Clear Sky Science · sv
Indikativ igenkänning i kinesiskt och ryskt diplomatisk diskurs med hjälp av stora språkmodeller
Att läsa mellan raderna
När diplomater talar offentligt kan det de inte säger vara lika viktigt som de ord de väljer. Denna studie undersöker om modern artificiell intelligens kan plocka upp subtila antydningar och förtäckta budskap i kinesiska och ryska utrikesministeriers presskonferenser—signaler som mänskliga åhörare ofta missar, men som kan påverka internationella relationer.
Varför antydningar spelar roll i världspolitiken
Diplomatiskt språk är utformat för att vara försiktigt och artigt. Regeringar behöver försvara sina intressen utan att öppet provocera rivaler eller väcka oro i allmänheten. Som en följd förlitar sig tjänstemän ofta på antydningar—fraser som på ytan låter neutrala men tyst kritiserar, varnar eller signalerar en politisk hållning. Att misstolka sådana antydningar har tidigare bidragit till kriser och misstro mellan stater. Att förstå dessa indirekta budskap är särskilt svårt över språk- och kulturgränser, där gemensam bakgrundskunskap inte kan tas för given.
Från klassisk teori till smarta maskiner
I årtionden har lingvister och filosofer studerat hur talare antyder mer än vad de bokstavligen säger. Tidiga teorier fokuserade huvudsakligen på talarens intentioner och antog att en rationell lyssnare kunde rekonstruera den dolda betydelsen. Senare arbete inom ”kognitiv pragmatik” betonade att förståelsen av antydningar också beror på lyssnarens mentala processer, kulturella bakgrund och den omgivande kontexten. Med utgångspunkt i dessa idéer beskriver författarna antydningar som lager: den synliga formuleringen (verbal–semantisk nivå), de kulturspecifika tankesätten bakom den (lingvistisk–kognitiv nivå) och talarens motiv och strategier, såsom kritik, varning eller att rädda ansiktet (motivations–pragmatisk nivå).
Hur AI-systemet byggdes
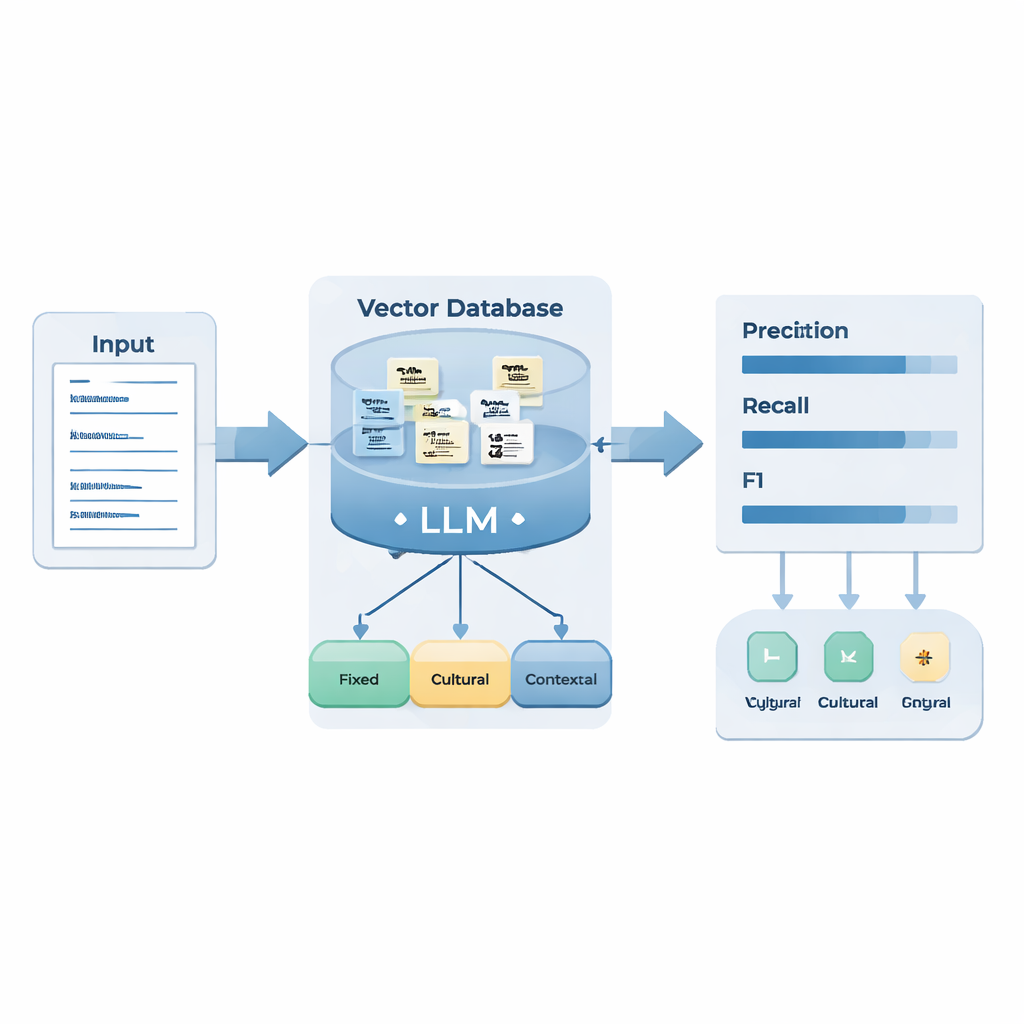
Forskarna samlade in nästan 1 400 fråga–svar-segment från officiella presskonferenser hos Kinas och Rysslands utrikesministerium hållna 2024. Expertlingvister annoterade manuellt 498 fall där talespersoner antydde snarare än talade rakt ut. De grupperade dessa i tre typer: ”fasta antydningar” med stabil, upprepad formulering (till exempel standarddiplomatiska fraser), ”kulturella antydningar” vars mening bygger på delad kulturell kunskap och metaforer, och ”kontextuella antydningar” som endast kan kännas igen genom noggrann granskning av den omedelbara situationen och motiven. Dessa exempel användes för att bygga en extern kunskapsbas och för att utforma ett uppsättning resonemangsregler för en stor språkmodell.
Att lära modellen att tänka i steg
Teamet kombinerade två AI-tekniker. Retrieval-Augmented Generation (RAG) låter modellen hämta relevanta exempel från den anpassade antydningsdatabasen när den bearbetar ett nytt presskonferenssvar. Chain-of-Thought (CoT)-prompting tvingar sedan modellen att resonera steg för steg: identifiera språket, dela upp svaret i meningar, kontrollera kända antydningsmönster, avgöra om en mening uttrycker ett särskilt motiv (såsom kritik eller varning) genom en igenkänd strategi (såsom faktapåstående, kontrast eller ironi), och slutligen märka det som en fast, kulturell, kontextuell antydning eller "ingen antydning." Systemet utför också en självkontroll för att säkerställa att den implicita betydelsen verkligen skiljer sig från den bokstavliga formuleringen.
Hur bra fungerade det?
För att testa systemet använde författarna nya presskonferensdata från 2025 på båda språken. Sammantaget gjorde den förbättrade modellen ett trovärdigt jobb med att upptäcka dolda budskap: den fångade de flesta genuina antydningar (hög recall) och uppnådde en respektingivande balans mellan att hitta och överdiagnostisera dem (F1-poäng 0,83 för ryska och 0,76 för kinesiska). Den var särskilt stark på fasta antydningar i båda språken, vilket stöder idén att stabila mönster är lättast för maskiner att lära sig. Däremot hade den större svårigheter med kinesiska kulturella och kontextuella antydningar än med ryska. Författarna kopplar detta gap till stilskillnader: ryskt diplomatisk tal använder ofta levande metaforer och kraftiga kontraster som tydligt signalerar kritik eller varning, medan kinesisk diskurs i högre grad förlitar sig på neutrala formler, idiom och kontextberoende artighet, vilket är svårare för modellen att särskilja från bokstavliga uttalanden.
Vad felen avslöjar—och hur man förbättrar
När de granskade misstagen fann författarna tre återkommande problem. Ibland ”överläste” modellen texten och uppfann dolda betydelser där inga fanns. Ibland upptäckte den en antydning men tilldelade fel typ och suddade ut gränsen mellan fasta och kontextuella fall. Och ibland behandlade den helt enkelt vanlig formulering som en antydning eftersom vissa känsliga ord eller bekanta mönster var närvarande. För att åtgärda dessa svagheter föreslår artikeln att man lägger till många tydliga ”ingen antydning”-diplomatiska fraser som negativa exempel, tvingar systemet att i högre grad förankra sina slutsatser i den faktiska frågan och omgivande kontext, matchar meningar mot kunskapsbasen fler än en gång med omskrivningar, och inför ett förfilter och en självvärderingssteg som frågar: är detta redan explicit, eller verkligen implicit?
Varför detta är viktigt för oss alla
För icke-specialister är huvudslutsatsen att stora språkmodeller redan kan hjälpa analytiker att sålla igenom stora volymer officiella uttalanden och flagga ställen där regeringar kan tala mellan raderna. Samtidigt framhäver studien hur starkt diplomatin beror på kultur, historia och stil—faktorer som förblir utmanande även för avancerad AI. Genom att förena lingvistisk teori med moderna AI-verktyg pekar detta arbete mot mer pålitliga system för att spåra subtila signaler i global politik, samtidigt som det tydliggör att mänskligt omdöme och tvärkulturell expertis fortfarande är nödvändiga för att tolka det som lämnas osagt.
Citering: Guo, Y., Wang, X. Hint recognition in Chinese and Russian diplomatic discourse using large language models. Sci Rep 16, 5751 (2026). https://doi.org/10.1038/s41598-026-36338-z
Nyckelord: diplomatiskt språk, implicit betydelse, stora språkmodeller, tvärspråklig analys, retrieval-augmented generation