Clear Sky Science · sv
Modifierad prioriterad DDPG-algoritm för gemensam beamforming och RIS-fasoptimering i MISO downlink-system
Smarta ytor för nästa våg av trådlöst
När våra telefoner, bilar och sensorer kräver allt snabbare och mer tillförlitliga förbindelser pressas dagens trådlösa nätverk till sina gränser. Denna studie undersöker ett nytt sätt att göra framtida 6G-nät både grönare och mer pålitliga genom att kombinera "smarta" reflekterande ytor på byggnader med en artificiell intelligensmetod som på egen hand lär sig styra radiosignaler med mindre energi.
Förvandla väggar till hjälpsamma signalspeglar
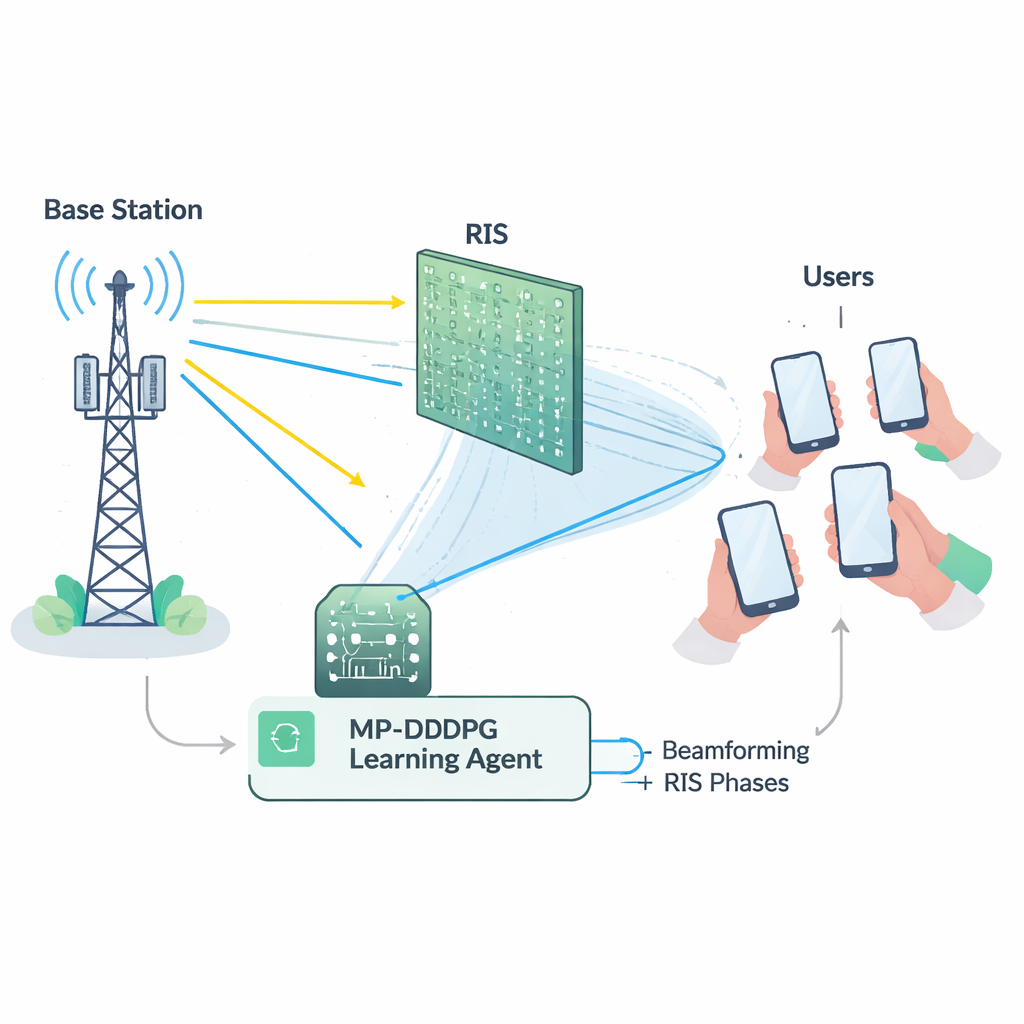
Framtida 6G-system måste betjäna stora mängder enheter med höga datahastigheter, stabil tillförlitlighet och mycket låg fördröjning. Att möta alla dessa krav med enbart traditionella basstationer skulle kräva mycket extra hårdvara och energi. Reconfigurable Intelligent Surfaces (RIS) erbjuder en annan väg: paneler täckta med många små, lågeffektselement som kan reflektera inkommande radiovågor i kontrollerade riktningar, som en programmerbar spegel. Genom att noggrant välja faserna för dessa reflektioner kan en RIS styra signaler runt hinder, förstärka svaga länkar och minska störningar, allt utan att aktivt sända egen effekt. Det ger nätverksdesigners en kraftfull ny ratt att vrida när man försöker utöka täckning och förbättra effektivitet.
En svår balansakt för nätverket
Att utnyttja en RIS väl är inte enkelt. Basstationen måste bestämma hur dess antenner ska riktas (beamforming), samtidigt som RIS måste ställa in fasen för var och en av sina många reflekterande element. Dessa val hänger tätt ihop och måste samtidigt uppfylla flera begränsningar: hålla den totala sändereffekten under ett maximum, garantera varje användare en miniminivå av signalkvalitet och respektera fysiska begränsningar hos RIS-hårdvaran. Matematiskt är detta gemensamma ställningsproblem starkt icke-linjärt och "icke-konvext", vilket innebär att konventionella optimeringsverktyg tenderar att vara långsamma, ömtåliga eller fastna i suboptimala lösningar, särskilt när nätverken blir större. Dessutom är det i verkliga implementationer kostsamt och feltåligt att mäta det detaljerade tillståndet för varje radiolänk (så kallad channel state information).
Låt en AI-agent lära sig beamforming
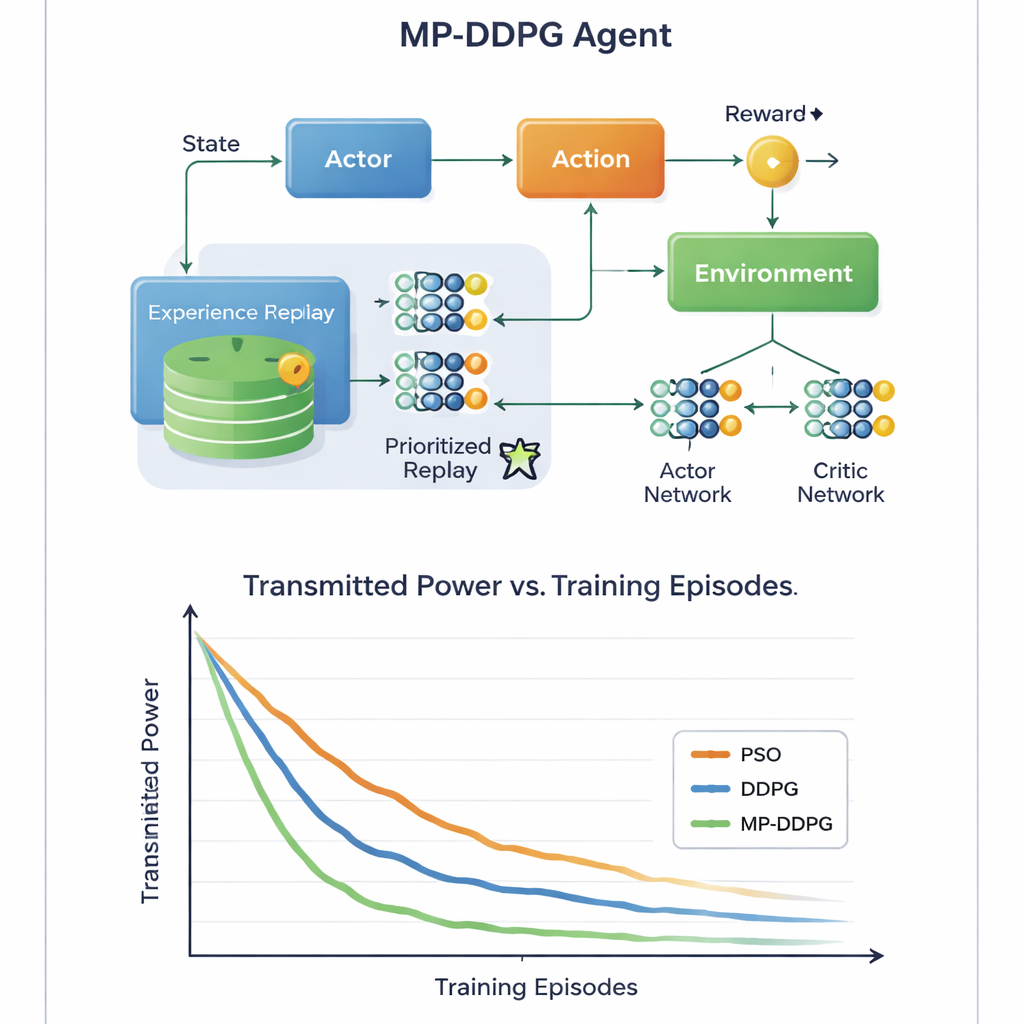
För att övervinna dessa hinder bygger författarna en lärande agent med djup förstärkningsinlärning, en gren av AI där en agent upptäcker bra strategier genom försök och misstag i en omgivning. Deras metod, kallad Modified Prioritized Deep Deterministic Policy Gradient (MP‑DDPG), observerar det aktuella nätverkstillståndet—tidigare bemyndigelser för beam, RIS-inställningar, mottagen effekt och signalkvalitet—och väljer sedan nya värden för beamforming och RIS-faser. Efter varje val får agenten en belöning som uppmuntrar tre saker samtidigt: lägre sändereffekt, uppfyllande av användarnas kvalitetskrav och efterlevnad av basstationens effektgräns. Genom många simulerade interaktioner lär sig agenten gradvis en styrpolicy som balanserar dessa mål utan att få någon explicit formel för radiokanalen.
Snabbare lärande genom att fokusera på det som betyder något
Den avgörande innovationen ligger i hur algoritmen lär sig från sina tidigare erfarenheter. Standardmetoder lagrar många tidigare situationer och provtar dem slumpmässigt under träning, vilket kan vara slösaktigt och långsamt. MP‑DDPG tilldelar istället varje sparad erfarenhet en prioritet som beror både på dess belöning och på hur olikt dess tillstånd är jämfört med närmaste grannar. Upplevelser som är både informationsrika och varierade provtas oftare, medan redundanta ignoreras. Denna "modifierade prioriterade replay" gör varje inlärningssteg mer användbart, påskyndar konvergensen och hjälper agenten att undvika dåliga lokala lösningar. Författarna analyserar också den extra beräkning som detta tillför och visar att även om bokföringen är mer komplex än i den grundläggande metoden så kompenserar det snabbare lärandet mer än väl i praktiken.
Grönare signaler med mindre hårdvara
Genom detaljerade datorsimuleringar av ett downlink-cellscenario jämför studien MP‑DDPG med två alternativ: en traditionell partikelstimuleringsoptimeringsmetod och den ursprungliga DDPG-inlärningsalgoritmen. Den nya metoden når konsekvent lägre sändereffekt på färre träningsavsnitt, och gör det med färre RIS-element och färre basstationsantenner för samma prestandanivå. I enkla termer lär sig nätverket att få mer nytta av varje reflekterande platta och varje antenn. För en allmän läsare är budskapet att genom att låta en AI-kontroller intelligensmässigt justera både basstationens strålar och de smarta ytorna på närliggande väggar kan framtida 6G-nät leverera starka, pålitliga signaler med mindre energi och mindre hårdvara, vilket bidrar till att göra vår alltmer uppkopplade värld mer hållbar.
Citering: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Nyckelord: omkonfigurerbar intelligent yta, 6G trådlöst, djup förstärkningsinlärning, beamforming-optimering, energieffektiva nätverk