Clear Sky Science · sv
Den multiparameteroptimerade belief rule base för att förutsäga elevers prestationer med tolkbarhet
Varför betygsprognoser angår alla
Betygsblad kan se enkla ut, men krafterna som formar en elevs betyg är allt annat än det. Skolor vänder sig i allt högre grad till datorbaserade modeller för att i ett tidigt skede upptäcka elever som har svårt och styra insatser. Många av dessa modeller är dock ”svarta lådor”: de kan vara träffsäkra, men varken lärare eller föräldrar kan se varför en viss förutsägelse gjordes. Denna artikel presenterar ett nytt tillvägagångssätt som strävar efter att vara både mycket noggrant och lätt att förstå, så att pedagoger kan lita på och agera utifrån resultaten.
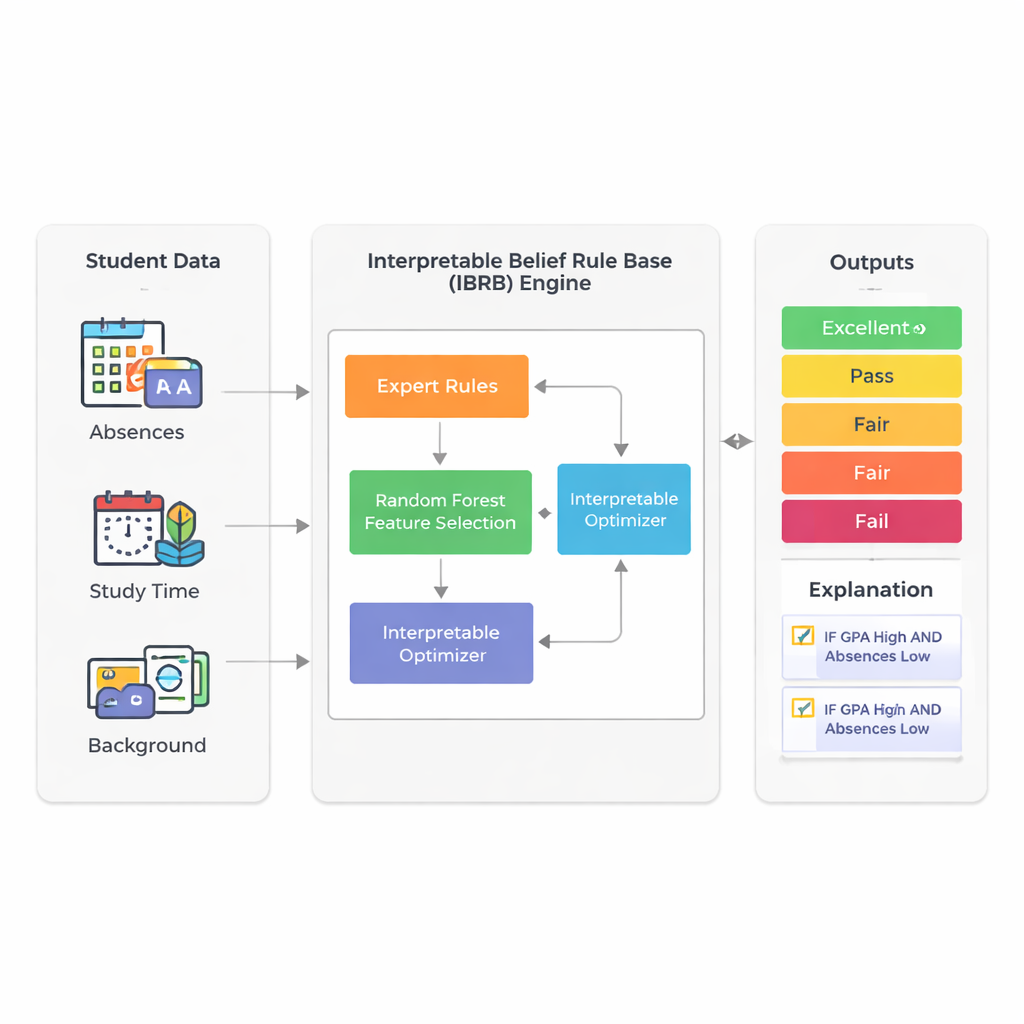
Ett smartare sätt att läsa signalerna
Studien fokuserar på att förutsäga hur väl elever i slutändan kommer att prestera genom att använda den information skolor redan samlar in: grade point average (GPA), frånvaro, studietid, bakgrund samt familje- och aktivitetsfaktorer. Istället för att förlita sig på ogenomskinliga djupinlärningssystem bygger författarna vidare på en teknik som kallas belief rule base. Inom denna ramformulerar experter regler som liknar det en lärare skulle kunna säga: ”Om GPA är hög och frånvaro är låg, då är det sannolikt att eleven kommer att klara sig väl.” Varje regel bär på en grad av tro för möjliga utfall såsom Excellent, Good, Pass, Fair eller Fail. Det gör resonemanget synligt och i princip förklarligt även för icke-experter.
Att tygla komplexitet utan att tappa betydelse
En stor utmaning med regelbaserade system är att de kan växa okontrollerat när många elevattribut inkluderas: varje extra faktor multiplicerar antalet möjliga regler. För att undvika denna ”regelexplosion” använder forskarna först en random forest—en mycket använd ensemble av beslutsträd—för att mäta vilka funktioner som är viktigast för att förutsäga prestation. I deras verkliga dataset med 2 392 elever från en offentlig källa står GPA och antal frånvarodagar för omkring 73 % av modellens prediktiva kraft. Genom att medvetet behålla endast dessa två indata förblir slutmodellen kompakt och lättare att tolka, samtidigt som den fortfarande fångar större delen av variationen i elevresultaten.
Att bygga regler som människor kan följa
Kärnan i den nya modellen, kallad IBRB-m, är ett noggrant strukturerat set med 25 regler som kombinerar nivåer av GPA och frånvaro med trograder för de fem prestationskategorierna. Författarna formaliserar vad det innebär att en sådan modell är ”tolkbar”. Bland deras krav: varje referensnivå (som ”låg GPA”) måste täcka ett tydligt och distinkt intervall; regelbasen måste omfatta alla realistiska kombinationer av indata; parametrar som regelvikter och attributvikter måste ha vardagliga betydelser; och systemets interna beräkningar måste omvandla information på ett transparent, matematiskt konsekvent sätt. Utöver dessa traditionella villkor lägger de till utbildningsspecifika riktlinjer som tvingar modellens förutsägelser att följa sunt förnuft—till exempel genom att undvika bisarra fall där en elev samtidigt bedöms vara mycket sannolik att utmärka sig och att misslyckas.
Låta data finslipa vad experterna säger
Människliga experter är inte alltid ense, och deras initiala regler kan vara oprecisa. För att förfina dessa regler utan att förvandla modellen till en svart låda utformar författarna en förbättrad optimeringsalgoritm som söker bättre parametervärden samtidigt som strikta tolkningsbarhetsbegränsningar följs. Denna algoritm justerar inte bara regelvikter och trograder utan även de brytpunkter som definierar kategorier som Excellent eller Pass. Den håller alla ändringar inom experternas godkända gränser och säkerställer rimliga, jämna tro-mönster över betyg. I praktiken ”puttar” datorn expertssystemet mot högre noggrannhet, men får inte uppfinna regler som skulle förbrylla en kunnig lärare.
Hur bra fungerar det i praktiken?
Testad på Kaggle-datasetet för elevprestationer förutspår IBRB-m-modellen korrekt slutliga prestationsnivåer i mer än 99 % av fallen och överträffar både tidigare belief-rule-system och vanliga maskininlärningsverktyg såsom neurala nätverk, random forests och k-närmaste grannar. Lika viktigt är att de optimerade reglerna förblir nära de ursprungliga expertbedömningarna när de mäts med en enkel distansmetrik, vilket innebär att resonemanget bakom varje förutsägelse fortfarande kan spåras och motiveras. Korsvalidering över flera uppdelningar av data visar att modellens prestanda är stabil, inte en tillfällighet beroende på en lycklig partitionering.
Vad detta betyder för klassrummen
För lekmän är huvudpoängen att det är möjligt att ha verktyg för elevprognoser som både är kraftfulla och begripliga. Istället för att utfärda mystiska riskpoäng kan modellen lyfta fram konkreta mönster som ”måttlig GPA men frekvent frånvaro” och visa hur dessa leder till en prognos som Fair eller Fail. Lärare och studiehandledare kan då svara med riktade åtgärder—såsom stöd för närvaro eller träning i studieteknik—samtidigt som de tryggt förklarar för elever och föräldrar varför modellen kom fram till sin slutsats. Författarna menar att denna kombination av noggrannhet och transparens är avgörande för att datadrivna system ska kunna spela en betrodd roll i att främja rättvis och effektiv utbildning.
Citering: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Nyckelord: förutsägelse av elevers prestationer, tolkbar AI, belief rule base, datautvinning inom utbildning, förklarbar maskininlärning