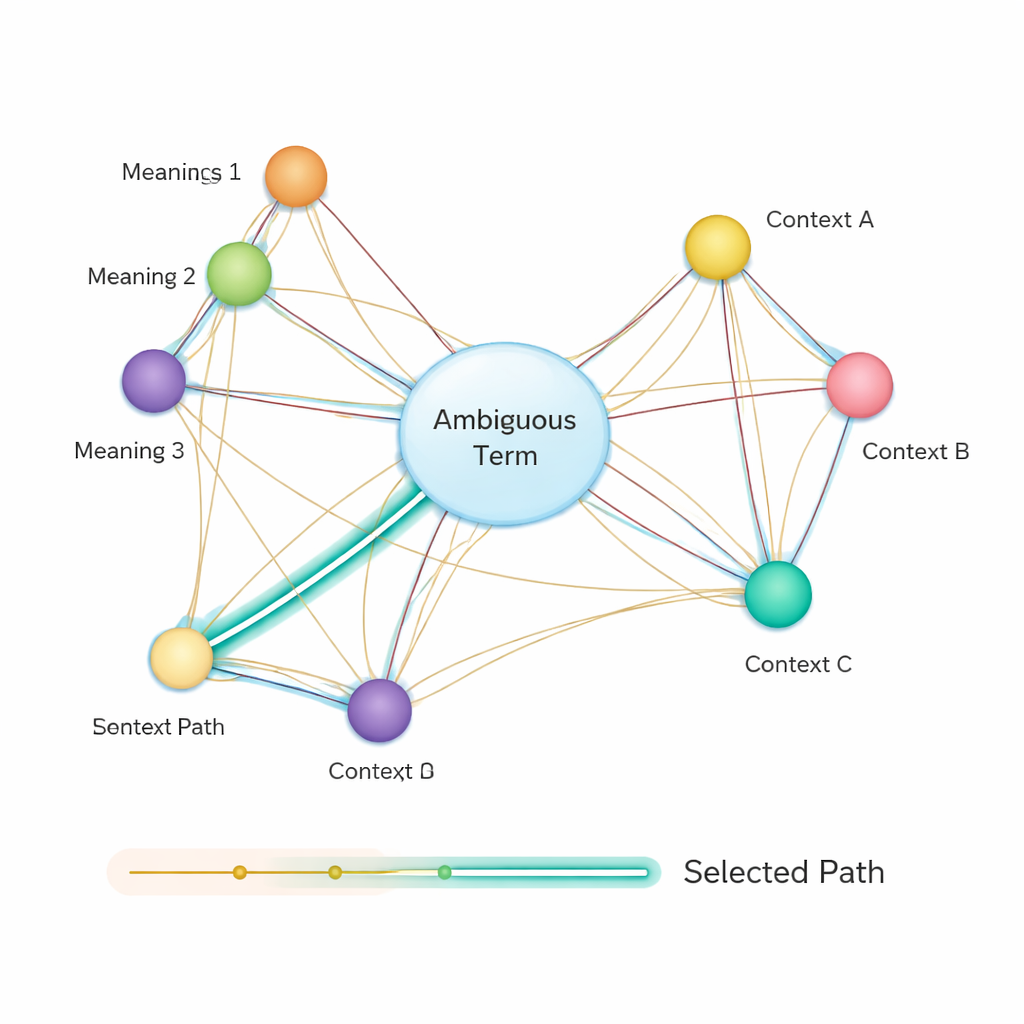
Därefter bygger metoden ett semantiskt nätverk: en graf där varje möjlig betydelse av varje term är en nod och kanter förbinder betydelser som kan förekomma tillsammans i samma mening. Styrkan i varje kant baseras på hur lika betydelserna är, återigen med hjälp av BERT‑baserade vektorer. För att avgöra vilken betydelse av ett tvetydigt ord som bäst passar meningen tillämpar författarna en klassisk algoritm känd som Dijkstras kortaste‑vägen‑algoritm. Intuitivt söker systemet efter den väg genom betydelsegrafen som håller den övergripande semantiska ”sträckan” så liten som möjligt. Den valda vägen motsvarar en konsekvent tolkning av alla termer, och den betydelse av den tvetydiga entiteten som ligger på denna väg väljs som slutgiltigt svar.
Hur mycket bättre fungerar detta?
Forskningen testade sin metod på en offentlig kinesisk dataset från CLUE‑benchmarken, som simulerar verkliga korttextsscenarier såsom inlägg i sociala medier och sökfrågor. De jämförde fyra angreppssätt: versioner som använder traditionella Word2Vec‑inbäddningar, språkmotorn ELMo, ett BERT‑baserat system utan kortaste‑vägen‑steget och deras kompletta BiLSTM‑CRF‑BERT‑SPA‑pipeline. Över tusentals texter förbättrade deras fullständiga metod noggrannhet, återkallning och F1‑poäng med ungefär en fjärdedel i genomsnitt jämfört med de andra. I praktiska termer var systemet både bättre på att hitta rätt entiteter och mer konsekvent över många olika datamängder.
Vad detta innebär för vardaglig teknik
För icke‑specialister är slutsatsen enkel: genom att kombinera en kraftfull språkförståelsemodell (BERT) med en grafbaserad kortaste‑vägen‑sökning ger författarna datorer ett mer tillförlitligt sätt att avgöra vad ett tvetydigt namn egentligen syftar på i korta, brusiga texter. Detta kan göra sökmotorer smartare, hjälpa sociala plattformar att bättre förstå inlägg och förbättra efterföljande verktyg som rekommendationssystem och kunskapsgrafer. Medan metoden för närvarande är inriktad på kinesiska och fortfarande har utrymme för effektivitetsförbättringar, visar den hur blandningen av modern AI och klassiska algoritmer kraftigt kan minska förvirring i hur maskiner tolkar vårt vardagliga språk.
Citering: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Nyckelord: namndisemantisering, kort text, BERT, kunskapsgraf, bearbetning av naturligt språk