Clear Sky Science · sv
Djupt inceptions-neuralt nätverk med residuala kopplingar för igenkänning av handskrivna tamilska tecken
Spara handskrift i den digitala eran
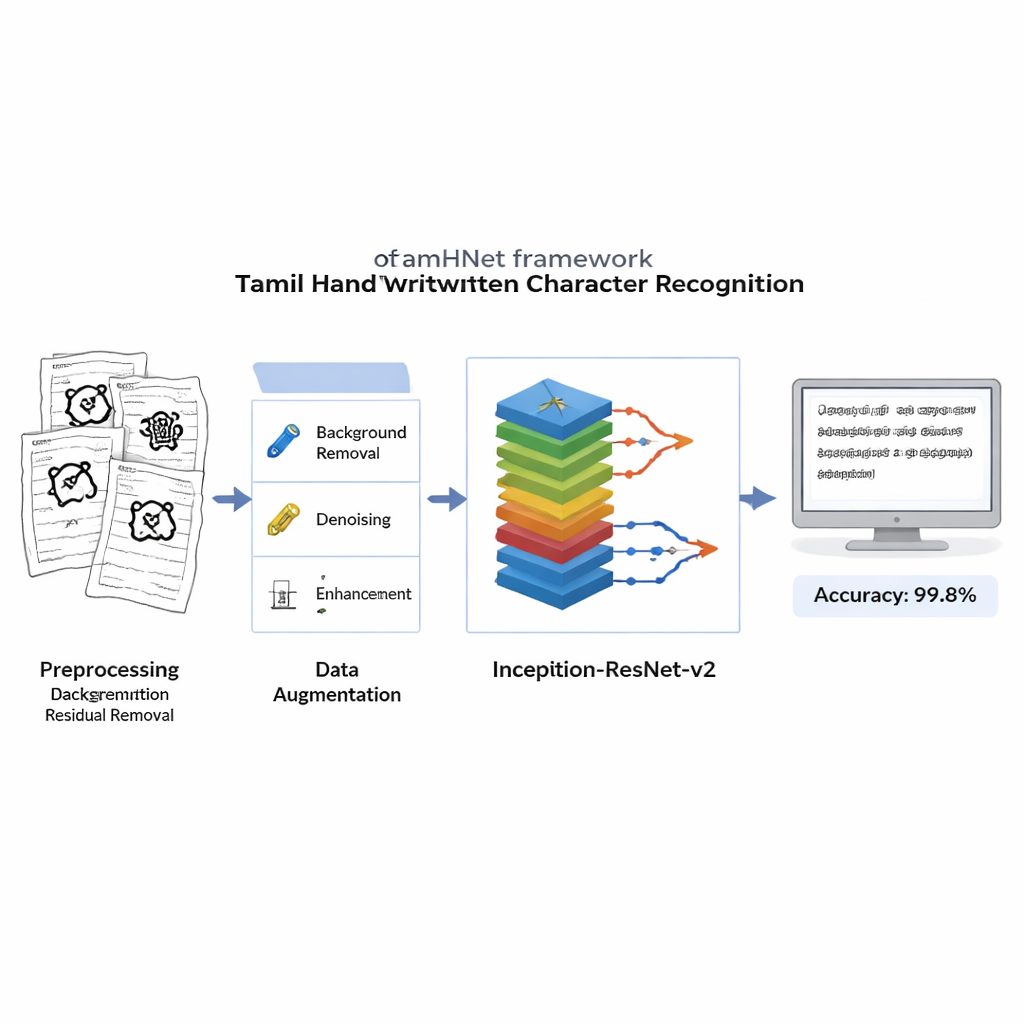
Från gamla palmlövshandskrifter till vardagliga anteckningar lever mycket av det tamilska skriftarvet fortfarande på papper. Att förvandla denna rika blandning av handskrivna sidor till sökbar digital text är avgörande för att bevara kultur, stödja utbildning och bygga bättre språkteknologi. Denna artikel presenterar ett nytt datorseendesystem, kallat TamHNet, som läser tamilsk handskrift med nästan perfekt noggrannhet, även när bokstäver ser förvillande lika ut.
Varför tamiltecken är svåra för datorer
Tamil talas av mer än 80 miljoner människor och använder ett skriftsystem med 247 tecken, inklusive vokaler, konsonanter och många kombinationer av dessa. Många bokstäver skiljer sig endast åt genom små krökar eller extra streck, och skribenter varierar mycket i hur de formar varje tecken. Par som எ/ஏ eller ஒ/ஓ kan vid en första anblick se nästan identiska ut, och tecken som ல och வ kan lätt förväxlas med varandra. Tidigare datorprogram och även moderna maskininlärningssystem hade ofta svårt med dessa subtiliteter, vilket ledde till felaktigt tolkade ord och opålitlig digitalisering av dokument.
Bygga en dataset med verklig handskrift
För att träna och testa sitt system under realistiska förhållanden skapade forskarna en ny Tamil Isolated Character Dataset med handskrivna prover från 1 000 universitetstudenter. Istället för att förlita sig på syntetiska eller datorgenererade bilder samlade de genuina bläck-på-papper-tecken som täcker 12 vokaler, 18 konsonanter och 214 vanliga kombinationer. Teamet märkte noggrant dessa prover och gjorde datasetet öppet tillgängligt så att andra grupper kan jämföra metoder och bygga vidare på arbetet. Genom att organisera skriptet i 104 basala symboler som fångar alla 247 tecken minskade de redundans samtidigt som de fortfarande representerar hela spektrumet av former som förekommer i verklig handskrift.
Rengöring, sträckning och inlärning av bilderna
Innan någon inlärning äger rum rengörs varje skannad bild för att ta bort brusiga bakgrunder, fläckar och ojämn belysning samtidigt som de känsliga strecken som definierar varje bokstav bevaras. Bilderna konverteras till skarpa svartvita bilder och ändras till ett standardformat så att datorn ser varje exempel på samma sätt. För att göra systemet robust mot olika skrivvanor använder författarna kontrollerade distorsioner: de förskjuter lätt nyckelpunkter i bilden och applicerar mjuk deformation, vilket genererar nya varianter av varje tecken som fortfarande ser ut som samma bokstav för en människa. Detta utökade träningsset hjälper modellen att känna igen tecken även när de är lutade, komprimerade eller skrivna med ovanliga proportioner.
Ett djupt nätverk som lär sig subtila skillnader
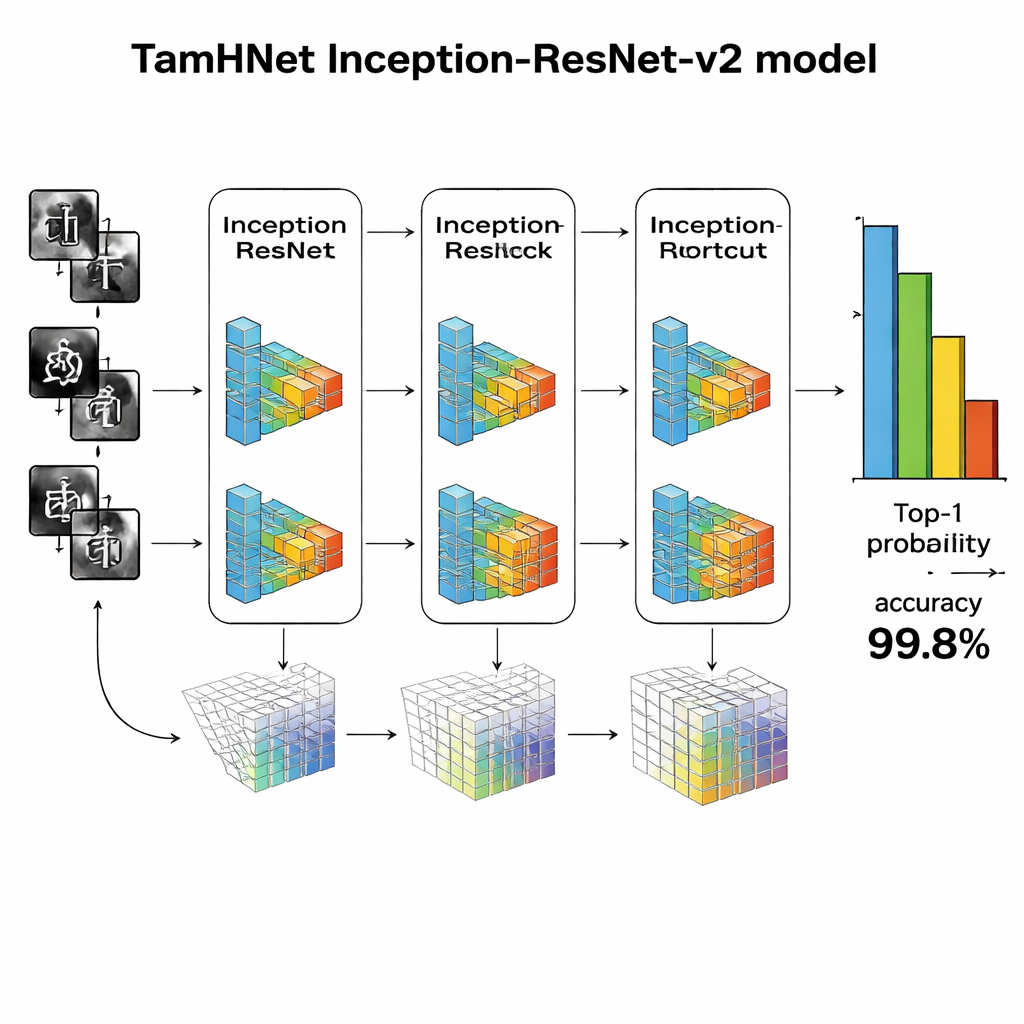
I hjärtat av TamHNet finns en kraftfull djuplärande arkitektur kallad Inception-ResNet-v2, ursprungligen utformad för generell objektigenkänning. Författarna anpassar och finjusterar detta nätverk specifikt för tamilsk handskrift. Modellen bearbetar varje bild genom många lager som gradvis omvandlar råa pixlar till högre nivåers mönster, såsom kanter, kurvor och teckendelar. Särskilda genvägskopplingar, kända som residuallänkar, stabiliserar träningen och hjälper nätverket att fokusera på små men avgörande skillnader mellan liknande bokstäver. Istället för att justera alla interna inställningar på en gång ”frigör” teamet selektivt de mest användbara lagren och finjusterar dem för denna uppgift. De använder en optimeringsteknik kallad Adam, som automatiskt anpassar hur snabbt varje parameter ändras, vilket gör att nätverket kan lära sig effektivt från komplex och ibland rörig handskrift.
Hur väl systemet läser handskrift
Forskarna utvärderar TamHNet på det nya datasetet med hjälp av standardmått för igenkänningskvalitet. Systemet uppnår ungefär 99,8 % noggrannhet över 104 teckenklasser och överträffar en rad tidigare metoder baserade på supportvektormaskiner, traditionella konvolutionella nätverk och andra avancerade djuplärande konstruktioner. Detaljerade tester visar att även bokstäver med extremt liknande former i de flesta fall särskiljs korrekt, och statistiska kurvor bekräftar att modellen mycket sällan förväxlar ett tecken med ett annat. Jämfört med tidigare arbete utgör detta ett tydligt framsteg i tillförlitlighet för igenkänning av handskrivna tamilska tecken.
Vad detta betyder för läsare och arkiv
För icke-specialister är huvudsaken att datorer blir dramatiskt bättre på att läsa tamilsk handskrift. Ett system som TamHNet kan driva verktyg som förvandlar högar av anteckningsböcker, historiska manuskript och handskrivna formulär till sökbar digital text med minimal mänsklig korrigering. Även om den nuvarande modellen ännu inte hanterar vissa prickbaserade symboler och äldre skriptvarianter, skisserar författarna planer på att utöka den till forntida skrivstilar också. I praktiska termer för oss denna forskning närmare storskalig, korrekt digitalisering av tamilska dokument, vilket hjälper till att skydda kulturarvet och göra skriven kunskap lättare att nå för framtida generationer.
Citering: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Nyckelord: Igenkänning av handskrivna tamilska tecken, optisk teckenigenkänning, djuplärande, Inception-ResNet, digital bevarande