Clear Sky Science · sv
Jämförelse av stora språkmodellers prestanda i kunskapsbedömning om bor-neutronfångstterapi
Smarta handledare för en ny typ av cancerstrålning
Boron neutron capture therapy, eller BNCT, är en framväxande form av strålbehandling som syftar till att förstöra tumörer samtidigt som intilliggande frisk vävnad skonas. När denna komplexa behandling nu tar steget från forskningslaboratorier till sjukhus behöver läkare och underläkare behärska mycket ny, specialiserad kunskap. Denna studie ställer en aktuell fråga: kan dagens populära AI-chattbotar hjälpa till att undervisa och stödja BNCT, och i så fall hur tillförlitliga är de?
Vad skiljer BNCT från vanlig strålbehandling?
BNCT fungerar på ett helt annat sätt än standardbehandlingar med röntgen eller protoner. Patienterna får läkemedel som innehåller en särskild form av bor som ansamlas i tumörceller. När dessa celler senare utsätts för en neutronstråle genomgår boratomerna en liten kärnreaktion som frigör kortdistanspartiklar, vilket dödar cancercellen inifrån samtidigt som omkringliggande vävnad i stor utsträckning lämnas intakt. Denna mycket målinriktade metod är särskilt lovande för svårbehandlade eller syrefattiga tumörer. Fram till nyligen har BNCT varit beroende av kärnreaktorer som neutronskällor, vilket begränsade dess kliniska användning. Godkännandet av acceleratorbaserade BNCT-maskiner i Japan 2020, och nya centra som nu drivs i länder som Kina, har förvandlat BNCT till ett realistiskt alternativ för fler patienter — och skapat ett akut behov av fokuserad utbildning och certifiering.
Att testa fyra ledande AI:er
För att se hur väl allmänna chattbotar hanterar BNCT-ämnen konstruerade forskarna ett 47-frågeprov som täckte grundläggande idéer, den senaste forskningen, klinisk praxis samt beräknings- och resonemangsuppgifter. Frågorna skrevs både på kinesiska och engelska och omfattade enkla fakta (som definitioner) och mer krävande problem som fordrade logik eller numeriskt arbete. Fyra stora AI-familjer — representerade av vida använda system från olika företag — testades var och en över fem separata tidpunkter, på två språk och med två sätt att ställa frågor (enkla direkta frågor och frågor inbäddade i ett kort kliniskt scenario). Människor med specialistkompetens inom cancervård poängsatte varje svar mot en standardnyckel, och teamet noterade också hur ofta AI:erna erkände osäkerhet genom att säga saker som ”Jag vet inte.”
Vem svarade bäst, och på vilken typ av frågor?
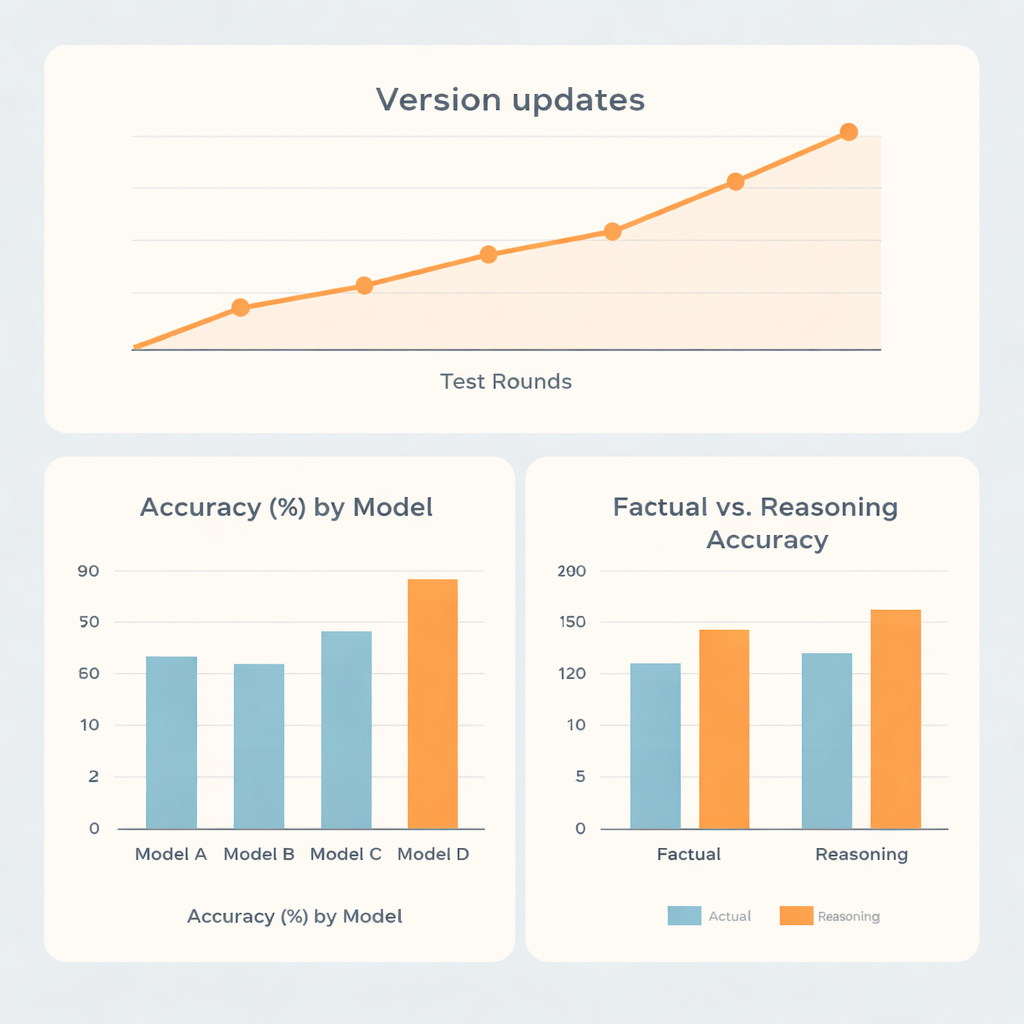
Sammanlagt presterade två modellfamiljer tydligt bättre än de andra två. Det starkaste systemet uppnådde ungefär 73 % korrekt, och det näst starkaste cirka 70 %, medan de återstående modellerna hamnade runt 62 % respektive 56 %. Intressant nog utmärkte sig toppresterarna inte enbart på inlärda fakta. De var märkbart bättre på frågor som krävde resonemang än på rena återgivningsfrågor, vilket tyder på att dessa system är relativt starka i flerstegsresonemang, såsom dosberäkningar eller planeringsliknande problem, inom detta snäva medicinska område. En modell visade nästan samma poäng på fakta- och resonemangsfrågor, medan en annan låg efter totalt sett trots att den gjorde något bättre ifrån sig på resonemangsuppgifterna än på faktafrågorna.
Uppdateringar, språk och vilja att säga ”Jag vet inte”
Eftersom AI-system uppdateras ofta undersökte forskarna också hur prestandan förändrades över fem testrundor spridda från slutet av 2023 till mitten av 2025. Stora versionsuppgraderingar tenderade att ge tydliga hopp i noggrannhet, medan mindre justeringar inom samma version gjorde liten skillnad. En familj klättrade från under 60 % till över 80 % korrekt över tid, vilket belyser hur snabbt tekniken utvecklas. Förvånande nog hade det liten betydelse om frågor ställdes på kinesiska eller engelska, eller direkt respektive inramade som rollspel, jämfört med de inneboende styrkorna i varje modell. Mer påtagliga var skillnaderna i hur öppna systemen var när de hade fel. Vissa modeller erkände osäkerhet i nästan var femte felaktiga svar, medan en annan sällan gjorde det och ofta gav självsäkra men felaktiga svar istället.
Vad detta betyder för läkare, studenter och patienter
Studien drar slutsatsen att dagens bästa allmänna chattbotar redan kan ge rimligt korrekta förklaringar och övningsfrågor om BNCT, vilket gör dem till lovande hjälpmedel för utbildning och självstudier. Ingen av systemen kan dock ännu litas på att besvara alla BNCT-frågor korrekt, och deras sätt att uttrycka — eller dölja — osäkerhet skiljer sig åt på sätt som har betydelse för säkerheten. För tillfället är dessa verktyg bäst att betrakta som smarta assistenter som kan stödja, men inte ersätta, expertbedömning. Författarna menar att dedikerade AI-modeller inriktade på BNCT, tillsammans med tydliga standarder för hur sådana verktyg ska användas i kliniker och klassrum, kommer att behövas innan AI kan spela en pålitlig frontlinjeroll i denna högt specialiserade form av cancerbehandling.
Citering: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Nyckelord: bor-neutronfångstterapi, cancerstrålning, medicinsk utbildning, artificiell intelligens, stora språkmodeller