Clear Sky Science · sv
Metainlärning för få-skotts öppen-uppgiftsigenkänning
Varför det spelar roll att lära AI med väldigt få exempel
Moderna AI-system kan känna igen ansikten, djur och vardagsföremål med anmärkningsvärd noggrannhet—men oftast först efter att ha sett miljontals märkta bilder. I många verkliga situationer, som vid diagnos av en ovanlig sjukdom eller vid upptäckt av en ny typ av defekt på en fabrikslinje, har vi helt enkelt inte så mycket data. Denna artikel undersöker hur man tränar AI-modeller som kan lära sig nya visuella uppgifter från bara ett fåtal exempel, även när dessa uppgifter ser ganska annorlunda ut jämfört med vad modellen tränats på. Den presenterar en metod kallad Open-MAML som syftar till att göra denna typ av flexibel, lågdatainlärning mer pålitlig och förutsägbar.
Från fasta klassrumsövningar till öppna överraskningstentor
Det mesta av forskningen om ”få-skotts inlärning” utvärderar AI-system under strikt kontrollerade förhållanden. Modellen tränas och testas på mycket liknande uppgifter, till exempel att den alltid måste skilja mellan exakt fem kategorier (kallat ”5-way”) med ett exempel per kategori (”1-shot”). Det är som att bara öva en elev på femfrågeprov med ett övningsexempel per frågetyp. Verkliga tillämpningar är mycket rörigare: antalet kategorier kan förändras, och mängden märkta data för varje kategori kan öka eller minska över tid. Författarna kallar denna mer realistiska situation för öppen-uppgiftsinställning, där modeller måste hantera uppgifter med antal klasser och exempel som skiljer sig från vad de någonsin såg under träningen. 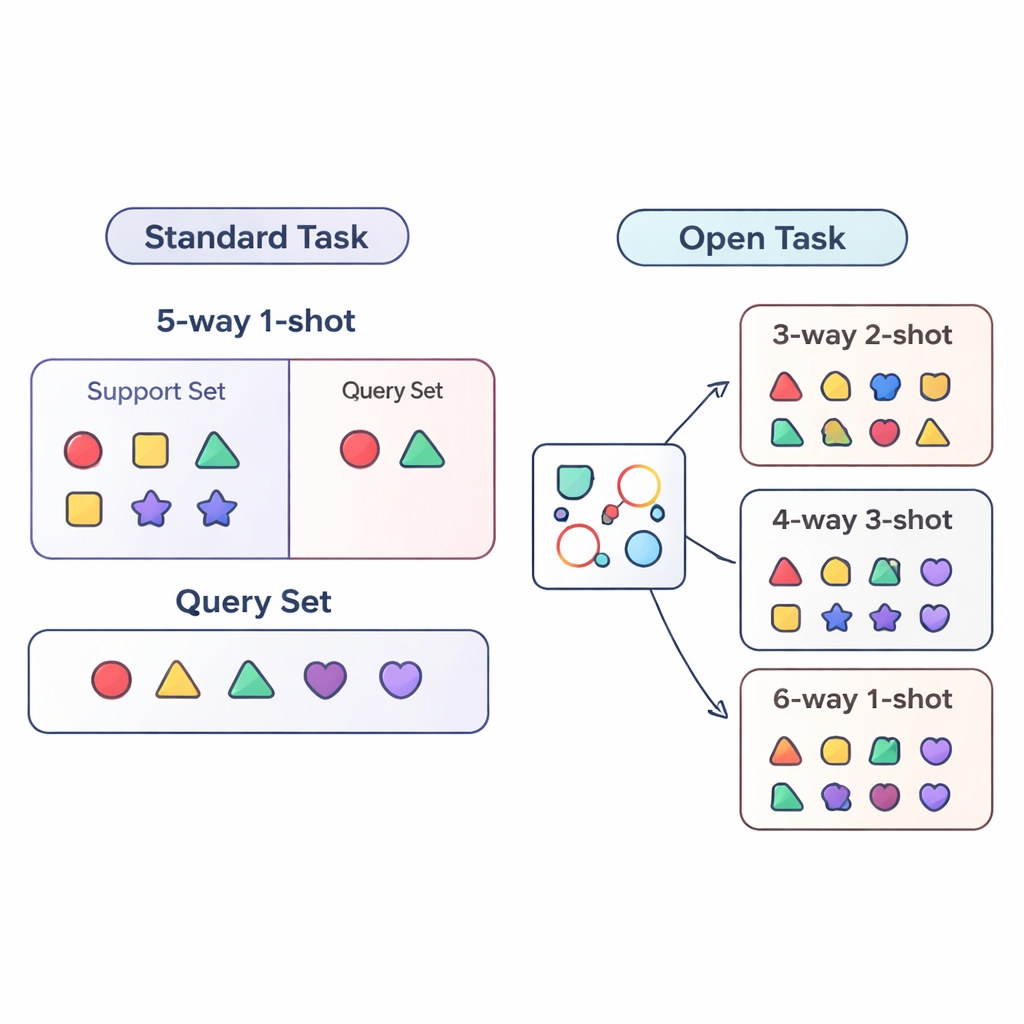
Omtolkning av hur vi testar få-skottsinlärare
För att studera denna öppna-uppgiftsvärld på ett systematiskt sätt föreslår artikeln tre utvärderingsregimer. I cross-way-regimen ändras endast antalet klasser: modellen kan till exempel tränas på fem klasser men testas på tre eller femton. I cross-shot-regimen varierar antalet exempel per klass, från en enda märkt bild till flera. Det svåraste fallet är cross-way–cross-shot, där både antalet klasser och mängden data per klass förändras samtidigt. Författarna undersöker också vad som händer när den visuella stilen hos data skiftar, genom att träna på en generell objektmängd och testa på en finuppdelad fågeldataset. Dessa upplägg är utformade för att avslöja om en metod verkligen kan generalisera bortom ett enda, fast träningsrecept.
Hur Open-MAML anpassar sig i farten
Open-MAML bygger vidare på en populär metainlärningsstrategi kallad Model-Agnostic Meta-Learning (MAML), som tränar en modell så att den snabbt kan anpassa sig till en ny uppgift med några få gradientsteg. Standard-MAML antar dock att antalet klasser vid testtid matchar träningen, och använder ett fast slutligt klassificeringslager. Open-MAML inför tre viktiga justeringar för att bryta denna begränsning. För det första använder den dynamisk klassifikatoruppbyggnad: när en ny uppgift har fler klasser än tidigare skapar den extra utgångsenheter genom att kopiera genomsnittet av de befintliga, vilket ger modellen en neutral men rimlig startpunkt. För det andra anpassar den den inre inlärningshastigheten baserat på hur många klasser och exempel uppgiften har, så att anpassningen förblir stabil oavsett om data är knappa eller rikliga. För det tredje lägger den till en regulariserare kallad AdaDropBlock som temporärt döljer sammanhängande regioner i feature-kartor under träning, vilket uppmuntrar modellen att använda mer varierade visuella ledtrådar istället för att överanpassa till små, sköra detaljer. 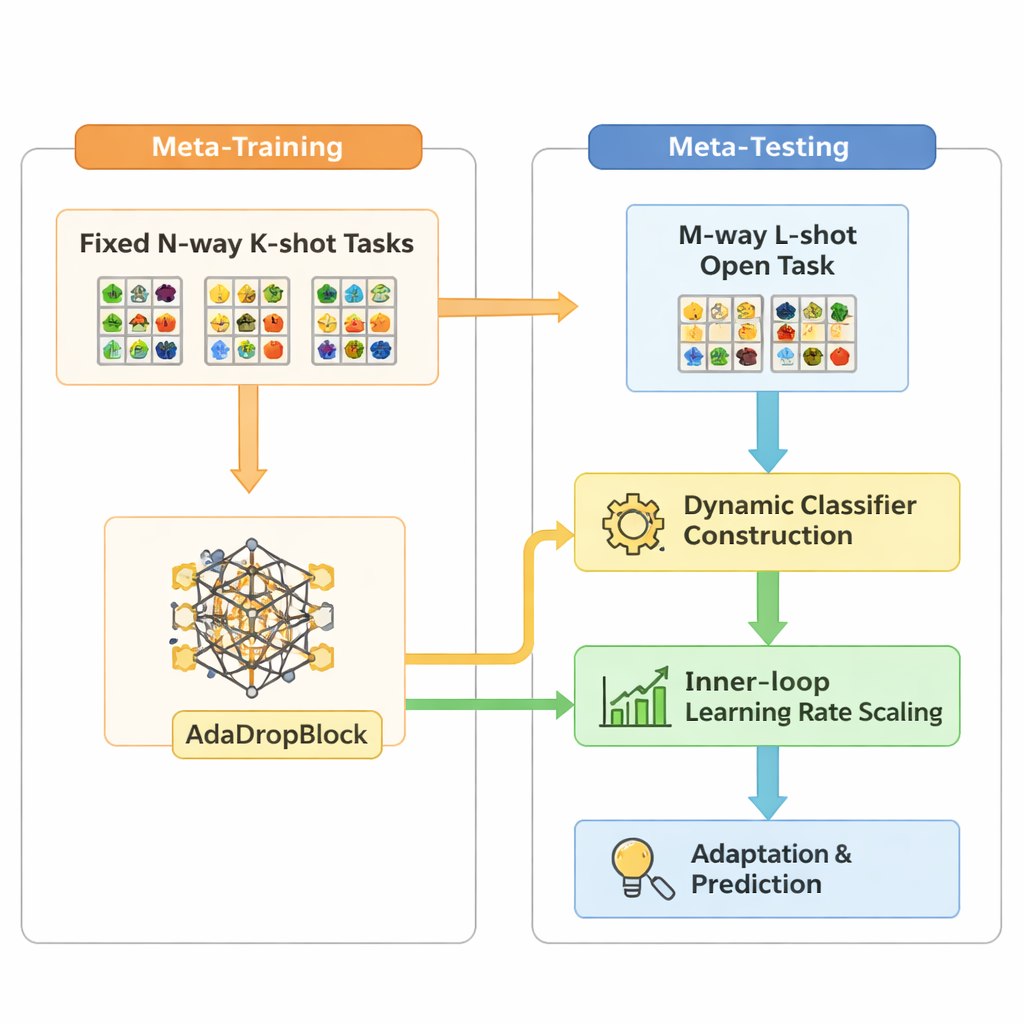
Sätter flexibel inlärning på prov
Forskarlaget utvärderar Open-MAML på standardbenchmarks för få-skottsinlärning och under de nya öppna-uppgifts-scenarierna, och jämför den med flera välkända baslinjer. Dessa inkluderar modeller som helt enkelt tränas från början för varje uppgift, modeller som använder en stark förtränad feature-extraktor plus en finjusterad klassificerare, och metrisk-baserade metoder som klassificerar bilder baserat på avståndet till klassens ”prototyper”. Alla metoder använder samma backbone-nätverk så att skillnaderna kommer från inlärningsstrategin, inte arkitekturen. Över tiotusentals testuppgifter uppnår Open-MAML konsekvent högre noggrannhet—vanligtvis 1–7 procentenheter bättre när endast antalet klasser eller exempel ändras, och 3–6 poäng bättre när båda varierar. Förbättringarna är ännu mer uttalade i svårare inställningar med fler klasser, fler skott eller ett skifte till fågeldatasetet, vilket tyder på att dess anpassningsmekanismer verkligen hjälper i komplexa, okända miljöer.
Vad detta betyder för AI-system i verkligheten
För en allmän läsare är huvudbudskapet att inte alla få-skottsinlärare är likadana när vi lämnar labbets bekväma zon. En metod som glänser på en enda, fast benchmark kan snubbla när antalet kategorier eller mängden märkta data förändras. Open-MAML visar att genom att uttryckligen planera för sådana strukturella förändringar—låtande klassificeraren växa eller krympa, skala inlärningshastigheten med uppgiftens storlek och regularisera features på ett uppgiftsneutralt sätt—kan AI-system bättre klara av de skiftande förhållanden de kommer att möta i praktiken. I tillämpningar som medicinsk bildanalys, satellitövervakning eller industriell inspektion, där både uppsättningen av kategorier och tillgången på etiketter ständigt är i förändring, kan denna typ av öppen-uppgiftsrobusthet göra få-skottsinlärning betydligt mer användbar utanför noggrant kurerade forskningsbenchmarks.
Citering: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Nyckelord: få-skotts inlärning, metainlärning, öppen-uppgiftsigenkänning, bildklassificering, generaliseringsförmåga