Clear Sky Science · sv
Att integrera optimering och maskininlärning för att uppskatta vattnets resistivitet och mättnad i shaley-sand-reservoarer
Varför detta är viktigt för energi och miljö
Olje- och gasbolag förlitar sig på mätningar gjorda ner i en borrhål för att avgöra var kolväten döljer sig och om ett fält är värt att utveckla. I många reservoarer, särskilt de rika på lera och silt, är dessa mätningar notoriskt svåra att tolka, så ingenjörer kan underskatta hur mycket olja eller gas som faktiskt finns. Denna studie presenterar ett nytt sätt att pressa fram mer tillförlitlig information ur befintliga data genom att kombinera fysikbaserad optimering med modern maskininlärning, vilket potentiellt kan förbättra återvinningen samtidigt som behovet av kostsamma kärnprov minskar.
Problemet med leriga bergarter
Många av världens kolvätereservoarer är ”shaley sands” – blandningar av sandkorn, porvätskor och elektriskt ledande lermineral. Dessa leror förvränger elektriska mätningar som används för att uppskatta hur stor del av bergens porutrymme som är fylld med vatten jämfört med kolväten. Klassiska verktyg och diagram, utvecklade för renare sandar, antar enkla bergarters strukturer och lite lera. I shaley sands bryter dessa antaganden samman, vilket ofta får bergarterna att se våtare ut än de är och får ingenjörer att avskriva intervall som egentligen kan innehålla betydande mängder olja eller gas.
Att göra glesa mätningar till ett robust ankare
Författarna tar sig an en central storhet kallad formationens vattens resistivitet, som beskriver hur väl vattnet i porerna leder elektricitet. Om detta värde är fel, blir varje efterföljande uppskattning av vattenmättnad snedvriden. Istället för att förlita sig på några laboratoriemätningar eller subjektiva grafiska metoder formulerar de problemet som en optimeringsuppgift: hitta det enda värdet på vattens resistivitet som gör att en fysikbaserad shaley-sand-modell bäst matchar den resistivitet som mätts längs brunnen. De testar flera sökalgoritmer och visar att enkla, deriveringsfria metoder som Powell och Nelder–Mead kan återfinna den sanna vattens resistivitet med extremt liten felmarginal när de jämförs mot kärn- och vattenprovsdata från 11 brunnar i norska Nordsjön och Egyptens västra öken.
Skapa en ”pseudo-kärna” logg för maskininlärning
När denna optimerade vattens resistivitet är fastställd används samma fysiska modell för att beräkna en kontinuerlig profil av vattenmättnad längs varje brunn. Denna profil behandlas som en högkvalitativ, fysik-informerad etikett – en sorts ”pseudo-kärna” – som finns på varje djup, inte bara vid några provtagna intervall. Forskarna matar sedan in standardbrunnsloggar, såsom gamma-ray, neutron-porositet, densitet och djup resistivitet, i en mängd olika maskininlärningsmodeller. Dessa inkluderar trädensemblemetoder (Random Forest, XGBoost, CatBoost), supportvektormaskiner och flera neurala nätverksarkitekturer, inklusive ett särskilt rekurrent nätverk kallat LSTM som kan känna igen mönster som utvecklas med djupet. Noga förbehandling, avvikelsedetektering och normalisering hjälper till att säkerställa att modellerna lär sig verkliga geologiska samband snarare än brus.
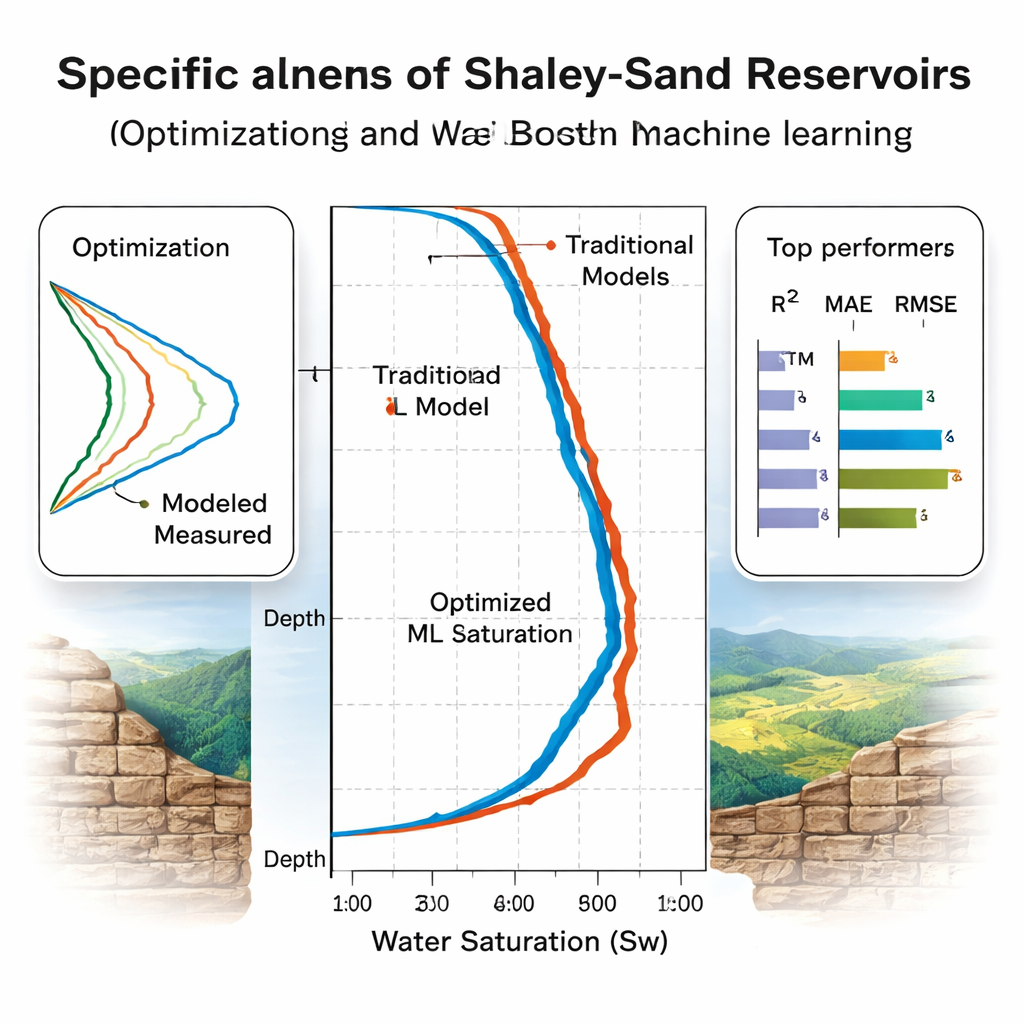
Vilka modeller generaliserar verkligen?
Teamet utvärderar modellerna i två steg. Först använder de femfaldig korsvalidering på åtta Nordsjöbrunnar för att finjustera och rangordna dem, och finner att Random Forest verkar vinna på standardmått för noggrannhet. Därefter följer det mer avslöjande testet: tre ”blinda” brunnar, inklusive två från ett geologiskt annorlunda egyptiskt bassäng som aldrig användes i träningen. Här snubblar vissa modeller. Random Forests prestanda faller, vilket signalerar överanpassning till den ursprungliga bassängen. I kontrast bibehåller gradientförstärkta träd (CatBoost och XGBoost) samt LSTM och bayesiskt regulariserade neurala nätverk hög noggrannhet, och förklarar över 93–94 % av variationen i vattenmättnad med måttliga fel. Analys av variabelbetydelse med SHAP, ett modernt tolkningsverktyg, bekräftar att modellerna lutar mest mot fysiskt meningsfulla indata som resistivitet, porositet och shaley-volym.
Vad detta betyder i klarspråk
För icke-specialister är huvudidén att författarna först använder fysik för att rensa upp och ankra problemet, och först därefter släpper lös maskininlärning. Genom att låta en optimeringsrutin hitta den bästa passande vattens resistivitet och sedan förvandla det till en tät, fysikrespektfull träningsuppsättning undviker de den vanliga flaskhalsen med knapp och dyr kärndata. Deras resultat visar att detta ”först optimering, sedan ML”-angreppssätt kan leverera tillförlitliga uppskattningar av hur mycket av ett shaley-reservoar som är fyllt med vatten jämfört med kolväten, även i nya bassänger som inte användes för träning. I praktiska termer kan detta hjälpa operatörer att kartlägga betalande zoner mer pålitligt, minska onödig kärnprovtagning och förbättra uppskattningar av kolväten på plats – allt genom att göra smartare användning av data de redan samlar in.
Citering: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Nyckelord: shaley sand-reservoarer, vattenmättnad, formationens vattens resistivitet, maskininlärning inom petrofysik, reservoarkarakterisering