Clear Sky Science · sv
Integrering av random forest-baserad regressionskrigging för att analysera rumslig variabilitet i nederbörd i torra och halvtorra regioner
Varför det är viktigt att kartlägga regn i torra områden
I länder där vatten är knapp kan kunskap om exakt var och när det regnar vara skillnaden mellan livsmedelssäkerhet och kris. Pakistan omfattar berg, öknar och bördiga slätter, och nederbörden har blivit mer ojämn under klimatförändringen. Samtidigt är markbaserade väderstationer få och glesa. Denna studie ställer en praktisk fråga: med begränsade data, kan moderna maskininlärningsmetoder i kombination med klassiska kartläggningstekniker ta fram skarpare, mer tillförlitliga nederbördskartor för att vägleda jordbruk, översvämningsplanering och vattenförvaltning?
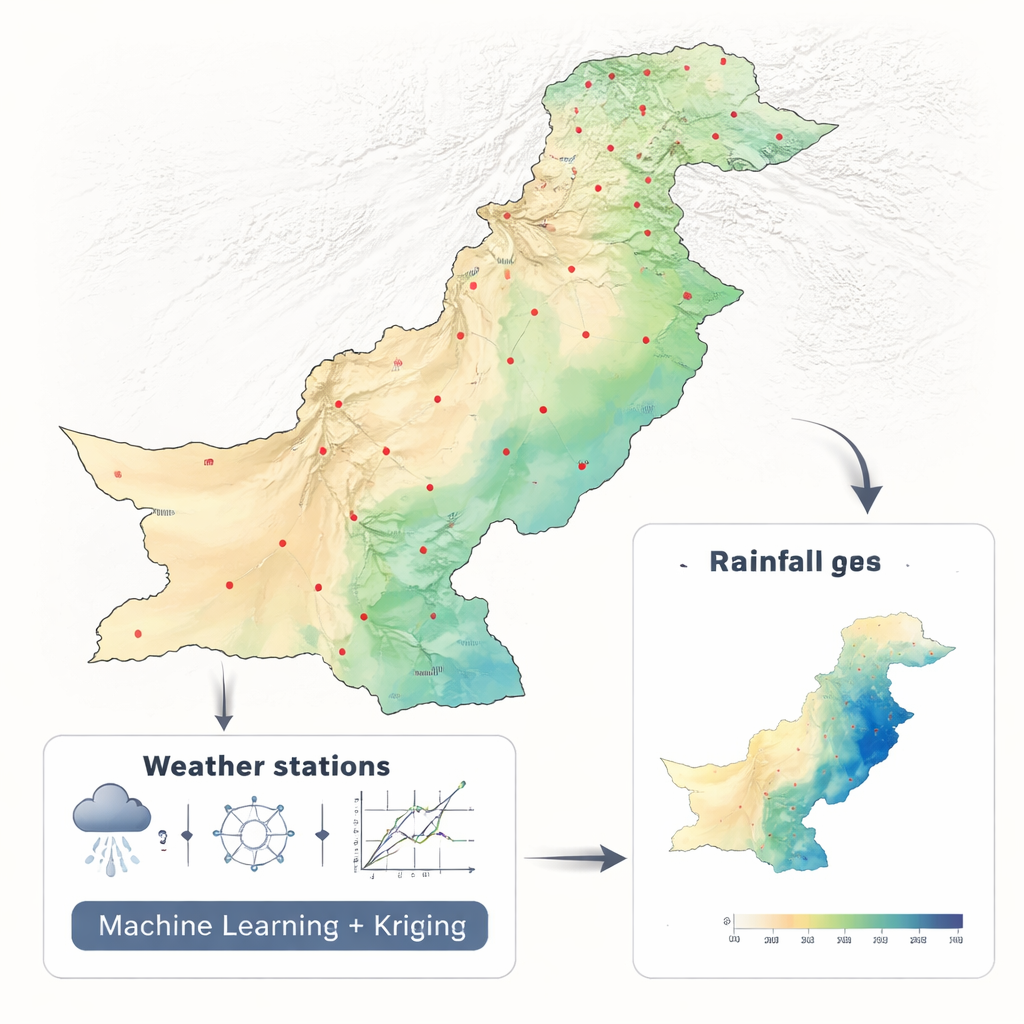
Att omvandla spridda regnmätningar till fullständiga kartor
Forskarna arbetade med två decennier av månatliga nederbördsdata (2001–2010 och 2011–2021) från 42 stationer över Pakistan, och använde en konsekvent klimatdatamängd från NASA. Istället för att mata ett dussin miljövariabler in i en komplex modell använde de medvetet endast latitud och longitud. Denna avskalade design gjorde det möjligt att fokusera på en central fråga: vilken matematisk metod bäst förvandlar spridda punktmätningar till en kontinuerlig karta. De jämförde sex maskininlärningsmetoder — Random Forest, Support Vector Machine, K-Nearest Neighbors, Neural Network, Elastic Net och Polynomial Regression — där varje metod användes i ett ramverk kallat regressionskrigging som är vanligt i geovetenskaperna.
Att blanda storskaligt lärande med rumslig intuition
Regressionskrigging fungerar i två steg. Först förutsäger en regressionsmodell nederbörden på vilken plats som helst utifrån dess koordinater och fångar upp breda mönster såsom fuktigare berg och torrare öknar. Därefter fyller en rumslig metod kallad krigging i de kvarstående, lokala skillnaderna mellan observationer och modellens förutsägelser. För att göra det andra steget pålitligt studerade teamet först hur lika eller olika nederbörden var mellan par av stationer vid olika avstånd — ett verktyg kallat variogram. De fann att enkla ”cirkel” och ”linjära” matematiska former bäst beskrev hur nederbördslikheten avtar med avstånd över årstiderna och mellan de två decennierna, ett tecken på jämna, regionomfattande regnsystem snarare än plötsliga hopp.
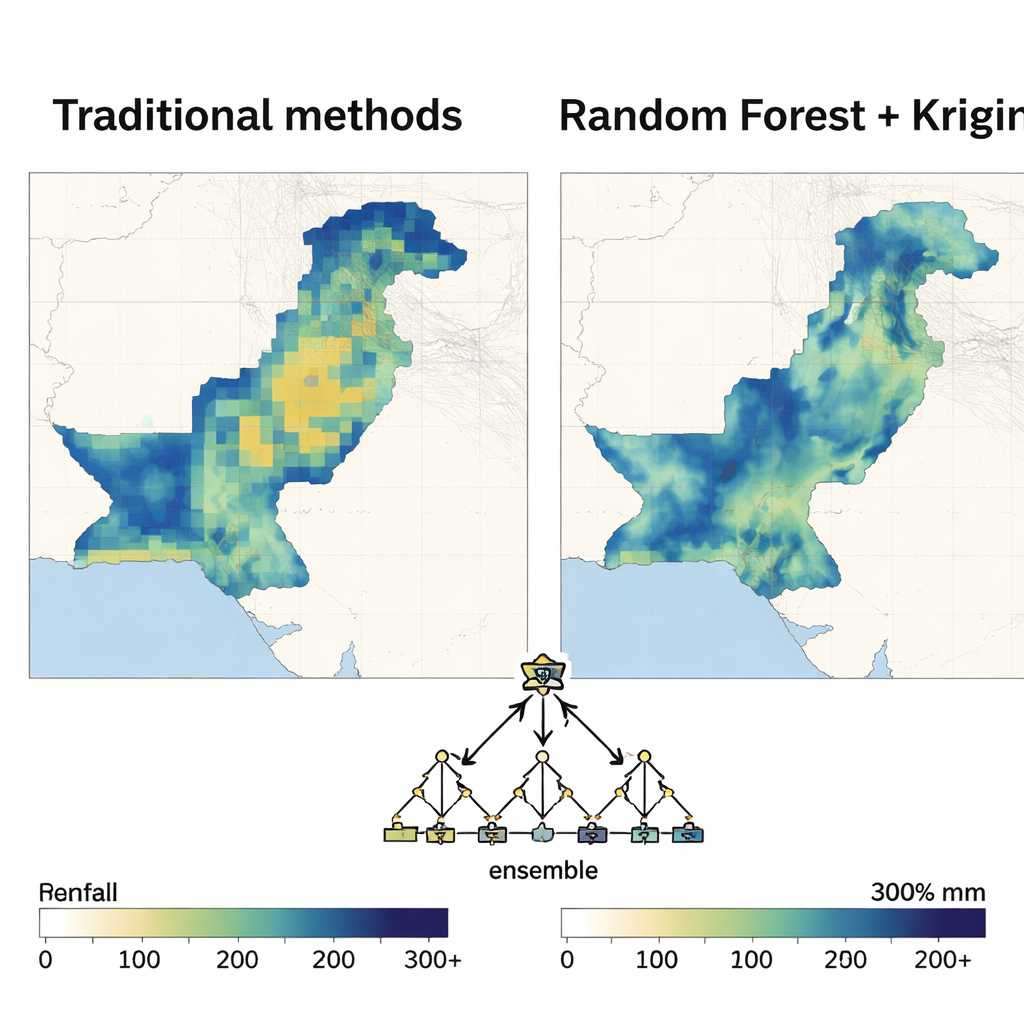
Random Forest framträder som ledaren
När den rumsliga strukturen väl var kartlagd fick varje maskininlärningsmetod turas om att vara regressionsmotor i den hybrida modellen. Författarna bedömde prestanda med standardmått för fel och hur stor del av nederbördens variation modellen kunde förklara. I nästan alla månader och båda decennierna gav Random Forest–baserade tillvägagångssätt de mest korrekta och stabila kartorna. Det minskade prognosfelen avsevärt jämfört med polynomisk regression och slog konsekvent supportvektormaskiner, neurala nätverk och andra metoder, särskilt under monsunsäsongen då nederbörden är som kraftigast och mest varierande. De framställda kartorna var släta där de borde vara det, men fångade ändå skarpa kontraster mellan torra och våta zoner, med relativt låg osäkerhet.
Vad förändrade nederbördsmönster avslöjar
Genom att jämföra de två decennierna såg studien också tecken på skiftande nederbördsmönster. I genomsnitt var det senare decenniet (2011–2021) våtare, med större månad-till-månad- och plats-till-plats-variabilitet, särskilt på våren och under monsunperioden. Den rumsliga strukturen i nederbörden blev mer utspridd, vilket tyder på bredare svängningar i var vattnet levereras. Viktigt är att Random Forest–krigging-kombinationen klarade både den tidigare, något mildare klimatperioden och den mer varierade senare perioden utan att tappa noggrannhet, vilket antyder att sådana flexibla verktyg passar väl för en varmare och mindre förutsägbar värld.
Från kartor till beslut i verkligheten
I praktiska termer visar artikeln att intelligenta algoritmer kan utvinna mer värde ur begränsade nederbördsregister och producera högupplösta kartor som är användbara även i dataskra regioner. För Pakistan kan dessa kartor stödja bättre planering av bevattning, reservoarhantering och översvämningsskydd, samt hjälpa till att identifiera samhällen som är mest utsatta för torka eller kraftiga regn. Författarna betonar att deras arbete är ett konceptbevis fokuserat på kartläggningsteknikerna i sig, inte ännu ett fullständigt varningssystem för översvämningar eller torka. Slutsatsen är ändå tydlig: att kombinera ensemble-baserad maskininlärning, ledd av Random Forest, med geostatistisk kartläggning erbjuder ett kraftfullt, praktiskt sätt att följa hur nederbörden förändras i torra och halvtorra områden runt om i världen.
Citering: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Nyckelord: nederbördskartläggning, random forest, regressionskrigging, Pakistans klimat, vattenresurser