Clear Sky Science · sv
HEViTPose: mot högnoggrann och effektiv 2D-människoposestimatering med kaskadiserad grupp-spatial reduceringsuppmärksamhet
Lära datorer att läsa kroppsspråk
Från träningsappar till förarassistanssystem förlitar sig många teknologier idag på en dators förmåga att förstå hur människor rör sig. Denna förmåga, kallad estimering av mänsklig hållning, innebär att hitta positionerna för kroppens leder—som axlar, knän och vrister—i en bild eller video. Utmaningen är att göra detta både noggrant och tillräckligt snabbt för realtidsbruk på vanlig hårdvara. Denna artikel introducerar HEViTPose, en ny metod som syftar till att behålla hög noggrannhet samtidigt som den använder mindre beräkningskraft än många nuvarande system.
Varför det är så svårt att hitta leder i bilder
Vid första anblick kan det verka enkelt att lokalisera kroppens leder: leta efter armar och ben. I praktiken förekommer människor i olika storlekar, i ovanliga poser, i trånga scener och ofta delvis skymda av föremål som möbler eller bilar. Moderna system för posestimatering hanterar detta genom att skapa en detaljerad ”värmekarta” för varje led, där ljusa områden markerar sannolika positioner. Värmekartor är mycket precisa men dyra att beräkna. Traditionella system förlitar sig främst på konvolutionella neurala nätverk, som är bra på att upptäcka lokala mönster men måste bli djupare och tyngre för att fånga långdistansrelationer över hela kroppen. Nyare transformer-baserade modeller utmärker sig på att fånga sådana långdistanskopplingar, men de kräver ofta stora dataset och tung beräkning, vilket gör dem svårare att använda i realtid eller på mindre enheter.
Överlappande glimtningar för mjukare tolkning
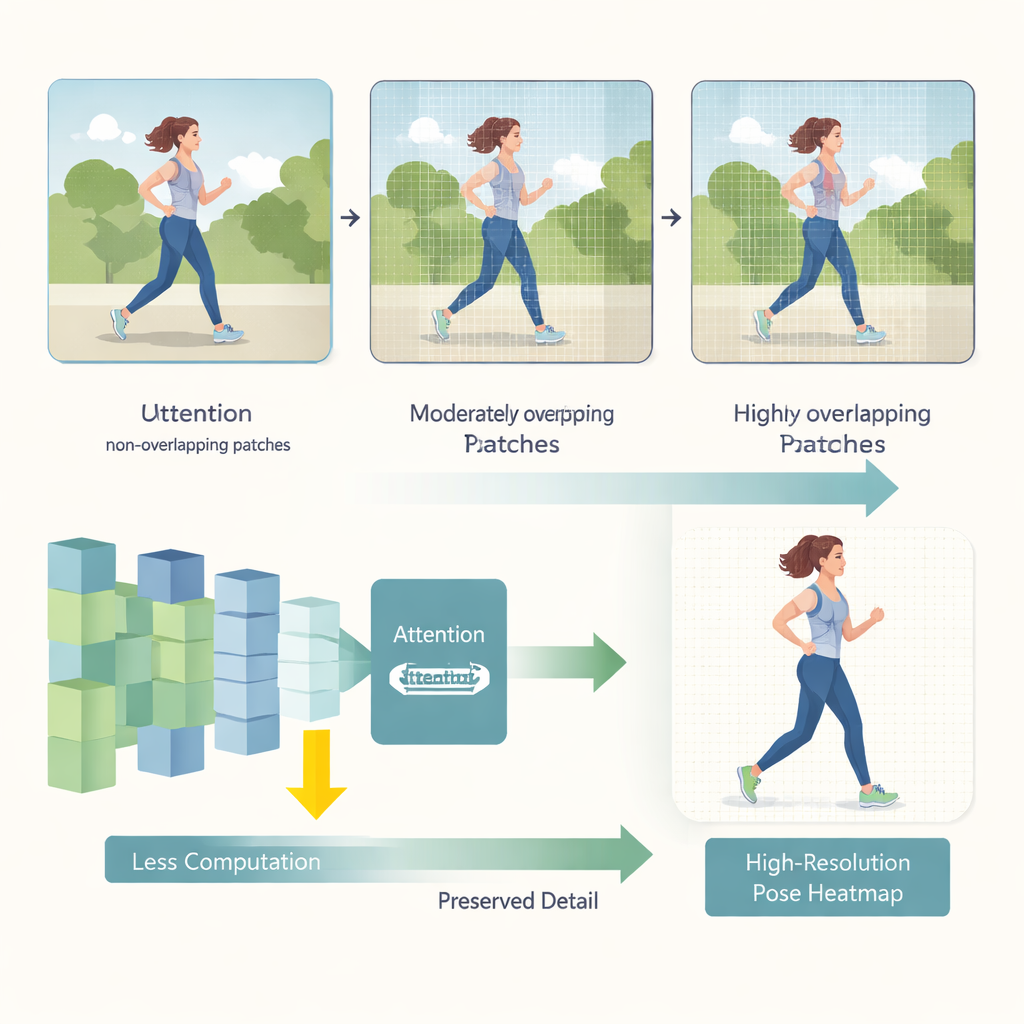
HEViTPose börjar med att ompröva hur en bild delas upp för analys. Tidigare transformer-modeller brukar ofta kapa bilder i icke-överlappande plattor, vilket kan bryta den visuella kontinuiteten mellan intilliggande regioner—som att skära av en persons arm vid kanten av en ruta. HEViTPose bygger vidare på en idé kallad överlappande patch-embedning och introducerar en tydligare, ställbar måttstock kallad Patch Embedding Overlap Width (PEOW). PEOW räknar enkelt hur många pixlar intilliggande plattor delar längs sina gränser. Genom att systematiskt variera denna överlappning visar författarna att måttlig överlappning låter nätverket bättre ”känna” den mjuka förändringen i färg och form från en platta till nästa. Denna rikare lokala kontinuitet leder till mer exakta ledpositioner, utan att modellstorleken eller beräkningen exploderar.
Smartare uppmärksamhet med mindre arbete
Den andra viktiga innovationen är en ny attention-modul kallad Cascaded Group Spatial Reduction Multi-Head Attention (CGSR-MHA). Uppmärksamhetsmekanismer talar om för nätverket vilka delar av bilden som bör påverka varje förutsägelse, men de skalar vanligtvis dåligt när bilder blir större. CGSR-MHA tar itu med detta på tre sätt. För det första delar den upp funktionerna i grupper, så varje grupp hanterar bara en del av informationen istället för allt på en gång. För det andra krymper den den spatiala upplösningen inom varje grupp innan uppmärksamheten beräknas, vilket kraftigt minskar antalet operationer. För det tredje använder den flera små attention-heads i stället för några få stora, vilket bevarar mångfald i vad modellen kan ”uppmärksamma” samtidigt som kostnaden hålls låg. Noggrant valda inställningar för hur många grupper som ska användas, hur mycket som ska krympas och hur många heads som ingår hittar en balans mellan hastighet och noggrannhet.
Lättviktiga modeller som ändå konkurrerar i toppklassen
För att testa HEViTPose utvärderar författarna den på två välanvända benchmarks: MPII-datasetet för vardagliga mänskliga aktiviteter och det större COCO-datasetet med människor i många olika scener. Över flera modellstorlekar matchar eller kommer HEViTPose nära nog den noggrannhet som ledande posestimateringssystem uppnår samtidigt som den använder långt färre parametrar och mindre beräkning. Till exempel når en version liknande noggrannhet som ett populärt högupplöst nätverk (HRNet) samtidigt som antalet lärda parametrar minskas med mer än 60 % och mängden beräkning reduceras med över 40 %. Jämfört med en annan modern hybridmodell som blandar konvolutioner och transformatorer ger HEViTPose liknande prestanda men körs ungefär 2,6 gånger snabbare på en grafikprocessor. Dessa besparingar översätts direkt till mjukare realtidsprestanda och lägre hårdvarukrav.
Vad detta betyder för vardagliga tillämpningar
Enkelt uttryckt visar HEViTPose att vi inte behöver välja mellan noggrannhet och effektivitet när vi lär datorer att läsa människors kroppsspråk. Genom att noggrant överlappa de bildstycken den undersöker och genom att omforma hur uppmärksamhet beräknas i nätverket kan systemet pricka in leder med hög precision samtidigt som det förblir kompakt och snabbt. Detta gör det attraktivt för verkliga användningsområden som sportspårning, videoövervakning, människa–robot-interaktion och övervakning i bil, där både hastighet och energiförbrukning spelar roll. Idéerna bakom HEViTPose—smartare överlappning och effektiv uppmärksamhet—kan också anpassas till besläktade uppgifter som spårning av djurs poser eller detektering av ansiktslandmärken, vilket potentiellt ger skarpare ”digitala ögon” till många enheter utan att kräva superdatornivå hårdvara.
Citering: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Nyckelord: estimering av mänsklig hållning, datorseende, vision transformer, effektiv djupinlärning, uppmärksamhetsmekanism