Clear Sky Science · sv
Förstärkningsinlärningsramverk för datoriserad adaptiv provning med multi-armed bandit-metod
Smarare prov för den digitala klassrummet
Alla som har suttit igenom ett långt, likadant prov för alla vet hur tråkigt och orättvist det kan kännas. Vissa frågor är alldeles för enkla, andra omöjligt svåra, och slutpoängen fångar kanske inte riktigt vad du kan. Den här artikeln presenterar ett nytt sätt att bygga datorbaserade prov som anpassar sig i realtid efter varje persons svar. Genom att låna idéer från modern artificiell intelligens vill författarna göra prov kortare, mer precisa och bättre anpassade till varje provdeltagares verkliga förmåga.
Varför fasta prov inte räcker till
Traditionella prov ger alla studenter samma uppsättning frågor. Det gör provkonstruktionen enkel, men det slösar med information: starka studenter får kämpa sig igenom många lätta uppgifter, medan svagare studenter snabbt blir överväldigade. Datoriserad adaptiv provning försöker åtgärda detta genom att välja nästa fråga utifrån tidigare svar, men de flesta nuvarande system förlitar sig fortfarande på decennier gamla statistiska modeller och handgjorda regler. Dessa äldre angreppssätt har svårt att fånga komplexa svarsmönster och kan ofta inte fullt ut ta hänsyn till de stora skillnaderna mellan elever i moderna, storskaliga onlinemiljöer.
Att föra in modern AI i provning
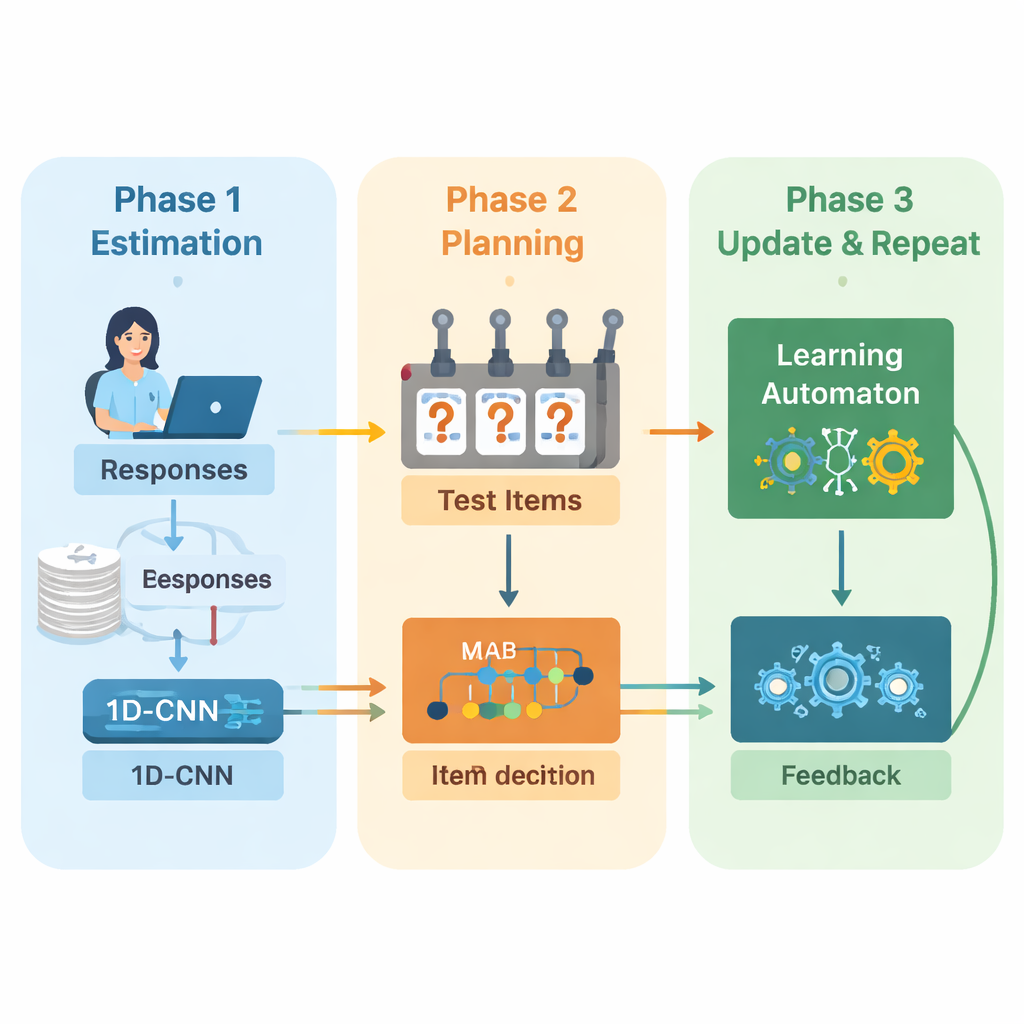
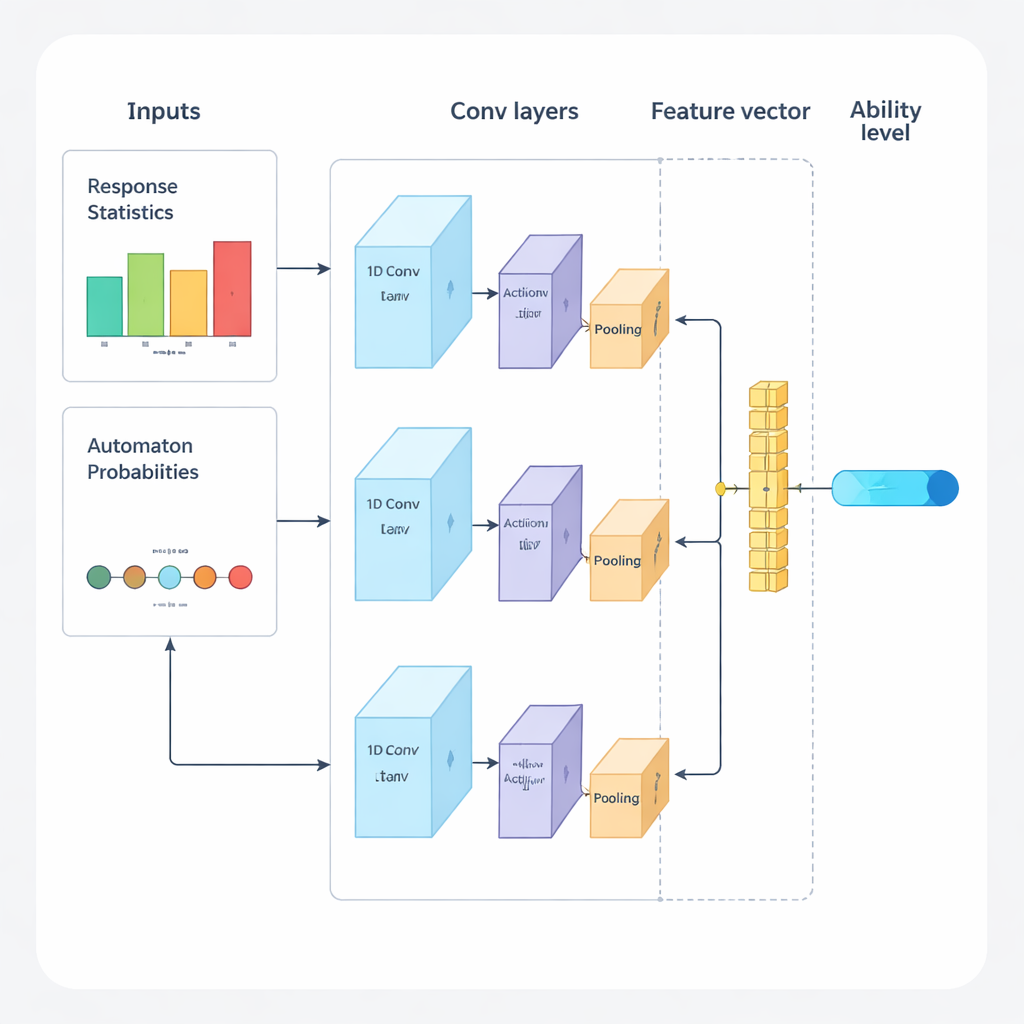
Författarna föreslår ett nytt ramverk som kombinerar djupinlärning och förstärkningsinlärning för att styra adaptiva prov från början till slut. Systemet arbetar i upprepade cykler. Först analyserar ett endimensionellt konvolutionellt neuralt nätverk (1D-CNN) en persons senaste svar, frågornas svårighet och andra sammanfattande statistiker. Ur denna datastream producerar det ett enda tal som representerar personens nuvarande färdighetsnivå på en normaliserad skala, liknande hur traditionella testteorier beskriver förmåga men inlärt direkt från data. Detta nätverk tränas för att känna igen subtila mönster, såsom stadig framgång på svårare frågor eller oväntade misstag på enklare.
Att välja rätt nästa fråga
När systemet har en uppdaterad förmågeuppfattning måste det bestämma vad som ska ställas för fråga härnäst. Här använder författarna en "multi-armed bandit"-strategi, ett klassiskt verktyg från beslutsteori där varje möjlig handling behandlas som att dra i spaken på en enarmad bandit. I detta sammanhang är varje fråga i objektbanken en arm. Algoritmen tittar på frågor vars svårighet ungefär matchar den nuvarande skattningen av förmåga och väljer sedan de som förväntas vara mest informativa. Den balanserar två mål: att få en bra svårighetsmatchning, så att svar varken blir för lätta eller för svåra, och att täcka så många olika innehållsområden som möjligt, så att provet inte ignorerar viktiga ämnen. En belöningspoäng som väger ihop dessa två mål styr urvalsprocessen.
Att lära av sina egna beslut
För att fortsätta förbättras under provets gång lägger systemet till en annan lärande komponent kallad en learning automaton. Denna modul övervakar hur den skattade förmågan förändras över omgångar och om personens noggrannhet förbättras eller försämras. Den justerar en liten uppsättning sannolikheter som summerar om modellen förväntar sig att förmågan kommer att öka, förbli densamma eller minska. Dessa sannolikheter matas sedan tillbaka som extra indata till det neurala nätverket i nästa omgång. På så vis lär sig provmotorn inte bara om eleven, utan också om sina egna tidigare beslut—den belönar trender som ledde till korrekta skattningar och straffar trender som inte gjorde det.
Hur bra fungerar det i praktiken?
Forskarlaget utvärderade sitt ramverk med en stor, flerspråkig provdatamängd och tusentals simulerade provdeltagare vars verkliga färdighetsnivåer var kända. De jämförde sitt angreppssätt med flera ledande adaptiva provmetoder. Över en rad fel- och korrelationsmått gav det nya systemet mer precisa skattningar av förmåga samtidigt som färre frågor krävdes. Dess fel—mätta med vanliga statistiska mått som root mean squared error och mean absolute error—var tydligt lägre än för konkurrerande metoder. Samtidigt fördelade det användningen av frågor jämnare över objektbanken, vilket minskade risken att vissa frågor blev överexponerade och läckte.
Vad detta betyder för framtida prov
I vardagstermer antyder detta arbete att framtida datorbaserade prov skulle kunna likna en skräddarsydd handledningssession mer än ett stelbent prov. Frågorna skulle snabbt nollställa sig kring rätt svårighetsnivå för varje person, täcka hela spannet av relevanta ämnen och avslutas när systemet är tryggt i sin bedömning—ofta med färre uppgifter än dagens prov. Även om metoden fortfarande är beroende av goda träningsdata och beräkningskraft, och hittills har prövats på en enda dataset, pekar den mot en ny generation av smartare, rättvisare och mer effektiva bedömningar som naturligt anpassar sig till individuella lärande.
Citering: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Nyckelord: datoriserad adaptiv provning, pedagogisk bedömning, djupinlärning, förstärkningsinlärning, multi-armed bandit