Clear Sky Science · sv
Självövervakad inlärning på grafer förutsäger samband mellan icke-kodande RNA och sjukdomar
Varför gömt RNA spelar roll för vår hälsa
De flesta av oss lärde oss att RNAs huvudsakliga uppgift är att hjälpa till att bygga proteiner. Men under det senaste decenniet har forskare upptäckt ett stort antal ”icke-kodande” RNA som aldrig blir proteiner men ändå hjälper till att styra hur våra celler fungerar. Många av dessa molekyler är nu kända för att driva eller hämma cancer och andra komplexa sjukdomar. Att ta reda på vilka icke-kodande RNA som är kopplade till vilka sjukdomar kan avslöja nya sätt att tidigt diagnosticera sjukdom eller utforma mer precisa behandlingar — men att testa varje möjlighet i laboratoriet skulle vara omöjligt långsamt. Denna studie presenterar en kraftfull datorbaserad metod som kan sålla igenom enorma biologiska nätverk och pålitligt föreslå de mest lovande RNA–sjukdomskopplingarna för forskare att kontrollera i experiment.
Från skräp till nyckelspelare i cellen
Under åratal avfärdades icke-kodande RNA som meningslösa rester av genaktivitet. Vi vet nu att familjer som mikroRNA, långa icke-kodande RNA och cirkulära RNA hjälper till att orkestrera viktiga processer, från paketering av DNA till att slå på och av gener och vidarebefordra signaler inom celler. Eftersom de sitter på så många kontrollpunkter kan även små förändringar i dessa RNA rubba balansen mot cancer eller andra sjukdomar. Kliniker har redan börjat se dem som potentiella biomarkörer och läkemedelsmål. Utmaningen är omfattningen: det finns tusentals olika RNA och hundratals sjukdomar, och traditionella experiment för att testa varje möjlig koppling är dyra och tidskrävande. Där kommer beräkningsprediktion in som ett sätt att begränsa sökområdet.
Hur man läser ett biologiskt nätverk
Tidigare datorbaserade metoder försökte förutsäga RNA–sjukdomskopplingar genom att dela upp stora datatabeller i enklare delar eller genom att träna maskininlärningsmodeller på kända exempel. Dessa tillvägagångssätt hjälpte, men de ignorerade ofta hur RNA och sjukdomar är vävda ihop i nätverk. Moderna ”grafneurala nätverk” behandlar RNA och sjukdomar som punkter förbundna med linjer, ungefär som ett socialt nätverk. De kan lära sig mönster i vem som är kopplad till vem. Dock kräver de flesta av dessa grafmetoder många tillförlitliga träningsexempel och mängder av noggrant framtagna indatafunktioner. Det gör dem känsliga för saknade data, brusiga mätningar och överanpassning — de presterar bra på känd data men misslyckas när de ska förutsäga nya samband.
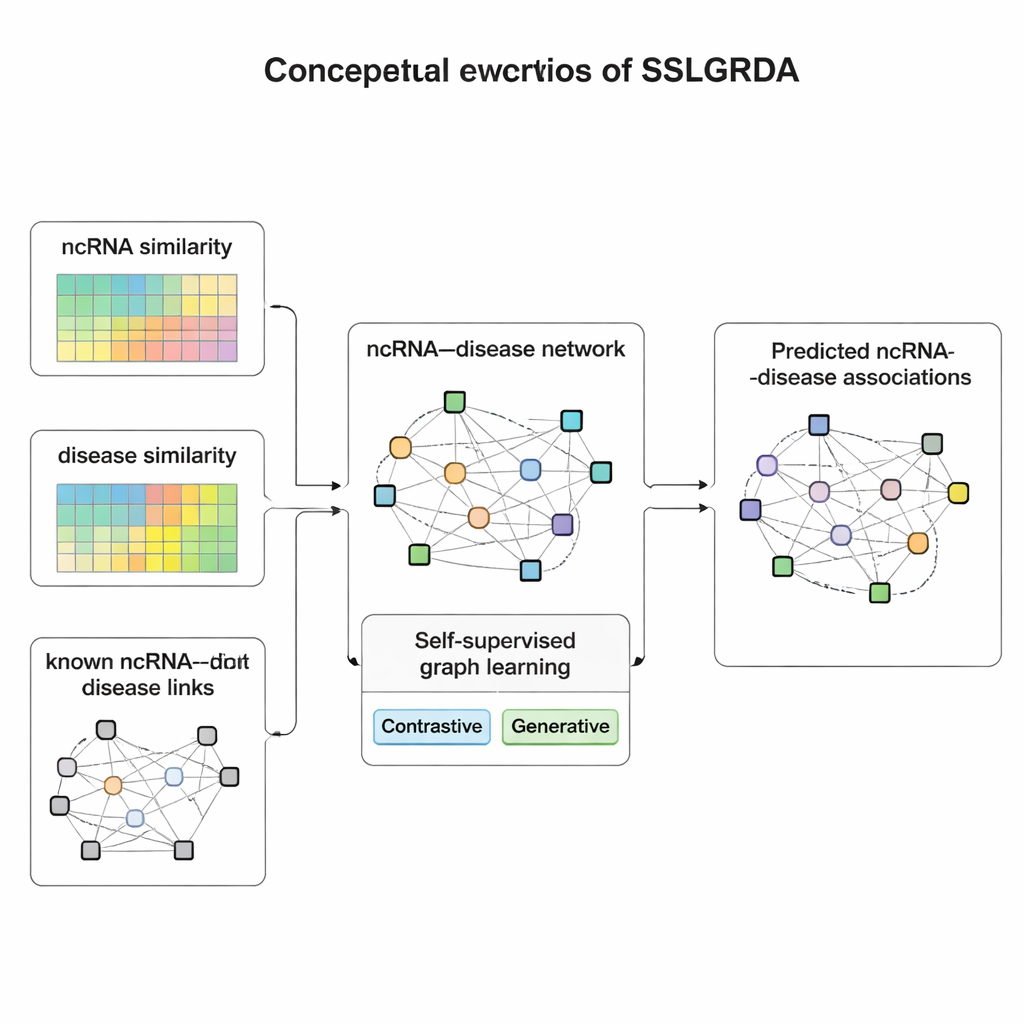
Lärande från data själva
Författarna presenterar SSLGRDA, ett nytt ramverk som lär en grafmodell att hitta användbara mönster utan att i hög grad förlita sig på märkta träningsdata. Nyckelidén är ”självövervakad inlärning”: i stället för att få veta vilka RNA som hör ihop med vilka sjukdomar uppfinner modellen sina egna övningsuppgifter enbart baserade på nätverkets struktur och attribut. Forskarna bygger två typer av grafer. Den ena behåller RNA och sjukdomar som olika nodtyper förbundna av kända länkar. Den andra förenar dem till ett enda stort nätverk som också inkluderar likhetsinformation — hur lika två RNA eller två sjukdomar är — så att även glest förbundna objekt får stödjande grannar. Ovanpå dessa grafer använder SSLGRDA två stilar av självträning. Kontrastiva strategier ber modellen att känna igen att olika ”vyer” av samma nod (till exempel dess kopplingar kontra dess attribut) bör leda till liknande interna representationer, samtidigt som den tydligt separerar orelaterade noder. Generativa strategier döljer medvetet delar av indatafunktionerna och utmanar modellen att rekonstruera dem, vilket uppmuntrar den att fånga djupare struktur i stället för att memorera brus.
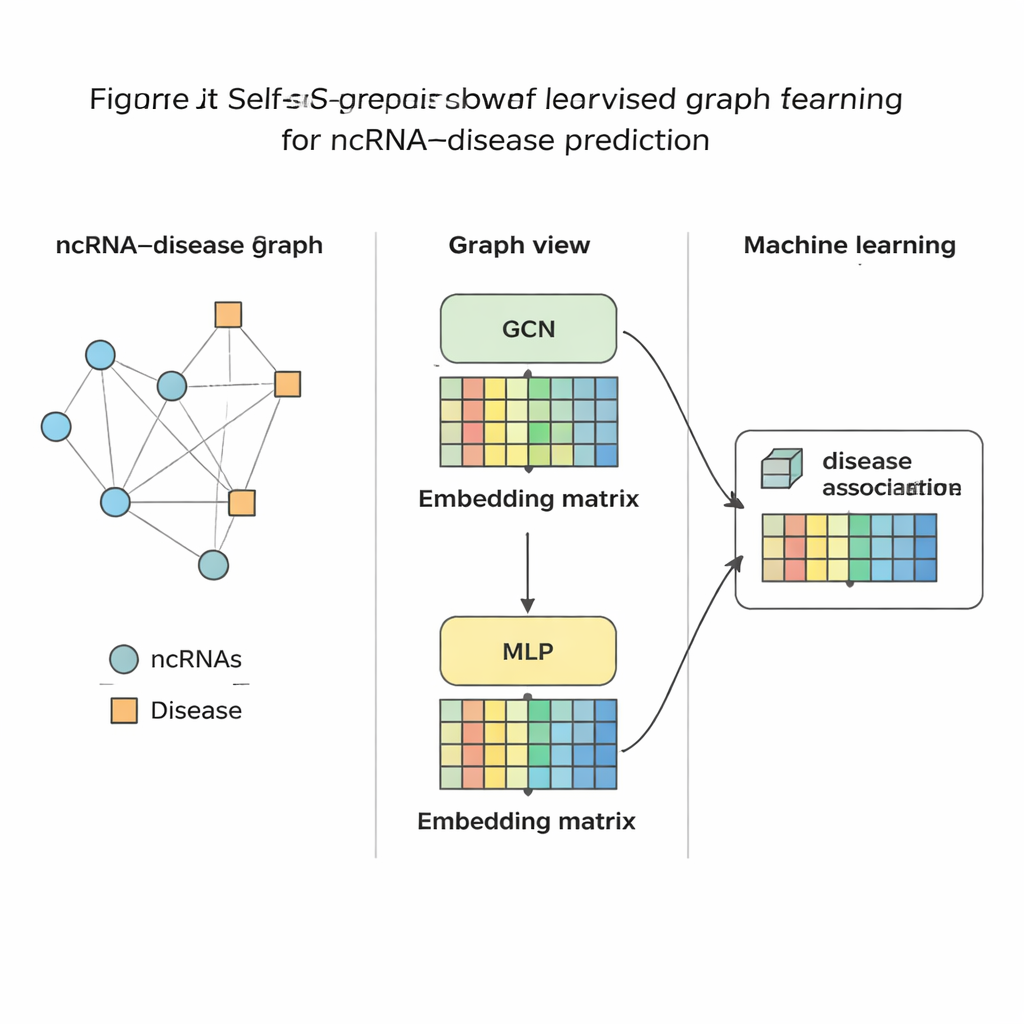
Att testa metoden
När SSLGRDA har destillerat varje RNA och sjukdom till ett kompakt numeriskt fingeravtryck tränas en standard maskininlärningsklassificerare för att bedöma om en länk mellan dem är sannolik eller inte. Författarna utvärderade detta angreppssätt på nio olika dataset som täcker tre stora RNA-typer och hundratals sjukdomar. Överlag presterade deras kontrastiva självövervakade varianter på den sammanslagna (homogena) grafen bäst och slog en rad befintliga verktyg, inklusive starka grafbaserade jämförelser. Metoden uppnådde inte bara högre noggrannhet i globala tester utan rankade också rätt partner högt när man fokuserade på ett RNA eller en sjukdom i taget — avgörande för verklig användning där en biolog kan börja med en enskild cancer och fråga vilka RNA som bör studeras. De visade dessutom att samma idéer överförs väl till andra biomedicinska nätverk, såsom de som kopplar mikrober till sjukdomar eller läkemedel.
Från prediktioner till potentiella terapier
För att demonstrera praktiskt värde applicerade teamet SSLGRDA för att söka efter nya icke-kodande RNA inblandade i bröstcancer, koloncancer och flera andra tillstånd. Många av de högst rankade förslagen bekräftades senare i oberoende databaser eller vetenskapliga rapporter, vilket stöder modellens förmåga att upptäcka biologiskt meningsfulla mönster. För icke-specialister är slutsatsen att detta arbete erbjuder ett smartare sätt att utvinna ledtrådar om sjukdomar ur den ständigt växande mängden biologiska data. Genom att automatiskt lära hur RNA och sjukdomar klustras och interagerar kan självövervakade grafmetoder som SSLGRDA vägleda laboratorieforskare mot de mest lovande målen, vilket potentiellt snabbar upp vägen från rådata till bättre diagnostik och behandlingar.
Citering: Wu, Q., Tang, S. Self-supervised learning on graphs predicts non-coding RNA and disease associations. Sci Rep 16, 5231 (2026). https://doi.org/10.1038/s41598-026-36030-2
Nyckelord: icke-kodande RNA, sjukdomssamband, grafneurala nätverk, självövervakad inlärning, beräkningsbiologi