Clear Sky Science · sv
Identifiering av riskfaktorer för nöjesanläggningar i stor skala med mixture of experts och fusion av flera modeller
Varför nöjesparksäkerhet behöver smartare läsning
Varje år sätter sig hundratals miljoner människor i berg- och dalbanor, frifallstorn och snurrande attraktioner i förvissningen om att komplicerade maskiner och upptagna operatörer ska hålla dem säkra. I kulisserna producerar tillsynsmyndigheter och ingenjörer stora mängder rapporter, olycksregister och allmänna klagomål — men det mesta av denna information finns i textform och är svår att snabbt överse. Den här studien undersöker hur avancerad artificiell intelligens kan "läsa" dessa dokument i stor skala, upptäcka faromönster tidigare och ge myndigheter en tydligare bild av var nöjesattraktioner mest sannolikt kan fallera.
Från spridda rapporter till en enhetlig riskbild
Kina har nu mer än 25 000 stora nöjesattraktioner och över 700 miljoner besökare per år. Trots övergripande förbättringar i säkerheten inträffar fortfarande sällsynta men allvarliga olyckor, ofta efter att inspektioner missat tidiga varningssignaler dolda i tekniska beskrivningar eller användarklagomål. Författarna menar att traditionell tillsyn — baserad på periodiska manuella kontroller, expertbedömningar och underhållsloggar — är för långsam och subjektiv i en så snabbföränderlig miljö. De samlar in en stor, verklig textkorpus som inkluderar olycksrapporter, lagar och standarder, inspektions- och underhållsregister samt nätklagomål relaterade till nöjesanläggningar. Efter noggrann rensning och filtrering blir detta flerkälliga material råvaran för ett automatiserat, data-drivet riskövervakningssystem. 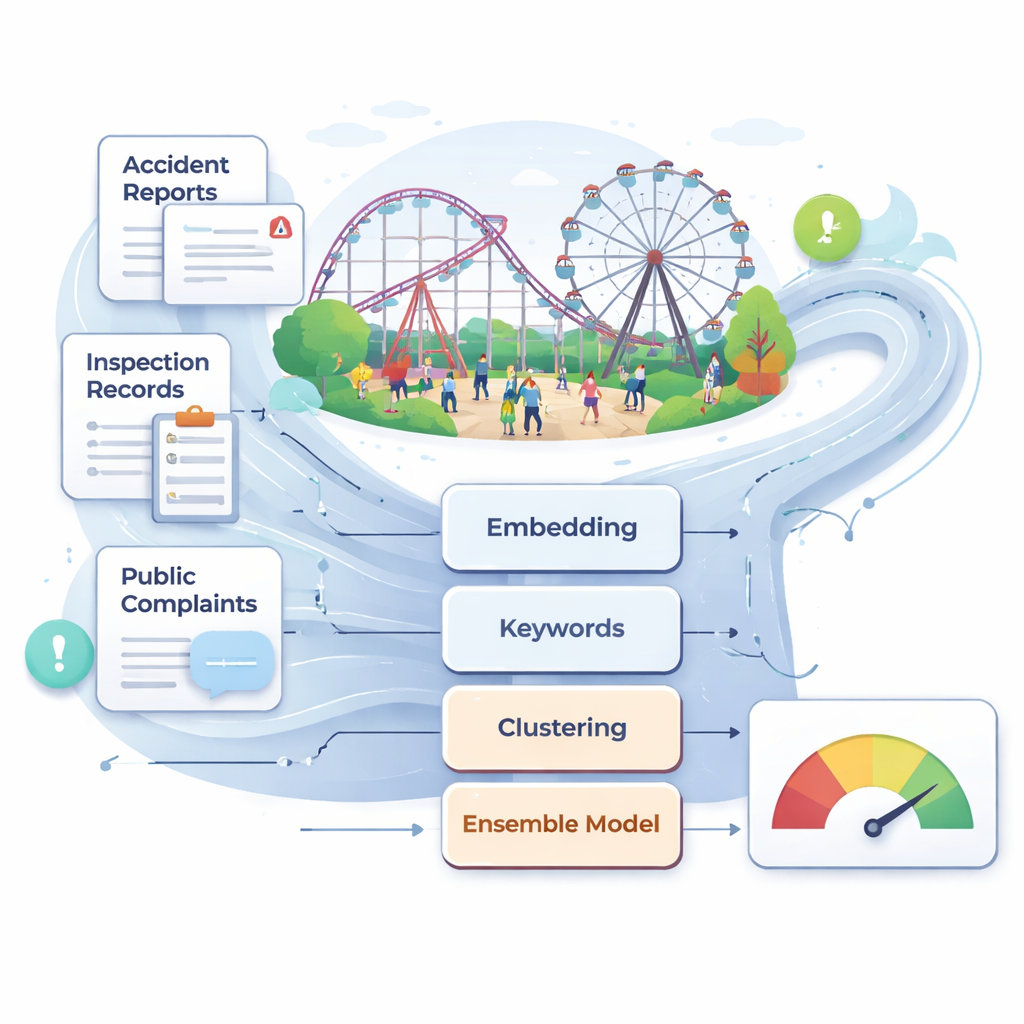
Att lära datorer förstå riskspråk
För att göra denna röriga text begriplig använder forskarna moderna språkmodeller som omvandlar meningar till numeriska vektorer som fångar deras innebörd. De använder huvudsakligen en kinesisk modell kallad BGE, som representerar varje textstycke som en 1 024-dimensionell punkt i rummet, samt en kompakt uppsättning om 30 nyckelordsbaserade funktioner inriktade på termer som "underhåll", "inspektion" och "åtgärdande". Denna dubbla blick — djup semantisk kontext plus handkuraterade riskfraser — hjälper systemet att skilja subtila skillnader mellan exempelvis rutinbesiktningar och allvarliga fel. Teamet experimenterar också med en annan toppmodern inbäddningsmodell, Qwen3, för att testa om byte av språkryggrad förbättrar prestanda; i praktiken visar sig BGE vara lite bättre för denna säkerhetsuppgift.
Finna dolda mönster och viktiga svaga punkter
Innan texterna klassificeras i konkreta riskkategorier använder författarna osupervisade metoder för att upptäcka naturliga grupptillhörigheter. De tillämpar k-means-klustring på inbäddningarna och använder en visualiseringsmetod kallad UMAP för att visa att rapporterna faller i flera tydliga ämneskluster. Därefter bygger de en semantisk graf där varje nod är ett säkerhetsrelaterat nyckelord och länkar indikerar stark samexistens och semantisk likhet. En community-detekteringsalgoritm grupperar dessa noder till kluster motsvarande breda teman såsom utrustnings- och struktursäkerhet, daglig drift och underhåll, nödlägen och ledning och tillsyn. Inom detta nätverk fungerar vissa ord — som "underhåll", "inspektion" och "ansvar" — som broar mellan klustren och belyser tvärgående svagheter som kan utlösa olyckor på flera sätt. Från denna struktur extraherar de 31 kärnriskfaktorer som spänner över fyra huvuddimensioner, från realtidsövervakning av utrustning till tydlighet i arbetsansvar. 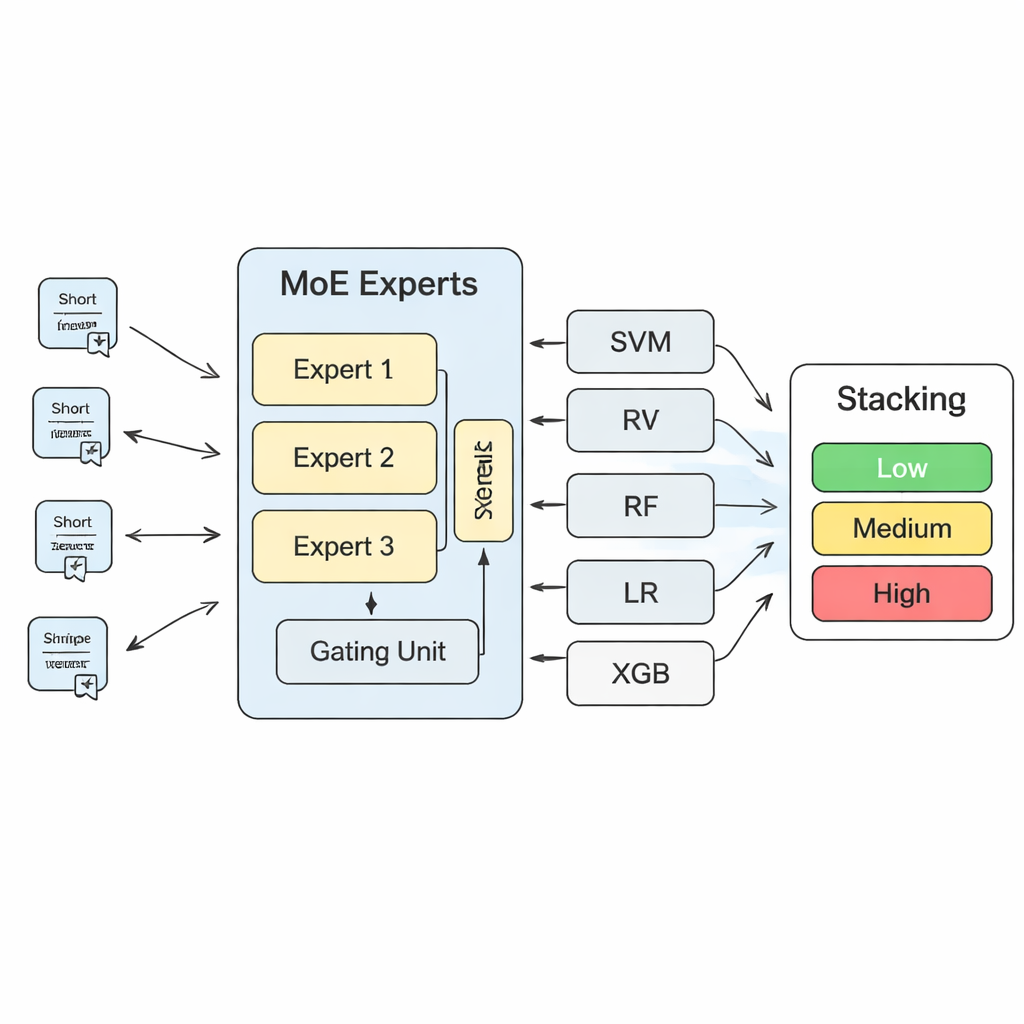
Att blanda många modeller till en starkare säkerhetsbedömare
För att omsätta dessa insikter till konkreta riskprediktioner bygger studien ett flerskiktat maskininlärningssystem. I dess centrum finns en "mixture of experts" (MoE)-modell: flera neurala nätverk, eller experter, lär sig var och en att specialisera sig på olika typer av riskmönster, medan en "gating"-komponent avgör vilka experter som är mest tillförlitliga för varje ny text. Utgångarna från denna MoE-modell kombineras sedan med prediktionerna från mer traditionella algoritmer, såsom support vector machines, random forests, logistisk regression och gradientförstärkta träd. Ett slutligt "Stacking"-lager — ytterligare en maskininlärningsmodell — lär sig hur man viktar dessa olika bedömningar för att nå ett slutgiltigt beslut. Genom omfattande korsvalidering finner författarna att användning av tre experter i MoE-lagret ger den bästa balansen mellan modellkapacitet och stabilitet.
Vad vinsterna betyder för verklig tillsyn
Jämfört med en enskild modell förbättrar MoE-plus-Stacking-systemet avsevärt noggrannhet, precision, recall och ett tillförlitlighetsmått kallat LogLoss. I praktiska termer innebär detta färre missade varningar och färre falsklarm vid granskning av stora volymer säkerhetstexter. Modellen kan köras på en vanlig arbetsstation och leverera snabba riskbedömningar för nya inspektionsrapporter eller klagomål, vilket gör den lämplig som ett beslutsstöd snarare än en ersättning för mänskligt omdöme. Författarna betonar att deras metod kan anpassas bortom nöjesattraktioner till annan specialutrustning som hissar eller linbanor. För en allmän publik är huvudslutsatsen att genom att lära datorer läsa säkerhetens språk — över tekniska dokument, föreskrifter och vardagliga klagomål — kan tillsynsmyndigheter upptäcka faromönster tidigare, styra inspektioner mer intelligent och göra en dag i parken lite säkrare för alla.
Citering: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Nyckelord: säkerhet för nöjesattraktioner, risktextanalys, maskininlärning, mixture of experts, övervakning av allmän säkerhet