Clear Sky Science · sv
Maskininlärningsförutsägelse av soniska loggar mellan borrhål i Newfoundland och Labrador
Lyssna på berg utan mikrofon
Olje- och gasbolag använder akustiska "soniska" verktyg för att höra hur ljudvågor färdas genom berg under jord. Dessa detaljerade mätningar hjälper ingenjörer att bedöma bergens styrka, planera säkra brunnar och matcha borrningsdata med seismiska undersökningar. Men soniska verktyg är dyra, kan bromsa operationer och kan ibland inte användas alls. Denna studie visar hur maskininlärning kan rekonstruera sonisk information från billigare, rutinmässigt insamlade mätningar och därmed erbjuda ett sätt att "höra" underlagret även när mikrofonen saknas.
Varför det är viktigt att förutsäga soniska data
Vid offshoreborrning registrerar operatörerna många typer av brunnsloggar: naturlig radioaktivitet, borrhastighet, pumpflöde, belastning på borrkronan med mera. Soniska loggar är speciella eftersom de visar hur snabbt ljudet färdas genom berg, en nyckelingång för att uppskatta bergstelhet, tryck och spänning. När soniska verktyg saknas måste ingenjörer antingen hantera luckor eller förlita sig på grova tumregler. Genom att använda maskininlärning för att omvandla vanliga icke-soniska loggar till korrekta "pseudo-soniska" kurvor kan företag minska kostnader för datainsamling, fylla igen saknade sektioner och ändå fatta välgrundade beslut om brunnsstabilitet och reservoarens beteende.
En noggrann metod för att undvika fusk
Författarna arbetade med data från två offshorebrunnar i Newfoundland och Labrador. För varje djup försökte de förutsäga kompressionslångsamhet (ett sätt att uttrycka hur lång tid en ljudvåg tar att färdas genom berg) med hjälp av endast icke-soniska mätningar. Avgörande var att de förbjöd all input som direkt eller indirekt använde soniska data, såsom härledda elastiska egenskaper. De byggde också funktioner med information endast från samma djup eller grundare nivåer, vilket efterliknar realtidsborrning där framtiden är okänd. Avvikande mätvärden i sensorerna identifierades med statistik från endast en "tränings"-brunn och hanterades sedan likadant i båda brunnarna, vilket säkerställde att modellerna inte tyst kunde lära sig från testdata. All skalning och val av funktioner fastställdes också på träningsbrunnen innan de tillämpades, oförändrade, på den andra brunnen.
Att omvandla råa loggar till inlärningsbara signaler
Att bara mata råa loggar till en algoritm räcker sällan. Teamet konstruerade ett rikt set av djupmedvetna funktioner: de följde hur varje logg förändrades med djupet, glättade brusiga signaler i flera skalor och beräknade lutningar och kurvaturer som framhäver lokala trender. De uttryckte också djup relativt till hålsektioner, för att fånga mönster som upprepar sig när borrkronans storlek ändras. För att förhindra att modellerna överväldigas rankade de funktioner med tre olika metoder och kombinerade rankningarna till en enda ordnad lista. En kompakt grupp av de mest informativa funktionerna valdes sedan med en tidsmedveten uppdelning inom träningsbrunnen, så att urvalsprocessen i sig respekterade den naturliga ordningen med djup.
Trädmodeller slår deep learning
Studien jämförde tre typer av modeller: Random Forests, XGBoost (en populär gradient-boostingmetod) och bidirektionella LSTM-neuronnät, som ofta används för sekvensdata. Varje modell tränades på en brunn och testades blindat på den andra, en krävande uppställning som blottlägger skillnader mellan brunnarna i djupintervall, driftförhållanden och bergarter. Under detta test presterade XGBoost bäst och uppnådde hög överensstämmelse mellan förutsagda och uppmätta soniska loggar när den tränades på den första brunnen och tillämpades på den andra. Random Forests kom tätt efter och var ibland mer stabila i brusiga zoner. LSTM-nätverk, trots sin komplexitet, halkade efter både i noggrannhet och robusthet — troligen eftersom det bara fanns två brunnar och data varierade starkt med djup, förhållanden som inte gynnar stora neurala nät.
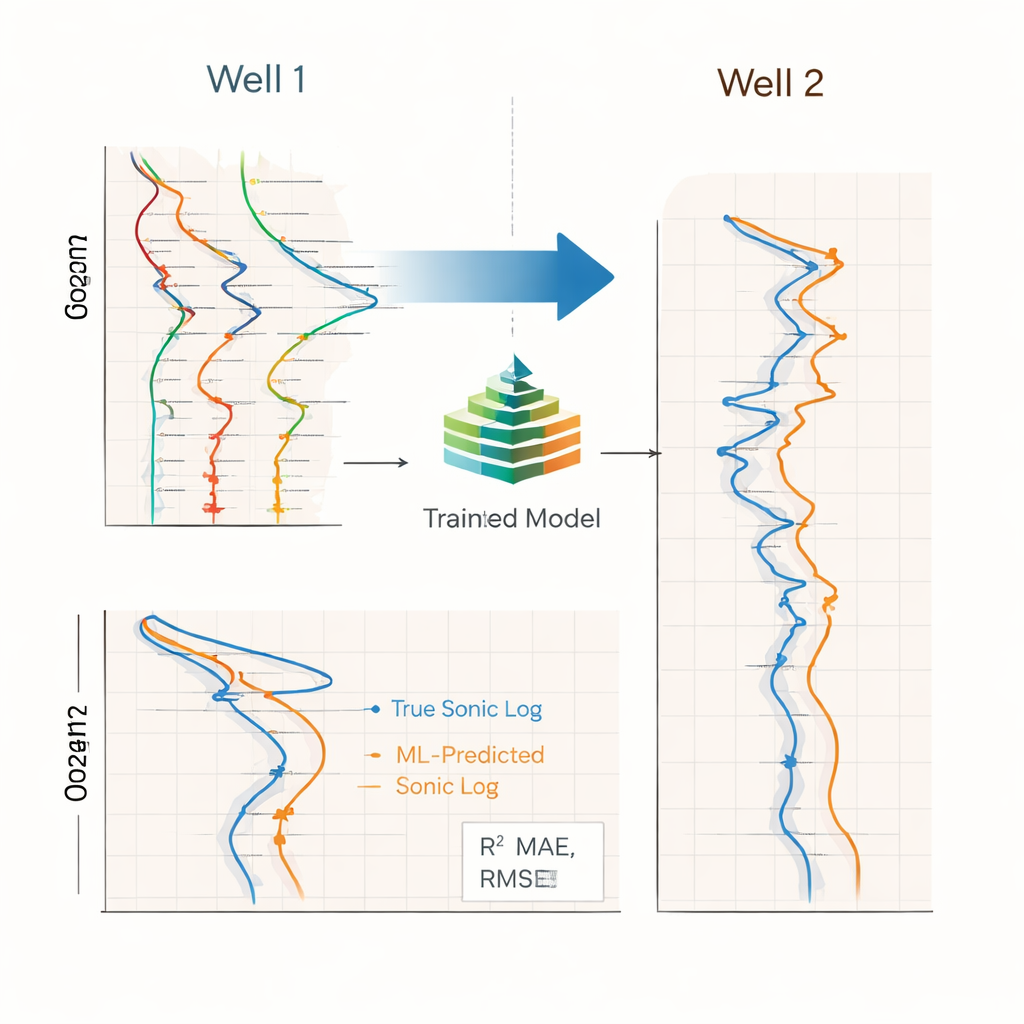
Vad som driver noggrannheten och var det hjälper
Genom att växla olika delar av sin förbehandling visade författarna att smart funktionell generering och urval gjorde störst skillnad för prestandan, mer än att bara lägga till längre historikfönster eller enkel avvikelsefiltrering. När dessa steg ingick generaliserade båda träd-baserade modeller mycket bättre över brunnar. De resulterande pseudo-soniska loggarna var tillräckligt precisa för att stödja efterföljande uppgifter såsom uppskattning av bergstelhet, modellering av portryck och spänning, kalibrering av seismiska data och planering av brunnar i zoner där direkta soniska mätningar saknas, är fördröjda eller opålitliga. Eftersom alla transformationer fixeras på en referensbrunn och sedan återanvänds, kan arbetsflödet fungera nästan i realtid under borrning.
Huvudbudskap för icke-specialister
Detta arbete visar att med disciplinerad datahantering och väl valda maskininlärningsmodeller är det möjligt att återskapa värdefull sonisk information från billigare borr- och loggkanaler i en ny brunn som modellen aldrig sett tidigare. Metoden ersätter inte dedikerade soniska verktyg, särskilt där säkerhetsmarginalerna är små, men den erbjuder ett praktiskt och kostnadseffektivt reservalternativ samt en kvalitetskontroll när uppmätta data verkar misstänksamma. När fler brunnar och regioner läggs till och nyare modeller testas under samma strikta regler kan denna typ av förutsägelse mellan brunnar bli en standarddel av den digitala verktygslådan för säkrare och mer effektiv offshoreborrning.
Citering: Zare, B., Huque, M.M., James, L.A. et al. Cross-well machine learning prediction of sonic logs in Newfoundland and Labrador. Sci Rep 16, 5292 (2026). https://doi.org/10.1038/s41598-026-36053-9
Nyckelord: maskininlärning, soniska loggar, brunnsloggning, offshoreborrning, reservoarkarakterisering