Clear Sky Science · sv
Dialektbyte som en adversarial metod för att utvärdera robustheten i arabisk NLP
Varför vardagsarabiska förvirrar smarta datorer
Många appar läser numera arabisk text för att bedöma känsloläge, sortera nyheter eller svara på frågor. Ändå tränas dessa system mest på modern standardarabiska (MSA), medan verkliga människor varje dag blandar in regionala dialekter. Denna artikel visar hur det räcker att byta ut ett enda ord till egyptisk eller gulf‑arabiska för att lura toppmoderna språkmodeller, vilket väcker oro för alla som förlitar sig på arabisk AI inom kundservice, mediebevakning eller online‑säkerhet.
Ett språk, många röster
Arabiska är inte ett enhetligt sätt att tala. MSA används i skolor, i nyheter och i formella texter, men vardagliga samtal bygger på dialekter såsom egyptiska och gulf‑arabiska. Dessa varianter skiljer sig i ordförråd, böjningsformer och till och med i satsstruktur. Till exempel har ett enkelt ord som ”nu” väldigt olika former i olika regioner. För människor är dessa variationer naturliga och lätta att förstå. För datormodeller som nästan uteslutande tränats på MSA kan dialektord däremot verka obekanta och göra en klar mening svårtolkad.
Gör dialekter till ett stresstest för AI
För att undersöka hur sköra arabiska språkmodeller verkligen är utformar författaren ett enkelt tvåstegsprov. Först frågas modellen upprepade gånger för att hitta det enda ord i en mening som påverkar dess beslut mest—ofta ett starkt adjektiv, ett nyckelverb eller ett centralt substantiv. Därefter ersätts det ordet med en motsvarighet från egyptiska eller gulf‑arabiska med hjälp av en stor, noggrant finjusterad ”dialektiserare”. Resten av meningen lämnas intakt och betydelsen för en mänsklig läsare förblir densamma. Det gör den ändrade meningen till ett realistiskt adversarialt exempel: en liten, naturligt framståendeförändring skapad för att lura systemet utan att ändra budskapet.
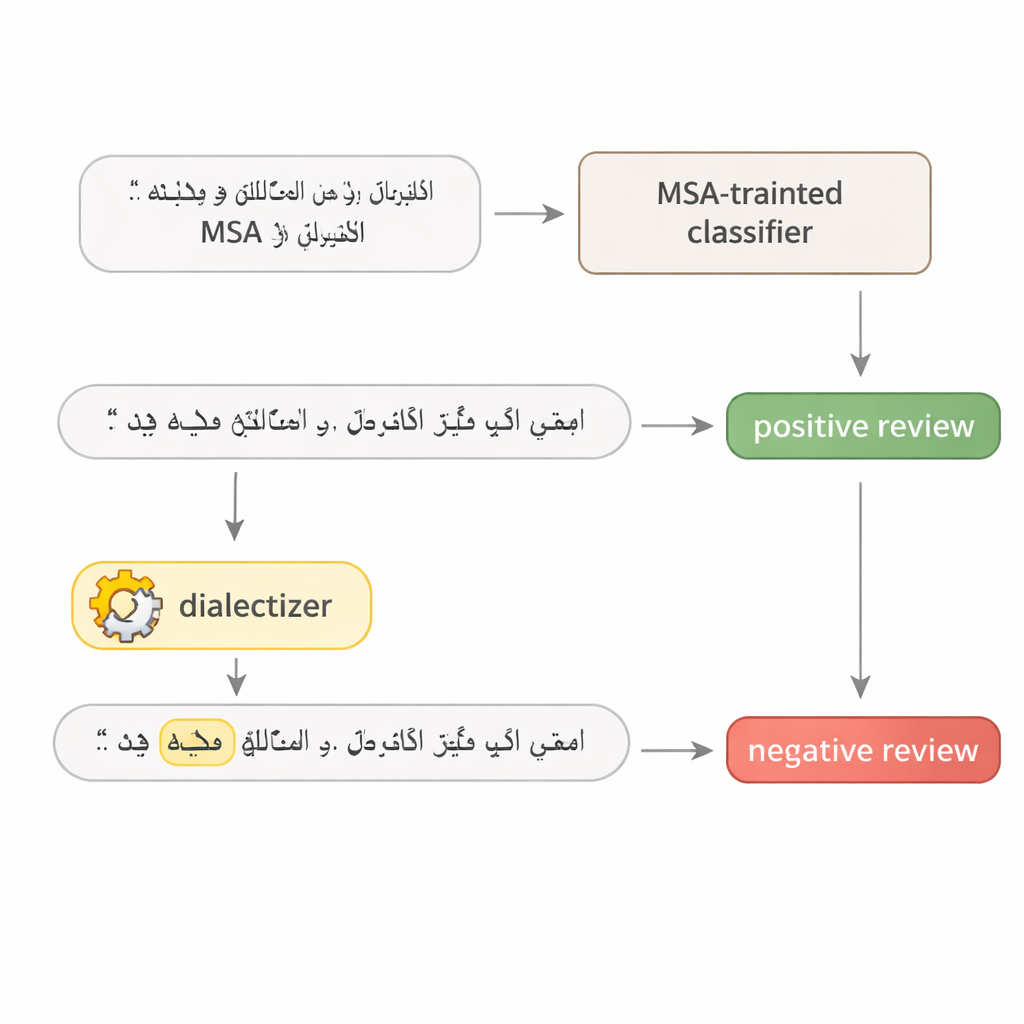
Sätter hotellrecensioner och nyhetsartiklar på prov
Studien angriper fyra välkända djupa inlärningsmodeller: två stora transformer‑modeller (AraBERT och CAMeLBERT) och två mindre nätverk (en konvolutionsmodell och en bidirektionell LSTM). De tränas på två stora MSA‑dataset: hotellrecensioner för sentimentanalys och nyhetsartiklar för ämnesklassificering. Från varje testset drar författaren 1 280 exempel och applicerar proceduren för dialektalt utbyte. Trots att endast ett ord i varje mening byts ut är effekten tydlig. För hotellrecensioner sjunker AraBERTs noggrannhet från 94 procent på ren text till ungefär 72 procent med gulf‑ersättningar och 65 procent med egyptiska. CAMeLBERT faller ännu mer, ner till ungefär 63 respektive 55 procent. Nyhetsklassificerare drabbas också: konvolutionsmodellen tappar omkring 18 till 22 procentenheter och LSTM visar liknande nedgångar.
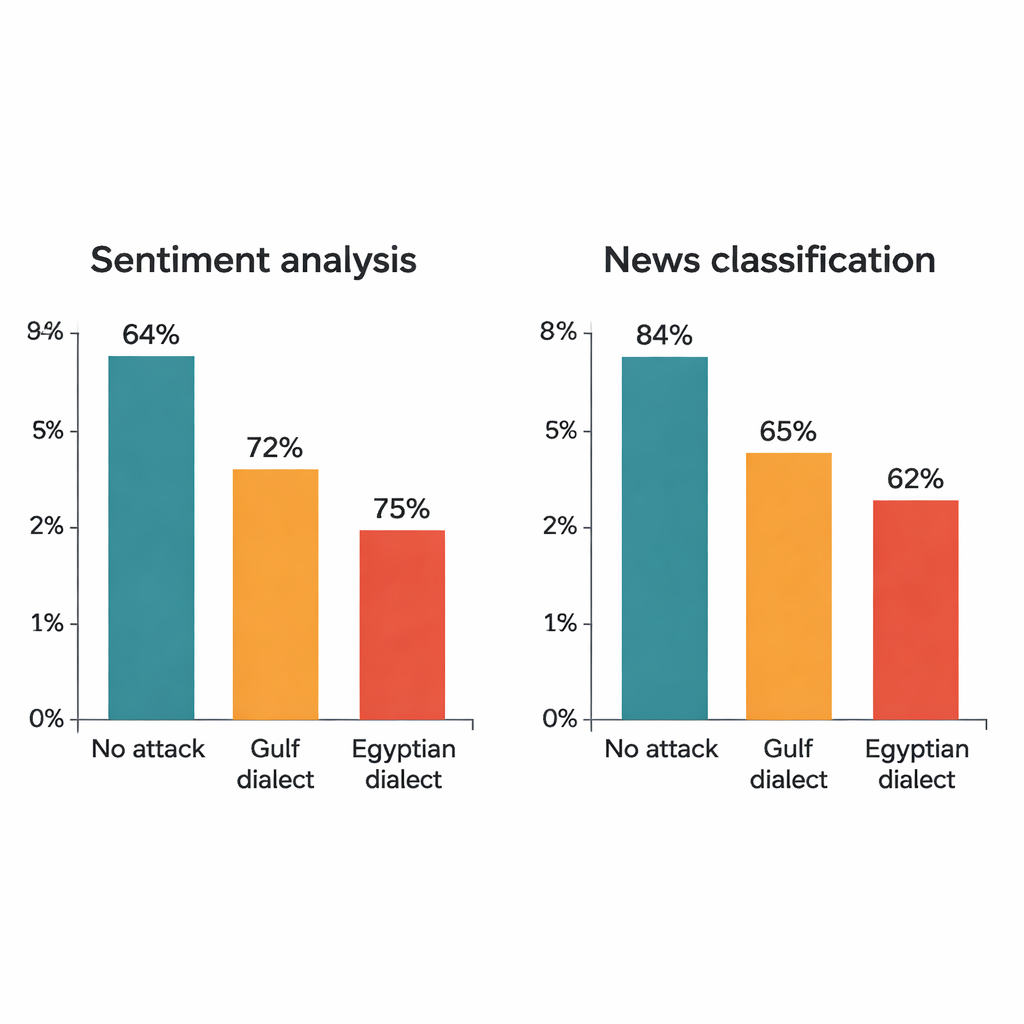
Vad som går fel inne i modellerna
En närmare granskning visar att de mest sårbara orden överensstämmer med hur människor faktiskt läser text. I hotellrecensioner är nästan hälften av de riktade orden adjektiv som ”bra” eller ”fruktansvärt”, vilka bär tydlig känslovikt. I nyhetsartiklar är de flesta utvalda orden substantiv och namn som signalerar ämnen som politik, sport eller ekonomi. När dessa trigger‑ord byts till dialektformer misslyckas modeller som tränats enbart på MSA ofta med att känna igen dem. Transformer‑modeller visar sig särskilt spröda: deras beroende av subword‑fragment och uppmärksamhet mot ett fåtal tungt viktade token gör att ett enda dialektord kan rucka en prediktion. Mindre modeller, som sprider uppmärksamheten mer jämnt över en mening, luras också men är något mer robusta.
Egyptiska kontra gulf: inte alla dialekter är lika
Attacken visar också att egyptisk arabiska tenderar att stjälpa modeller mer än gulf‑arabiska. Språkliga studier stödjer detta: gulf‑varianter håller sig ofta närmare MSA i ordförråd och struktur, medan egyptisk arabiska har upptagit fler distinkta former via historisk utveckling och språkkontakt. Som ett resultat liknar gulf‑ersättningar ibland MSA‑originalet nog för att modellen fortfarande ska klara av det, medan egyptiska ersättningar oftare ligger utanför vad modellen sett tidigare. Statistiska tester bekräftar att de observerade prestandafallen inte är slumpmässiga—de återspeglar systematiska blinda fläckar i hur nuvarande system hanterar arabisk diglossi.
Vad detta innebär för arabisk AI
För vardagsanvändare är slutsatsen enkel: dagens arabiska AI kan lätt förvirras av vanliga dialektord, även när människor uppfattar texten som helt tydlig. Ett enda dialektalt uttryck i en hotellrecension kan vända en modells bedömning från positiv till negativ eller felklassificera ett nyhetsämne. För forskare och utvecklare är budskapet en uppmaning att bygga ”diglossiavänliga” system som tränas på både MSA och regionala dialekter, och att använda realistiska stresstester såsom dialektalt utbyte när man bedömer robusthet. Fram till dess riskerar alla tillämpningar som antar att ”arabiska är bara MSA” allvarliga missförstånd i verkliga användningsfall.
Citering: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Nyckelord: Arabiska NLP, dialektal variation, adversariala exempel, sentimentanalys, textklassificering