Clear Sky Science · sv
Visuell perceptionsbaserad djupinlärnings-transformer för klassificering av målningar och fotografier genom funktionsutdragning
Varför det spelar roll för vardagliga bilder
I en tid då vem som helst kan skapa en realistisk bild med några klick blir det svårare att avgöra om en bild är ett verkligt fotografi, en traditionell målning eller något helt framställt av algoritmer. Denna studie undersöker hur modern artificiell intelligens automatiskt kan skilja människoskapt konst från kameratagna foton och till och med från AI-genererade bilder, vilket hjälper till att skydda konstmarknader, arkiv och internetanvändare från förvirring och förfalskning.
Konst, foton och framväxten av maskinskapat bildmaterial
Målningar och fotografier kan vid första anblick se lika ut på en skärm, men de bär på mycket olika visuella fingeravtryck. Målningar tenderar att visa synliga penseldrag, stiliserade färger och mer abstrakta kompositioner, medan fotografier vanligtvis innehåller skarpare detaljer och naturlig belysning. Samtidigt skapar nya bildgeneratorer verk som imiterar båda medier med ökande skicklighet. Museer, gallerier, samlare och digitala plattformar behöver i allt högre grad verktyg som snabbt och pålitligt kan avgöra vilken typ av bild de har att göra med, både för att autentisera konstverk och för att hantera floden av syntetiskt innehåll.
En ny pipeline för att lära maskiner att se
Forskarna byggde en komplett bildanalys-pipeline baserad på en Vision Transformer, en nyare djupinlärningsmodell som ursprungligen utvecklades för språkbehandling och nu anpassats för bilder. De tränade systemet på en publik Kaggle-dataset som innehåller 1 361 målningar och 3 747 fotografier, som representerar en mängd olika scener och stilar. Varje bild standardiseras först: den skalas om, beskärs lätt och augmenteras därefter genom speglingar, små rotationer, ljusstyrkeförändringar och brusborttagning så att modellen exponeras för många realistiska variationer. Efter denna förberedelse delar Vision Transformern upp varje bild i små patchar och lär sig hur olika delar av bilden relaterar till varandra över hela bilden. 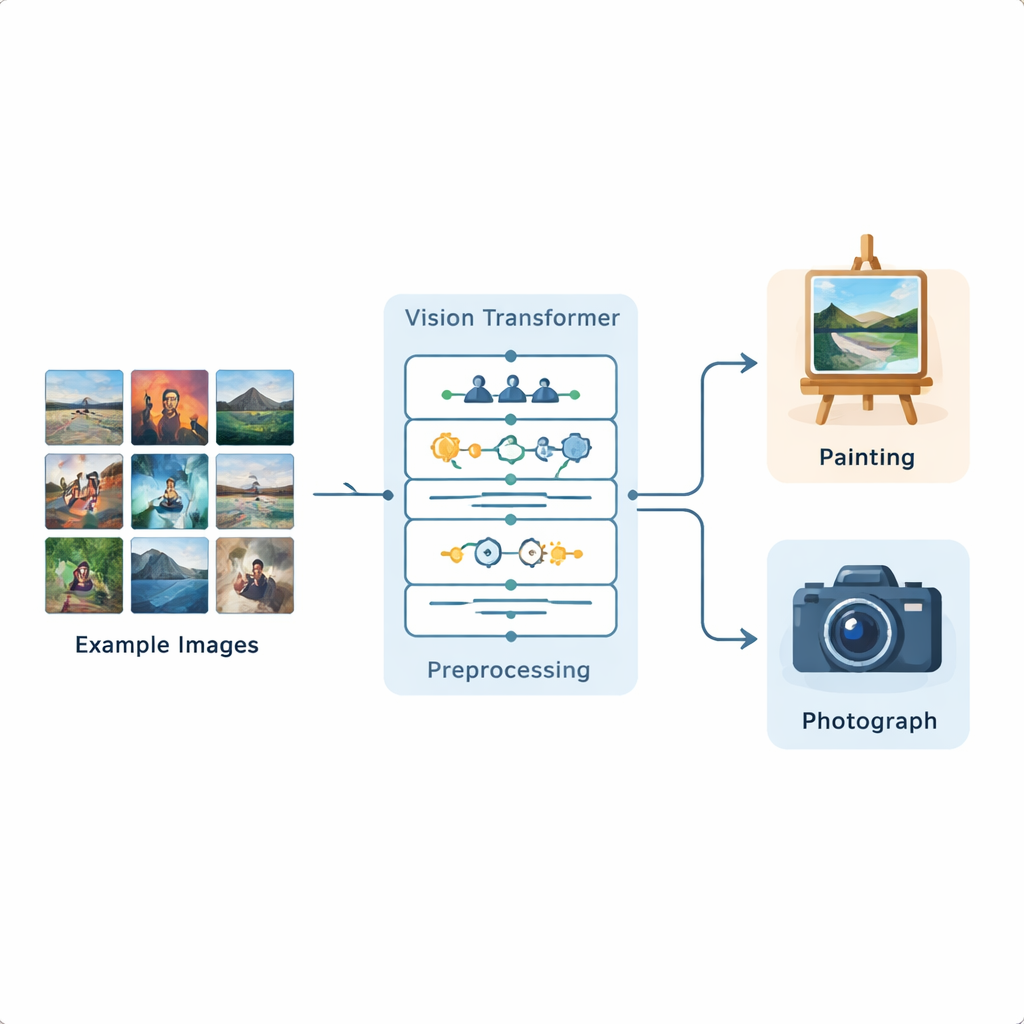
Hur modellen fokuserar på rätt detaljer
Till skillnad från tidigare neurala nätverk som huvudsakligen ser lokala mönster använder Vision Transformern en "attention"-mekanism för att avgöra vilka delar av en bild som är viktigast för uppgiften. Den frågar i praktiken, för varje patch, hur starkt den ska uppmärksamma varje annan patch. Det gör den bättre på att uppfatta global struktur: hur färger flyter över en duk, hur ljus faller över en scen eller hur texturer upprepar sig. För att kontrollera att modellen inte gissar godtyckligt tillämpar författarna också en visualiseringsmetod kallad Grad-CAM, som markerar de specifika regioner som påverkade varje beslut. För målningar ligger dessa markeringar ofta på penseldrag och stiliserade områden; för fotografier klustrar de sig kring fina kanter, realistiska ytor och ljusövergångar. 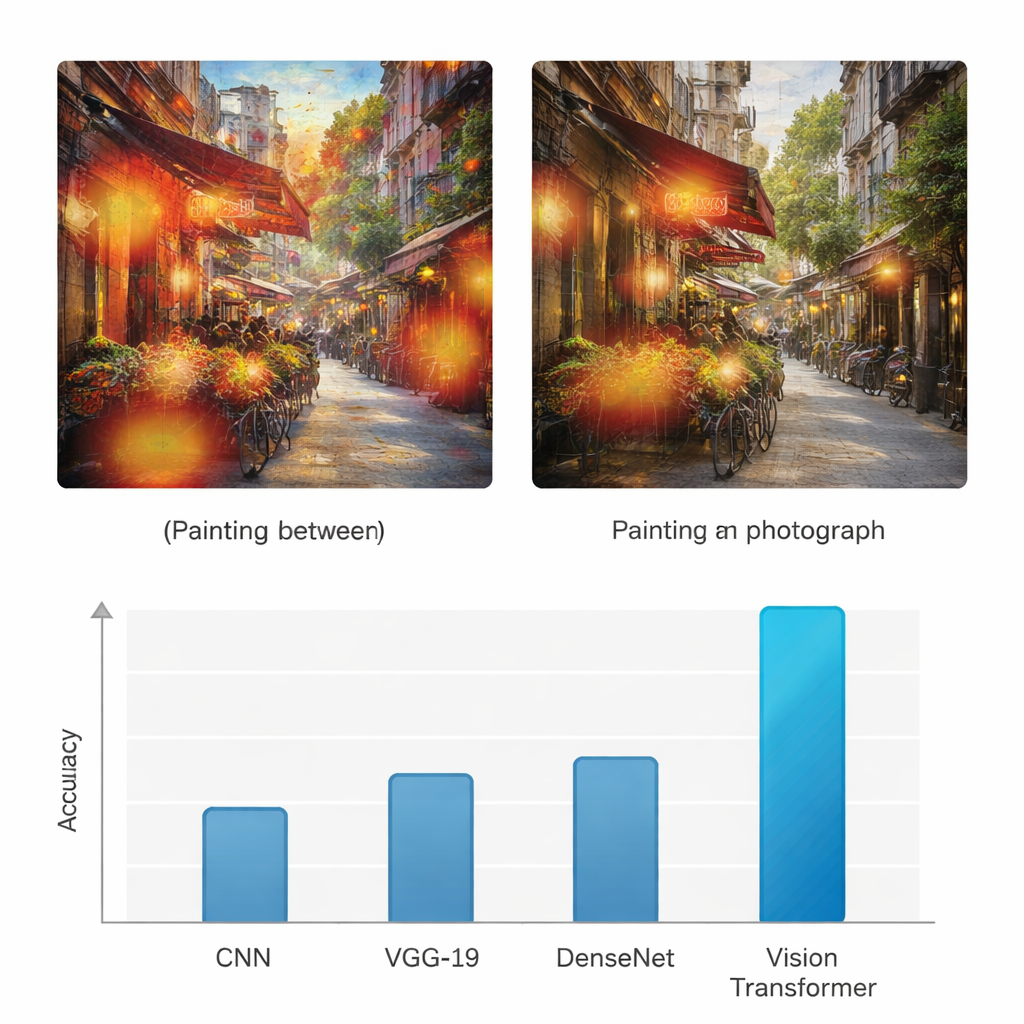
Överträffar tidigare bildigenkänningsmetoder
För att avgöra om detta tillvägagångssätt verkligen tillför värde jämför studien Vision Transformern med tre allmänt använda djupinlärningsarkitekturer: ett standard konvolutionellt neuralt nätverk (CNN), VGG-19 och DenseNet. Alla modeller tränas och testas på samma dataset och utvärderas med vanliga mått såsom noggrannhet, precision, recall och F1-poäng, som väger samman korrekta träffar och fel för båda klasserna. Medan basnäten når noggrannheter i intervallet mitten av 70- till mitten av 80-procent, uppnår Vision Transformern 95 % noggrannhet för både målningar och fotografier, med liknande höga värden för precision och recall. Författarna genomför dessutom flera statistiska tester för att bekräfta att denna förbättring inte beror på slump, och visar att den transformer-baserade modellen konsekvent är bättre över upprepade körningar och olika utvärderingskriterier.
Vad detta betyder för konst, förtroende och teknik
Resultaten tyder på att moderna transformermodeller kan fungera som kraftfulla och förklarbara verktyg för att särskilja målningar från fotografier och för att flagga AI-genererade bilder som imiterar något av medierna. För icke-specialister är slutsatsen att datorer nu kan upptäcka subtila ledtrådar — såsom penselföring, släthet eller ljusgradienter — som även noggranna mänskliga observatörer kan missa, och göra det i stor skala. Sådana system kan hjälpa gallerier och samlare att verifiera verk, bistå kuratorer och arkivarier med att organisera omfattande digitala samlingar och stödja onlineplattformar i att märka eller filtrera syntetiskt innehåll. Allteftersom bildgeneratorer fortsätter att sudda ut gränsen mellan verklighet och fantasi erbjuder metoder som den som presenteras här ett praktiskt sätt att bevara förtroendet för det vi ser.
Citering: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Nyckelord: AI-genererade bilder, autentisering av konst, bildklassificering, vision transformer, analys av digital konst