Clear Sky Science · sv
Objektledd kontrastiv språk‑bildförträning för nollskottsigenkänning av mål
Smartare blickar för trånga himlar och hav
Moderna säkerhets‑ och katastrofinsatsystem förlitar sig på kameror i luften och till sjöss för att upptäcka flygplan, fartyg och andra viktiga objekt. Men att lära datorer att skilja en stridsflygplan från ett passagerarplan, eller ett krigsfartyg från ett lastfartyg, är förvånansvärt svårt när scenerna är röriga, data är knapphändiga och nya utrustningsmodeller ständigt dyker upp. Denna artikel introducerar OG‑CLIP, ett nytt AI‑system utformat för att känna igen militära och civila mål som det aldrig uttryckligen tränats på, genom att kombinera storskalig förkunskap med ett skarpare visuellt fokus på de objekt som betyder mest.
Varför traditionell AI missar målet
De flesta bildigenkänningssystem lär sig från enorma mängder märkta bilder: varje bild kopplas till en fast lista kategorier, som ”katt” eller ”bil”. Den metoden fallerar i specialiserade domäner som försvar och fjärranalys, där data är känsliga, märkning kräver experter och utrustningsvariationerna är enorma. Nyare visions‑språk‑modeller som CLIP parar ihop bilder med korta textbeskrivningar från webben, vilket gör det möjligt att känna igen nya begrepp som beskrivs i ord. Ändå har dessa modeller fortfarande problem i militär bildanalys: bildtexter är ofta vaga, bakgrunder som moln och vågor dominerar pixlarna, och deras interna representationer är inte tillräckligt flexibla för att köras effektivt på allt från små drönare till kraftfulla servrar. OG‑CLIP tar itu med alla tre problemen direkt.
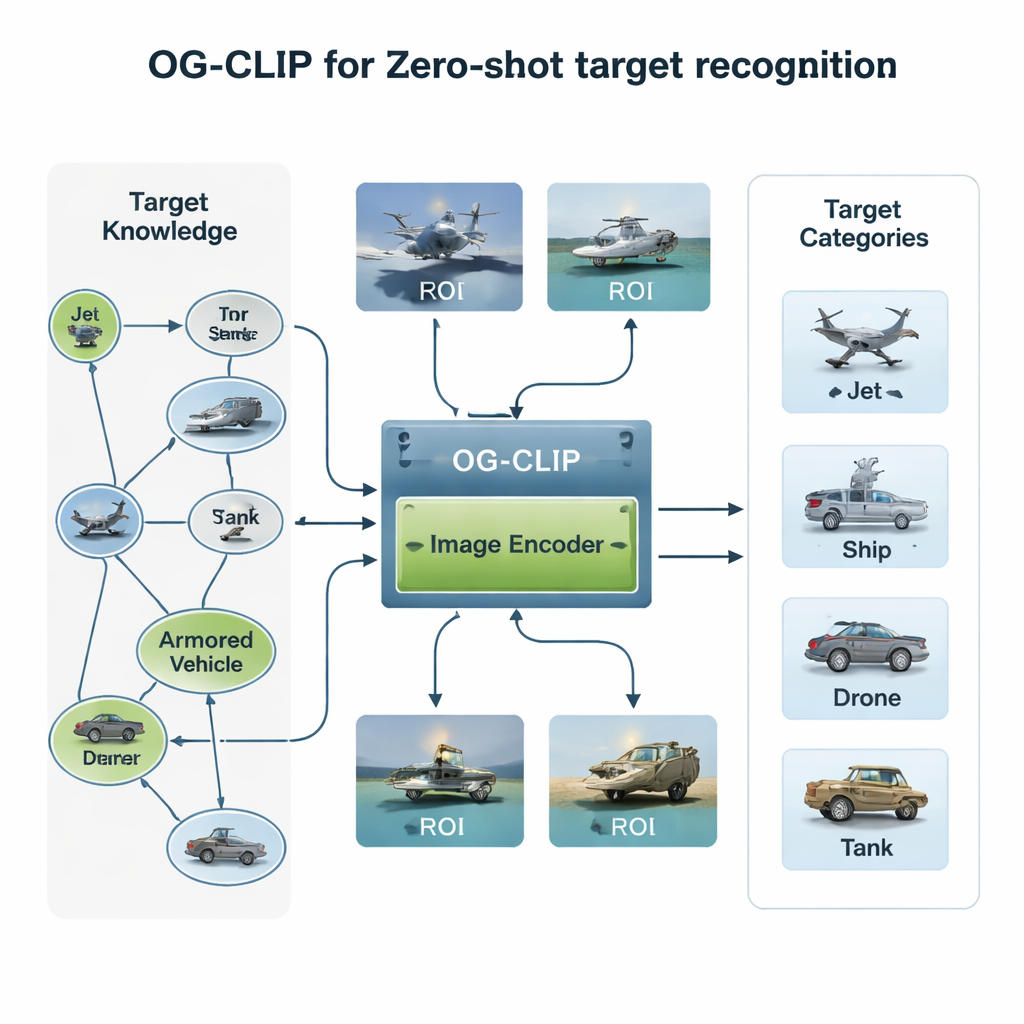
Att bygga en kunskapsrik träningsvärld
Den första ingrediensen i OG‑CLIP är ett omsorgsfullt utformat träningsuniversum. Författarna sammanställde en databas med 5 000 typer av mål—från jakt‑ och bombflygplan till krigsfartyg och civila flyg—och organiserade dem i en detaljerad kunskapsgraf. Varje post innehåller strukturerade fakta som räckvidd, vikt och vapenkonfiguration, hämtade från offentliga försvarsreferenser, uppslagsverk och tekniska dokument. De samlade sedan in ungefär en miljon bilder med hjälp av publika datamängder, webbsök, äldre interna arkiv och till och med simulerade scener från spelmotorer. För att hålla data trovärdiga klustrade de bilder med en befintlig modell för att upptäcka avvikare, följde upp med expertgranskning och filtrerade bort dåliga etiketter. Slutligen använde de avancerade språk‑bildverktyg för att omvandla kunskapsgrafen till rika, naturligt formulerade beskrivningar av varje bild, så att systemet lär sig inte bara ”det här är ett flygplan”, utan ”ett enkelgångsplan med uppåtböjda vingspetsar” eller ”en stealth‑bomber med flygvingesilhuett”.
Att lära modellen att ignorera brus
En andra innovation ligger i var modellen tittar. I många satellit‑ eller flygbilder upptar det faktiska fartyget eller flygplanet bara en liten yta, omgiven av distraherande himmel, hav eller terräng. OG‑CLIP lägger till en region‑of‑interest (ROI)‑modul som efterliknar hur en människa skulle kasta en blick på nyckelobjektet snarare än hela bilden. Ett toppmodernt segmenteringsverktyg skisserar automatiskt sannolika objekt i bilden och producerar mjuka masker som framhäver målet och dämpar bakgrunden. Dessa masker matas, tillsammans med originalbilden, in i modellens visuella ryggrad, så att dess uppmärksamhet naturligt koncentreras på utmärkande detaljer som vingsform, däcklayout eller skrovets silhuett. Denna plug‑in‑design kan läggas till befintliga system utan att skriva om deras kärnarkitektur, vilket ger dem en mer ”objektledd” blick.

Anpassa detaljnivå efter hårdvara
Den tredje delen tar upp en praktisk men avgörande fråga: inte alla enheter har råd med samma detaljnivå. En markstation för satelliter kan bearbeta rika, högdimensionella funktioner, medan en liten drönare behöver snabbare, lättare beräkningar. Traditionella metoder låser en enda funktionsstorlek, eller tränar flera separata modeller för olika storlekar. OG‑CLIP använder istället en ”Matryoshka”‑stil av representation, som packar information på flera detaljnivåer i en och samma vektor, som hopvikta dockor. Systemet kan skära av kortare eller längre delar av denna vektor—grövre eller finare beskrivningar av vad som finns i bilden—utan omlärning. En viktmekanism uppmuntrar varje nivå att behålla den mest användbara informationen för klassificering, och en extra förlustterm knuffar nivåerna att vara semantiskt konsekventa med varandra.
Hur bra fungerar det i praktiken?
För att testa OG‑CLIP byggde forskarna ett krävande utvärderingsset med 99 mål‑kategorier, inklusive 51 typer av militära flygplan, 29 typer av krigsfartyg och 19 civila eller blandade mål. Viktigt är att ingen av dessa kategorier förekommer i träningsdata, så systemet måste förlita sig på sin inlärda förståelse av språk och visuella mönster—ett ”nollskottstest”. Jämfört med flera starka CLIP‑baserade baslinjer förbättrade OG‑CLIP medelklassificeringsnoggrannheten med mer än 11 procentenheter och nådde 84,28 procent totalt. Det presterade särskilt väl i trånga, komplexa scener och vid finare distinktioner mellan liknande modeller, såsom olika jaktflygplan, där ROI‑modulen och de kunskapsrika beskrivningarna gav en tydlig fördel. Ablationsstudier visade att varje komponent—kunskapsgraf‑datan, ROI‑fokus och de adaptiva representationerna—bidrog med mätbara vinster.
Vad detta betyder för övervakning i praktiken
För icke‑specialister är huvudpoängen att OG‑CLIP är ett steg mot säkerhets‑ och övervakningssystem som mer pålitligt kan känna igen okända flygplan och fartyg i verkliga bilder, även när märkta exempel är sällsynta. Genom att kombinera strukturerad expertkunskap, automatisk fokusering på objektet av intresse och justerbara detaljnivåer gör tillvägagångssättet visions‑språk‑AI både smartare och mer praktiskt. Utöver försvar kan liknande idéer hjälpa miljöövervakning, katastrofinsats och industriell inspektion att tolka komplexa scener samtidigt som de körs på en mängd olika hårdvaror.
Citering: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Nyckelord: nollskottsigenkänning, visions‑språk‑modeller, objektigenkänning, fjärranalys, kunskapsgrafer