Clear Sky Science · sv
Uppmärksamhetsstyrd spatio-temporalt fusions av funktioner för robust avvikelsedetektion i videoövervakning
Varför smartare kameror spelar roll
Från livliga tågstationer till köpcentrum är det moderna livet fullt av säkerhetskameror som tyst spelar in allt som händer. Ändå granskas de flesta av dessa videor fortfarande—om de alls ses—av trötta mänskliga ögon som lätt kan missa ett avgörande ögonblick. Denna artikel undersöker en ny typ av "smart" övervakningssystem som automatiskt kan upptäcka ovanligt eller riskfyllt beteende, såsom stöld eller vandalisering, i realtid genom att förstå både vad som syns i en scen och hur det förändras över tid.

Se mer än pixlar
En traditionell kameraflöde är bara en sekvens bilder. Äldre datorsystem försökte upptäcka problem genom att analysera varje bildruta separat, leta efter former och kanter som liknade människor eller föremål. Författarna testar först en modern version av denna idé som använder ett kompakt bildigenkänningsnätverk kombinerat med klassiska kantdetektorer. Denna uppställning fungerar ganska bra i prydligt inramade scener, särskilt för att märka tydliga visuella signaler som när någon tar ett föremål. Men eftersom den fokuserar på enstaka ögonblicksbilden har den svårt när människor skymmer varandra, när folkmassor blir täta, eller när samma kroppshållning kan betyda antingen normalt eller misstänkt beteende beroende på hur det utvecklas över tid.
Förstå rörelse och beteende
För att fånga berättelsen bakom en handling, inte bara utseendet i en enskild ruta, utvärderar studien sedan en modell fokuserad på video som analyserar korta klipp i stället för stillbilder. Denna modell lär sig hur rörelse flyter över flera rutor och kan bättre identifiera plötsliga förändringar som löpning, slagsmål eller ryckande. Den visar sig bra på att fånga många onormala händelser, vilket ger hög känslighet. Den lider dock också av ett klassiskt problem i verkliga situationer: verkligt ovanliga händelser är sällsynta jämfört med vardaglig aktivitet. Som ett resultat kan modellen bli instabil, ge för många falsklarm och kräva noggrant förklippta videosekvenser som inte speglar den röriga, kontinuerliga naturen hos verklig övervakningsfilm.
Blanda var och när
Byggt på styrkorna och svagheterna hos dessa två baslinjer föreslår författarna ett nytt hybridssystem kallat HybridModel-1 som syftar till att "tänka" både i rum och tid samtidigt. Det kombinerar ett nätverk som är mycket bra på att förstå vilka objekt som finns i varje bildruta med en snabb detektor som lokaliserar dessa objekt i scenen. En särskild fusionsmodul lär sig att betona de mest informativa visuella detaljerna—såsom människor och nyckelföremål—samtidigt som bakgrundsbrus som väggar, träd eller passerande bilar nedtonas. Samtidigt straffar en ny träningsstrategi försiktigt systemet när dess förtroende hoppar kraftigt mellan rutor, vilket styr det mot mjukare, mer konsekventa beslut över en hel video.
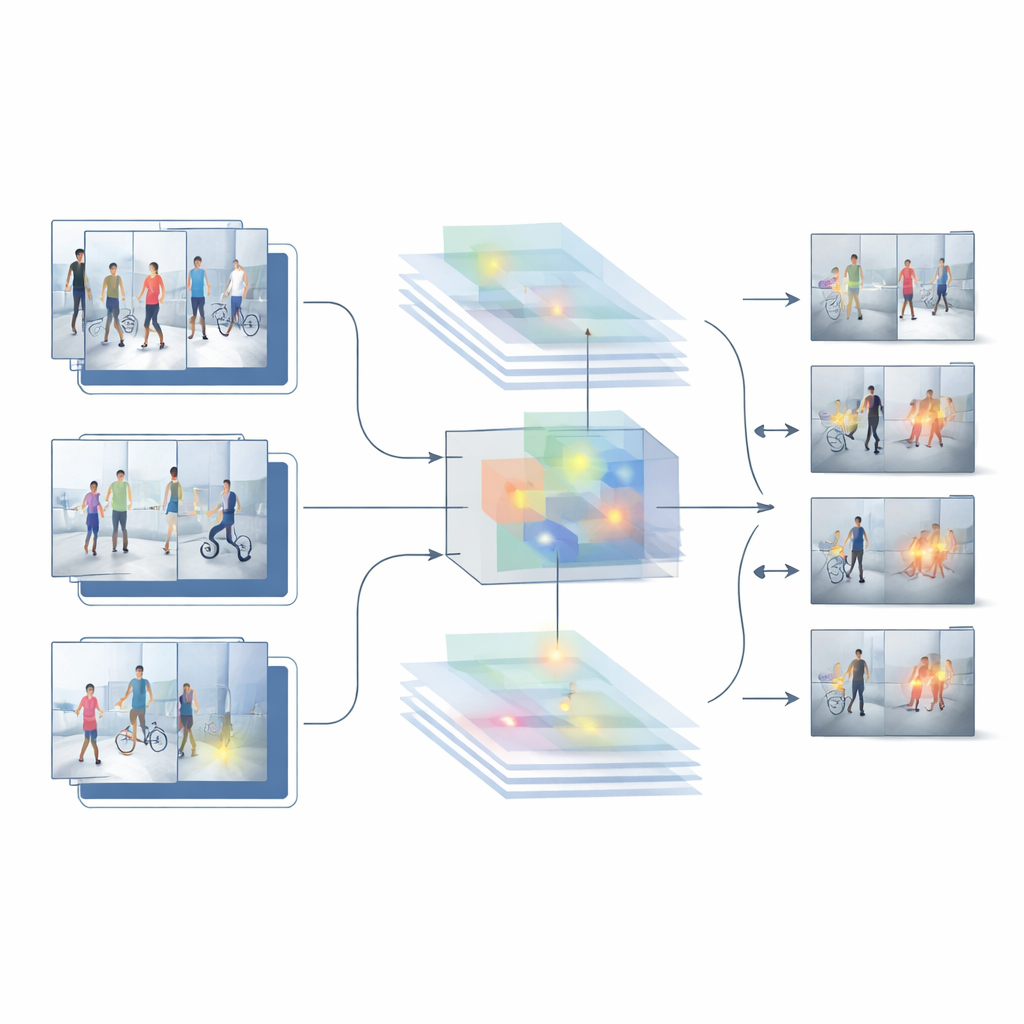
Sätta systemet på prov
För att se om denna design fungerar utanför laboratoriet testar forskarna den på flera utmanande publika dataset med verklig övervakningsfilm. Dessa samlingar inkluderar allt från inomhusscener med stöld till utomhusgångar på campus, med varierande kameravinklar, belysning, folkmängder och typer av incidenter. Över dessa referensmätningar överträffar hybridmodellen både bild- och videoendimensionella baslinjer. Den uppnår högre total noggrannhet, ger betydligt färre falsklarm och bibehåller stark prestanda även när den utvärderas på material den inte tränats på. Detaljerade jämförelser och ablation-studier—där delar av systemet tas bort eller förändras—visar att fusionsmodulen för funktioner och träningssteget med fokus på jämnhet vardera bidrar meningsfullt till dessa förbättringar.
Vad detta betyder för vardaglig säkerhet
Enkelt uttryckt visar detta arbete att övervakningssystem blir mer tillförlitliga när de lär sig uppmärksamma de rätta delarna av en scen och förbli stabila i sina bedömningar över tid. Istället för att behandla varje ruta som en isolerad bild eller förlita sig enbart på rå rörelse blandar den föreslagna metoden "vad" och "när" i ett enda, noggrant finjusterat ramverk. Utmaningar kvarstår i extremt mörka eller kraftigt skymda vyer, men resultaten pekar på en praktisk väg mot kamerasystem som tyst kan granska stora mängder video, lyfta fram verkligt misstänkta händelser och minska bördan av falsklarm för mänskliga operatörer. För allmänheten kan det innebära tryggare miljöer övervakade av system som inte bara tittar, utan verkligen förstår vad de ser.
Citering: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Nyckelord: videoövervakning, avvikelsedetektion, smarta kameror, brottsdetektion, maskininlärning