Clear Sky Science · sv
En hybrid ramverk med CNN och förstärkningsinlärning för talaridentifiering med Mel-spektrogram och kontinuerlig wavelet-transform
Varför din röst kan vara en digital nyckel
Tänk dig att du låser upp ditt bankkonto, din ytterdörr eller din telefon med bara din röst. För att det ska vara säkert måste datorer kunna skilja en person från en annan pålitligt, även när det finns bakgrundsljud, känslomässiga förändringar eller en dålig mikrofon. Denna artikel undersöker ett nytt sätt att lära maskiner att känna igen vem som talar, inte bara vad som sägs, genom att kombinera moderna djuplärande-metoder med en form av försöks-och-fel-inlärning hämtad från robotik.
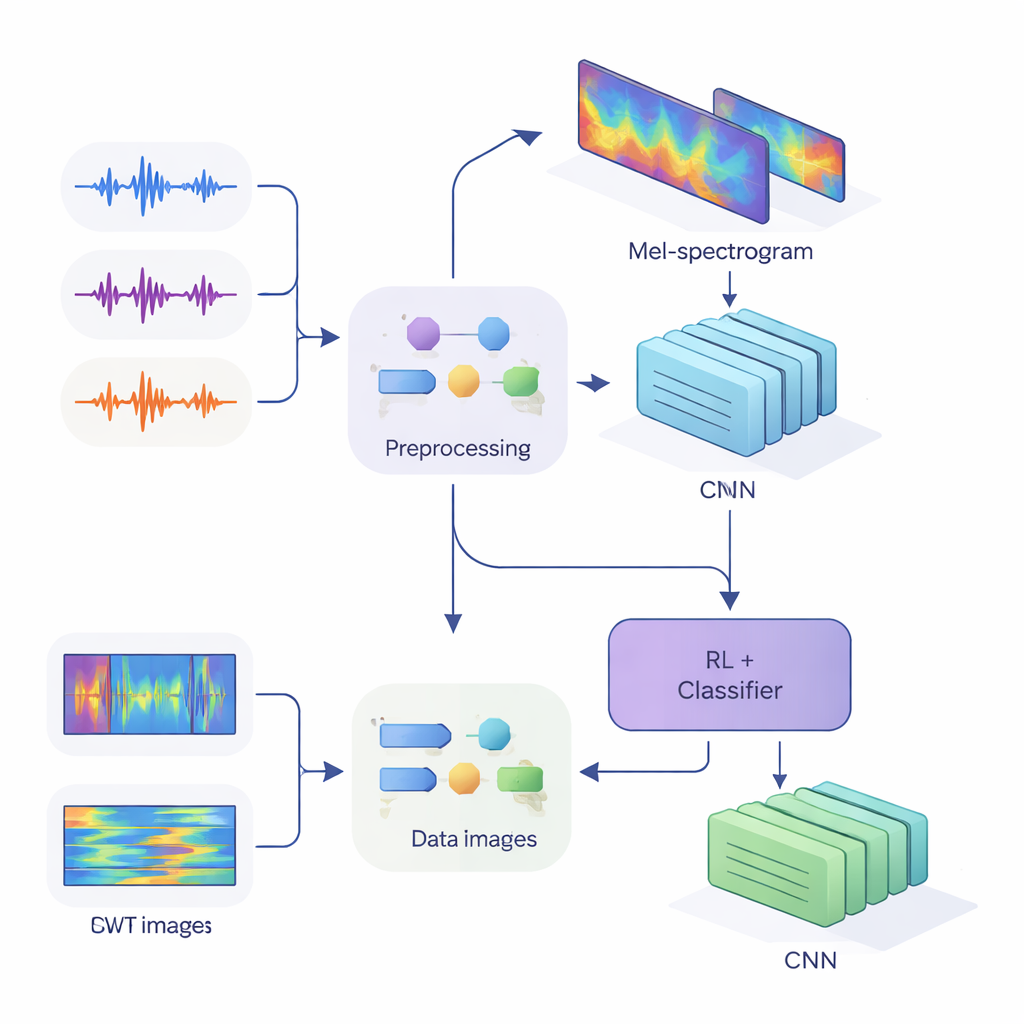
Från ljudvågor till röstfingeravtryck
Varje persons röst bär på subtila ledtrådar formade av storleken och formen på talapparaten, hur stämbanden vibrerar och deras talstil. Forskarna började med frågan: vilka mätbara egenskaper hos inspelat tal skiljer sig faktiskt mellan personer? Med 2 703 ljudklipp från 40 engelsktalande personer i LibriSpeech-databasen analyserade de 22 enkla akustiska egenskaper, såsom variationsrikedom i ljudstyrka, energi i olika frekvensband, rytm och en måttstock kallad entropi som fångar hur komplex eller oförutsägbar ljudet är. Statistiska tester visade att 21 av dessa 22 egenskaper bar stark talarspecifik information, där entropi och högfrekvensenergi stack ut som särskilt distinktiva. Med andra ord är en persons ”röstfingeravtryck” utspritt över många aspekter av ljudet, inte bara tonhöjd eller volym.
Två sätt att omvandla ljud till bilder
För att mata dessa ledtrådar till moderna neurala nätverk omvandlade teamet en-dimensionellt ljud till tvådimensionella bilder som fångar hur energin förändras över tid och frekvens. I den första metoden använde de Mel-spektrogram, som efterliknar hur det mänskliga örat grupperar frekvenser och är standard inom talteknologi. I den andra metoden använde de kontinuerliga wavelet-transformer, ett mer flexibelt sätt att zooma in på både korta, skarpa ljud och längre vokaler. Efter noggrann rengöring av ljuden—borttagning av tystnad, standardisering av volym och tillsats av små förvrängningar som brus och tonhöjdsförskjutningar för att göra systemet mer robust—producerade de Mel-”bilder” i storleken 80 × 313 och wavelet-”bilder” i storleken 128 × 128, redo att bearbetas av konvolutionella neurala nätverk (CNNs).
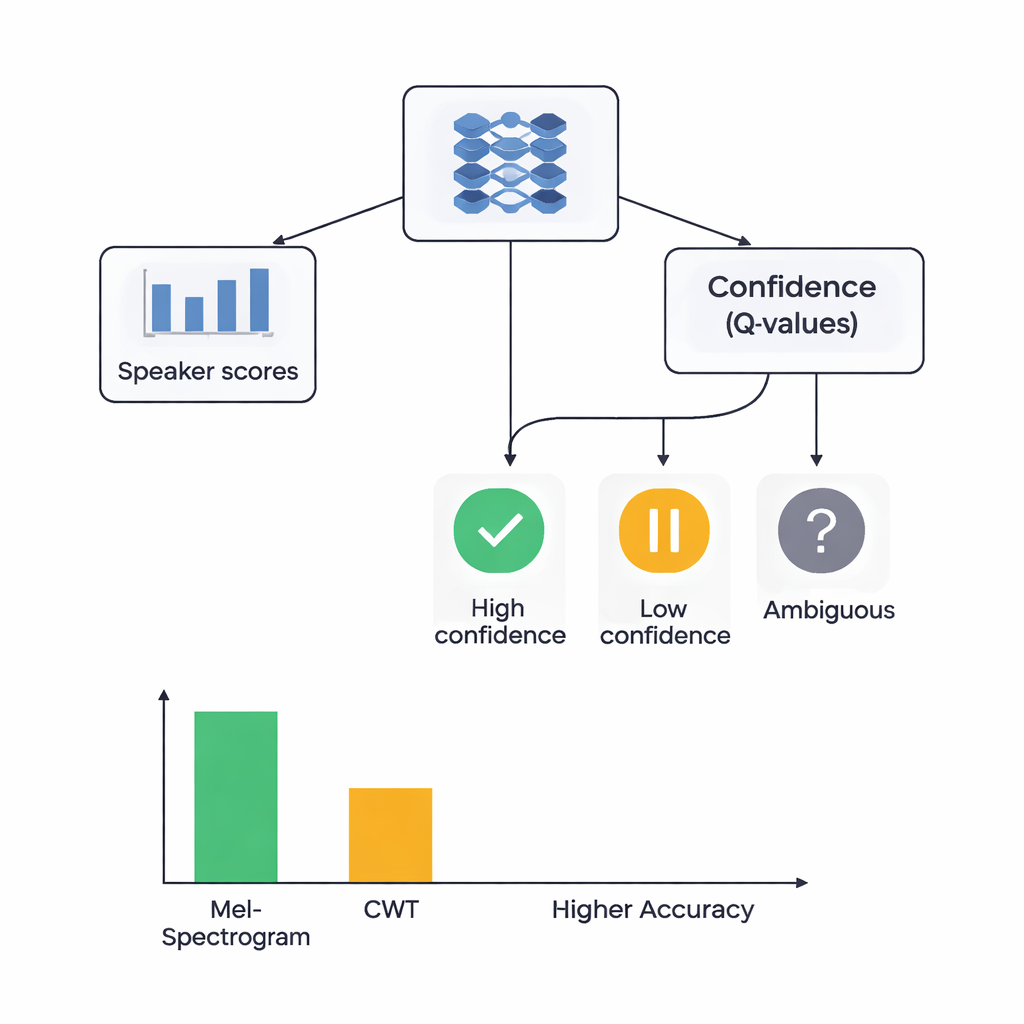
Att lära nätverk att lyssna och tvivla
I studiens kärna finns en hybridarkitektur som förenar två inlärningsstilar. Först skannar CNN:er Mel- eller wavelet-bilderna för att extrahera mönster som tenderar att tillhöra särskilda talare, på samma sätt som bildigenkänningsnätverk lär sig känna igen ögon eller kanter. För Mel-baserade system lade författarna till en självuppmärksamhetsmodul som låter nätverket fokusera på de mest informativa tidssegmenten. Ovanpå dessa funktionsextraktorer placerar de en komponent för förstärkningsinlärning (RL) som lär sig hur säker systemet bör vara i varje beslut. Istället för att alltid göra ett fast val tilldelar RL-delen värden till åtgärder som ”acceptera detta som hög-säkerhets-gissning”, ”behandla detta som låg säkerhet” eller ”markera som tvetydigt”. Över många träningsomgångar belönas den när säkra beslut är korrekta, vilket förskjuter nätverket mot bättre kalibrerade bedömningar.
Hur väl fungerar det hybrida systemet?
Forskarna jämförde fyra modeller: Mel-baserad med RL, Mel-baserad utan RL, wavelet-baserad med RL och wavelet-baserad utan RL. Alla testades med noggrann femfaldig korsvalidering, vilket innebär att varje ljudklipp tjänade både för träning och för test i olika rundor. Mel plus RL-systemet presterade bäst och identifierade talaren korrekt ungefär 88 % av gångerna och visade nästan perfekt separation mellan talare enligt ett standardmått för diskriminativ förmåga. Wavelet plus RL-systemet nådde omkring 78 % noggrannhet. Avgörande var att tillägget av RL-komponenten förbättrade prestandan för båda funktionstyperna med ungefär 3 procentenheter och gjorde resultaten mer konsekventa över olika datasplit. Fler talarklasser uppnådde högkvalitativ igenkänning när RL inkluderades, vilket tyder på att de förtroende-medvetna besluten hjälpte särskilt med svåra, lätt förväxlade röster.
Vad detta innebär för vardaglig röstsäkerhet
För icke-specialister är huvudbudskapet att pålitliga röstbaserade identitetskontroller kräver både rika representationer av ljudet och en hälsosam grad av tvivel från maskinen. Detta arbete visar att öroninspirerade Mel-spektrogram, i kombination med uppmärksamhet och en förstärkningslärande komponent som kan säga ”jag är osäker”, överträffar mer exotiska wavelet-bilder för uppgiften att skilja talare åt. Även om studien använder ett relativt litet, rent dataset och ännu inte är inställd för bullriga, verkliga förhållanden, visar den att det att addera ett förtroende-medvetet lager ovanpå djupa neurala nätverk kan göra röstautentisering både mer exakt och mer trovärdig—ett viktigt steg om våra röster ska bli säkra digitala nycklar.
Citering: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Nyckelord: talaridentifiering, röstbiometri, djuplärande, förstärkningsinlärning, Mel-spektrogram