Clear Sky Science · sv
Innehålls- och stilseparation för flerstilbildsgenerering med latent diffusion-arkitektur
Varför smartare bildstilar spelar roll
Från filmposters och spelkonst till filter i sociala medier förväntar vi oss i allt högre grad att bilder både är visuellt iögonfallande och starkt personliga. Men bakom kulisserna har många stilöverföringssystem fortfarande svårigheter: de kan förvränga en persons ansikte, böja byggnader, eller kräva tung hårdvara. Denna artikel presenterar en ny AI-modell som lovar rikare konstnärliga stilar samtidigt som originalbilden bevaras och modellen körs effektivt nog för vardagliga enheter.
Att skilja på "vad det är" och "hur det ser ut"
I kärnan av detta arbete finns en modell kallad Dual-Condition Lightweight Style Diffusion Model (DCLSDM). Huvudidén är att behandla bildens substans—objekten, layouten och scenen—som en "kanal", och den konstnärliga behandlingen—färger, texturer, penseldrag—som en annan, och att styra dem separat. Istället för att låta ett enda nätverk blanda ihop dessa två aspekter använder DCLSDM två dedikerade vägar: en för innehåll och en för stil. Innehållsvägen fokuserar på att förstå former och betydelser i en ingångsbild eller textbeskrivning, medan stilvägen fokuserar på att lära sig det visuella uttrycket hos ett valt konstverk eller en stildescription.
Hur den nya modellen är uppbyggd
DCLSDM bygger på diffusionsmodeller, samma familj tekniker som ligger bakom många moderna bildgeneratorer. Istället för att arbeta direkt på bilder i full upplösning verkar den i ett komprimerat "latent"-utrymme, vilket är mycket mer effektivt. En modul kallad Perceiver IO extraherar innehållet: den tar in en bild eller bildtext och destillerar scenens geometri och semantik till en kompakt representation. En separat stilmodul läser en eller flera stilbilder eller texter och konverterar dem till stilfeature-vektorer. Dessa stilfunktioner kan blandas med ett viktat interpoleringsschema, vilket möjliggör mjuka övergångar mellan till exempel en impressionistisk och en minimalistisk estetik utan den vanliga "grumliga" medelvärdeseffekten.
Bevara struktur samtidigt som stilen ändras
Inuti diffusionsnätverket som faktiskt genererar bilden injiceras de två informationsslagen genom oberoende vägar. Innehållssignaler styr nätverkslager som ansvarar för struktur—var kanter, objekt och layouter ska placeras. Stilsignaler injiceras genom dedikerade attentionlager som främst formar texturer, färger och penselföring. Ovanpå detta lägger en komponent kallad ControlNet till extra strukturell vägledning med hjälp av kant- eller djupkartor som extraherats från originalinnehållet. Denna kombination gör att systemet kan återmåla ett sommarlanskap i en vinterpalett, eller återge ett fotografi som en Van Gogh-liknande målning, samtidigt som berg, träd och byggnader behålls på rätt plats och utan förvrängning.
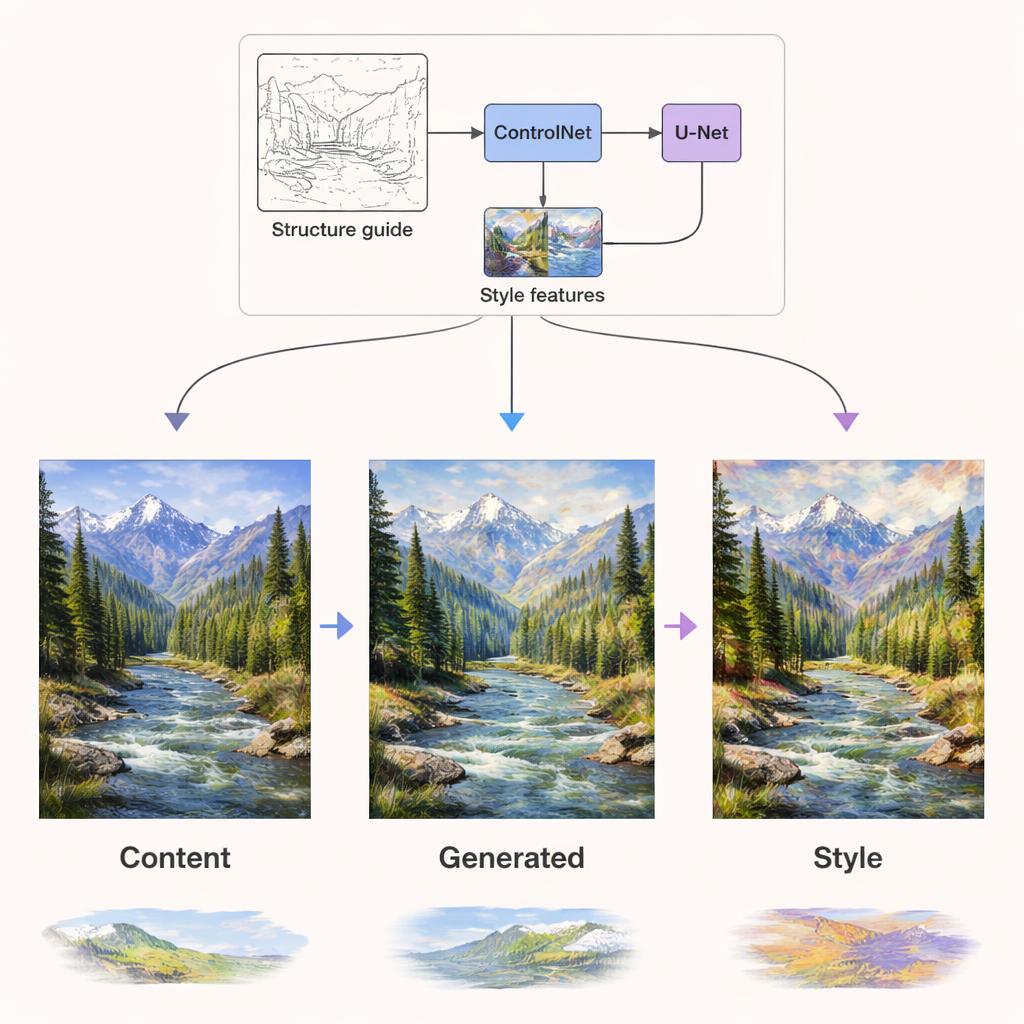
Bättre kvalitet, fler stilar, mindre beräkning
Författarna testar DCLSDM rigoröst på två publika dataset: WikiArt, som täcker dussintals konstnärliga rörelser, och Summer2Winter Yosemite, som fokuserar på årstidsvariationer i ett landskap. De jämför sin modell mot en rad toppmoderna system som används inom både forskning och industri. Över mått för strukturell likhet, upplevd visuell kvalitet och hur nära de genererade bilderna liknar verkliga konstverk får DCLSDM konsekvent högst poäng. Den körs också snabbare, använder mindre minne och har färre parametrar än många konkurrenter, samtidigt som den erbjuder flexibel blandning av flera stilar och stödjer både bildbaserat och textbaserat stilinmatning.
Vad detta betyder för vardaglig kreativitet
I praktiken visar detta arbete att det är möjligt att ge användare finmaskig kontroll över hur en bild ser ut utan att offra vad bilden visar—och att göra det på mer blygsam hårdvara. Formgivare kan snabbt utforska många konstnärliga behandlingar av samma layout, mobilappar kan erbjuda rikare filter som inte deformera ansikten eller scener, och kulturarvsprojekt kan omstyla gamla fotografier samtidigt som viktiga strukturella detaljer bevaras. Genom att tydligt separera innehåll från stil inom en modern diffusionsram pekar DCLSDM mot en framtid där kreativa bildverktyg är både kraftfullare och mer pålitliga för vardagligt bruk.
Citering: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Nyckelord: bildstilöverföring, diffusionsmodeller, innehåll-stil-separation, digital konstgenerering, effektiv bildgenerering