Clear Sky Science · sv
En allmän ram för adaptiv icke‑parametrisk dimensionsreduktion
Varför det spelar roll att krympa stor data
Det moderna livet bygger på data: medicinska skanningar, köphistorik online, fotografier, nyhetsflöden och mer. Varje post kan ha hundratals eller tusentals mätvärden, vilket gör det svårt att lagra, analysera eller ens visualisera. Forskare använder "dimensionsreduktion" för att komprimera denna komplexitet till enklare bilder och modeller samtidigt som viktiga mönster bevaras. Men dagens populära verktyg kräver ofta många manuella val och försök‑och‑fel‑justeringar. Denna artikel presenterar ett sätt att låta datan själv avgöra hur den bäst ska krympas, med målet att ge klarare bilder, mer exakt inlärning och mindre gissande från användaren.
Från enkla linjer till böjda realiteter
Ett klassiskt verktyg för att förenkla data, Principal Component Analysis, fungerar ungefär som att lysa på ett föremål och betrakta dess skugga: det hittar de bästa plana riktningarna som förklarar mesta delen av variationen. Detta är kraftfullt när datastrukturen är ungefär rak eller plan. Men verkliga data — såsom bilder, texter eller sensormätningar — ligger ofta på böjda ytor dolda i högdimensionella rum. Under de senaste två decennierna har nya "icke‑linjära" metoder, som Isomap, Locally Linear Embedding (LLE), spektral inbäddning och UMAP, utformats för att avslöja dessa slingrande former. De förlitar sig på lokala närområden: för varje punkt ser man på dess närmaste grannar och försöker bevara de småskalig relationerna när man ritar en lågdimensionell bild. Dessa metoder tvingar dock användaren att välja två viktiga reglage: hur många grannar som ska användas och till hur många dimensioner man ska projicera. Väljer man fel kan resultatet bli missvisande eller beräkningsmässigt kostsamt.
Låta datan välja sitt eget närområde
Författarna bygger vidare på ett nyligen utvecklat statistiskt verktyg kallat en estimator för intrinsisk dimension, som försöker besvara en enkel fråga: i hur många oberoende riktningar varierar datan egentligen, när man rensat bort brus? Deras estimator, kallad ABIDE, går längre. Runt varje punkt söker den automatiskt efter ett närområde som ser rimligt enhetligt ut — varken för litet och brusigt eller för stort och förvrängt. Genom detta returnerar den två informationsbitar: en global uppskattning av datans sanna dimension och en skräddarsydd närområdesstorlek för varje punkt. Detta förvandlar det vanliga fasta "antalet grannar" till en lokalt adaptiv kvantitet som kan växa i glesa regioner och krympa i täta, i takt med datans verkliga täthet.
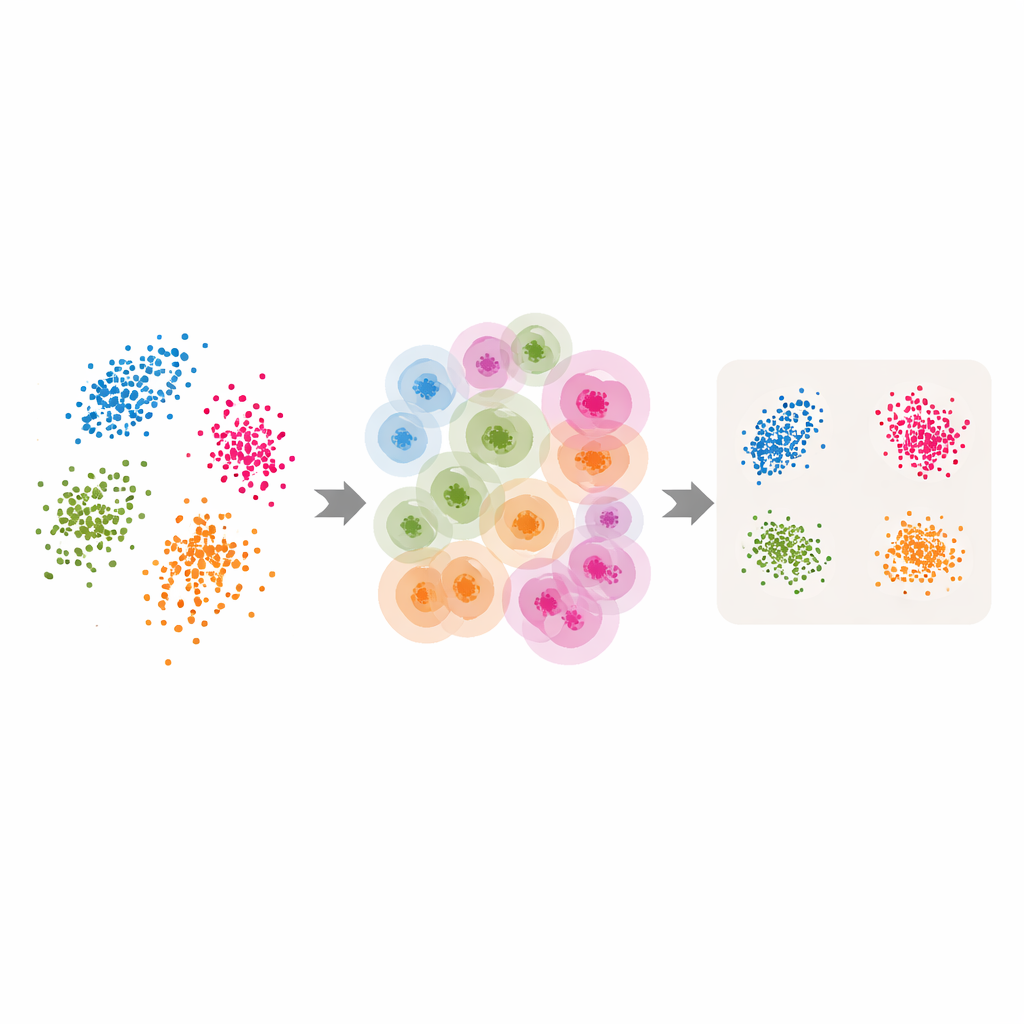
Göra klassiska verktyg adaptiva
Beväpnade med dessa adaptiva närområden och den uppskattade intrinsiska dimensionen gör författarna om flera populära metoder för dimensionsreduktion och klustring. För LLE byter de ut det enda, användarvalda antalet grannar mot de per‑punktvärden som ABIDE returnerar, och de sätter måldimensionen lika med den uppskattade intrinsiska dimensionen. Algoritmen lär sig sedan hur varje punkt kan rekonstrueras från en noggrant vald lokal grupp innan den hittar en global lågdimensionell ordning som bäst bevarar dessa lokala rekonstruktioner. Liknande idéer appliceras på spektral klustring — där en likhetsgraf mellan punkter används för gruppering — och på UMAP, som bygger en fuzzy karta över hur punkter förbinder sig. I varje fall byts den stela närområdesstorleken ut mot en flexibel, datadriven struktur som följer datans naturliga geometri.
Testning på blommor, siffror, text och syntetiska former
För att se om detta adaptiva angreppssätt ger utdelning kör författarna experiment på flera benchmark‑uppsättningar: de klassiska Iris‑blommornas mätningar, handskrivna siffror (MNIST), nyhetsartiklar representerade av språkmodellsinbäddningar och syntetiska tredimensionella former med tillagt brus. De jämför de adaptiva versionerna mot standardprogramvaruinställningar och mot noggrant finjusterade rutor av hyperparametrar. I osupervisade uppgifter såsom klustring och visualisering ger de adaptiva metoderna typiskt klarare kluster, tätare grupperingar och bättre poäng på vanliga kvalitetsmått. Till exempel återfår de adaptiva metoderna den sanna strukturen mycket bättre än fasta‑grannar‑versioner på komplexa manifolder med ojämn punkttäthet. I superviserade tester, där de reducerade data matas in i en klassificerare, matchar eller överträffar den adaptiva metoden återigen de bästa fasta‑inställningarna utan omfattande finjustering.
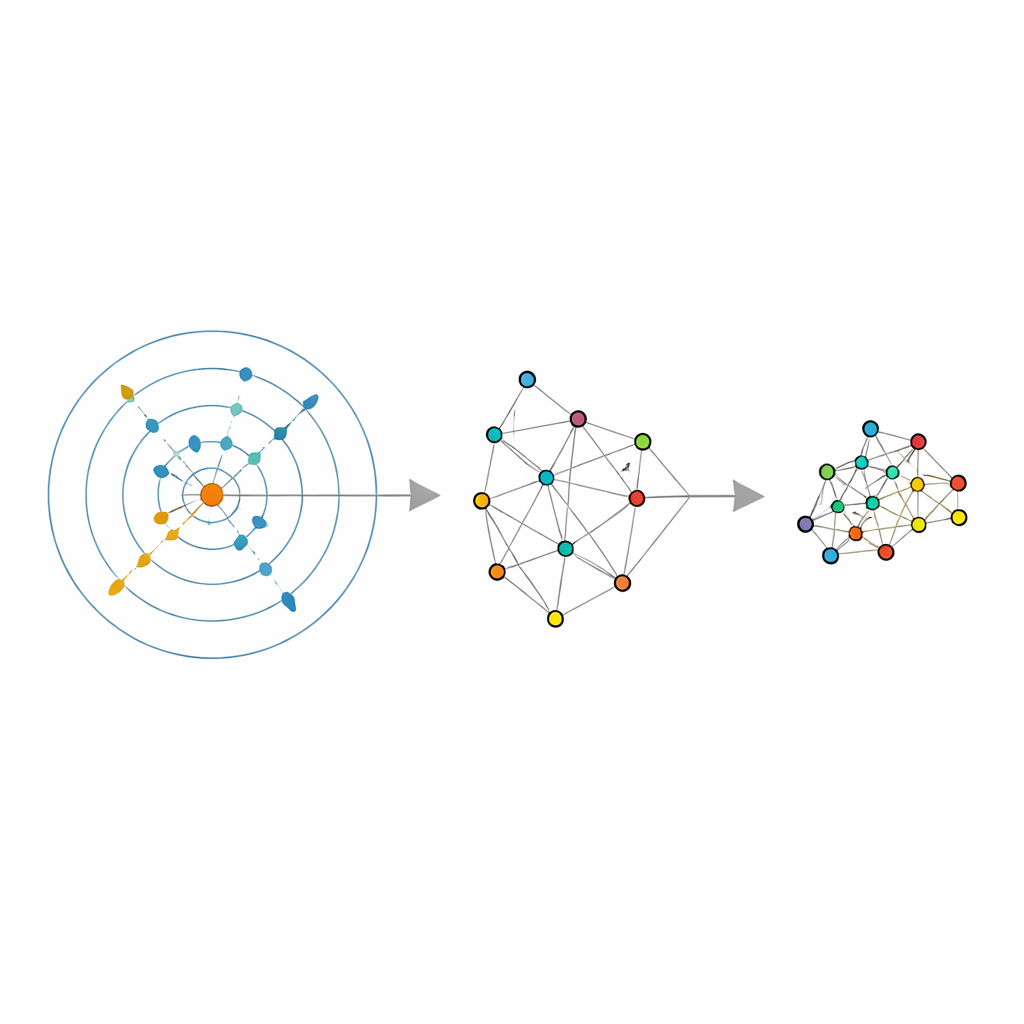
Vad detta betyder för vardaglig dataanalys
För icke‑experter och praktiker är huvudbudskapet att krympning av data inte behöver förlita sig på gissningar. Genom att använda datans egen geometri för att avgöra "hur många grannar" och "hur många dimensioner" omvandlar denna ram välanvända verktyg som LLE, spektral klustring och UMAP till smartare, mer robusta versioner av sig själva. Resultatet blir mer pålitliga lågdimensionella vyer — plottar och funktioner som bättre speglar datans verkliga form — samtidigt som tiden som läggs på manuella hyperparameter‑sökningar ofta minskar. I praktiska termer innebär detta att uppgifter som att visualisera stora bildsamlingar, gruppera dokument eller förbereda insatser för prediktiva modeller kan bli både enklare och mer tillförlitliga genom att låta datan adaptivt styra hur den komprimeras.
Citering: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Nyckelord: dimensionsreduktion, mångfaldslärande, närmsta grannar, intrinsisk dimension, datavisualisering