Clear Sky Science · sv
Kvantkernmetoder för marknadsföringsanalys med konvergensteori och separationsgränser
Varför smartare kundprognoser spelar roll
Företag förlitar sig i allt högre grad på data för att bestämma vilka kunder som ska riktas med erbjudanden, support eller behållningskampanjer. Men när datan blir mer komplex kan traditionella verktyg ha svårt att upptäcka subtila mönster, särskilt när varje förlorad högvärd kund är kostsam. Denna artikel undersöker om framväxande kvantdatorer — maskiner som använder kvantfysikens lagar — skulle kunna skärpa dessa prognoser för marknadsföringsliknande problem, och gör det med ett tydligt fokus på dagens ofullkomliga, ”brusiga” hårdvara.

Från kundregister till kvantkretsar
Författarna fokuserar på en praktisk uppgift de kallar konsumentklassificering: att förutsäga vilka användare som kommer att engagera sig i eller anta en digital tjänst. Varje användare beskrivs av en liten uppsättning numeriska egenskaper, såsom demografi och beteende på en plattform. Istället för att mata in dessa data direkt i en standardalgoritm kodar de först in dem i tillstånden hos några få kvantbitar (qubits) med en kompakt kvantkrets. Denna krets fungerar som en funktionstransformation och omformar datan till en form som kan vara lättare att separera i två grupper — ”sannolikt att engagera sig” och ”osannolikt att engagera sig.” Ovanpå denna kvantiska transformation använder de en välkänd klassificeringsmetod, supportvektormaskinen, i en kvantinspirerad version kallad en kvantkern-SVM (Q-SVM).
Testa kvantidéer under realistiska förhållanden
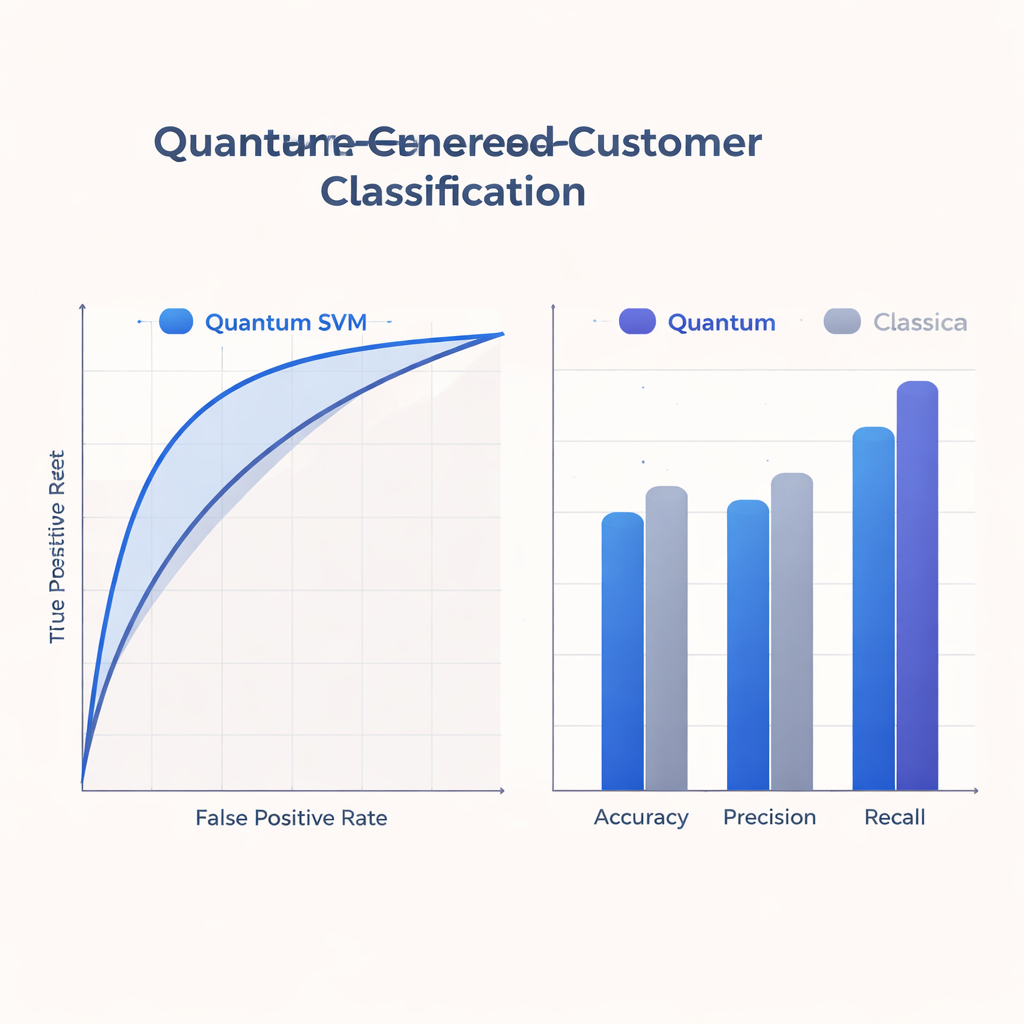
Eftersom dagens kvantenheter är små och felbenägna håller studien sig till grunda kretsar som matchar vad närliggande hårdvara klarar av. Teamet tränar och utvärderar sin Q-SVM på en verklig, anonymiserad datamängd med omkring 500 träningsfall och 125 testfall med åtta egenskaper per användare, och simulerar både ideellt och brusigt kvantbeteende. De jämför det kvantiska tillvägagångssättet med starka klassiska referensmetoder som använder populära kerneltrick på vanliga datorer. Sett över noggrannhet, precision, återkallelse och arean under ROC-kurvan (en sammanfattning av avvägningar mellan att fånga positiva fall och undvika falska larm) levererar Q-SVM konkurrenskraftig eller bättre prestanda, med särskilt stark återkallelse: den identifierar korrekt en högre andel verkligt intresserade användare än de klassiska modellerna.
Teoretiska garantier bakom kulisserna
Utöver rå prestanda ställer artikeln en djupare fråga: när bör kvantmetoder förväntas hjälpa alls? Författarna utvecklar tre huvudresultat inom teori. För det första visar de att om inlärningsproblemet uppfyller vissa glidbarhetsvillkor och kvantkretsarna förblir grunda, bör träningsprocessen för kvantkernlar konvergera pålitligt inom ett rimligt antal steg. För det andra ger de separationsgränser som antyder att deras kvantiska funktionsutvinning, under specifika antaganden, kan förstora klyftan mellan de två kundklasserna jämfört med klassiska transformationer — i praktiken gör det problemet lättare att lösa. För det tredje analyserar de hur approximativa metoder drastiskt kan minska kostnaden för att arbeta med stora kvantderiverade funktionsrum, så att tillvägagångssättet förblir beräkningsmässigt genomförbart.
Vad detta kan innebära för marknadsförare
För marknads- och kundanalysteam ligger den mest konkreta vinsten i hur den kvantiska modellen balanserar missade möjligheter mot bortkastad kontakt. Q-SVM:ens högre återkallelse innebär att den är mindre benägen att förbise användare som skulle svara positivt på ett erbjudande — en nyckelfördel i behållnings- eller proaktiva servicekampanjer. Samtidigt håller dess precision och totala noggrannhet sig inom ett intervall jämförbart med starka klassiska referenser, understött av en robust ROC-kurva. Eftersom metoden fungerar väl över ett spann av beslutströsklar kan team justera hur aggressiva eller försiktiga de vill vara — med fokus antingen på återkallelse eller precision — utan att behöva träna om modellen varje gång.
En lovande början, inte en kvantrevolution (än)
Författarna betonar att deras fynd är tidiga steg, inte bevis för en genomgripande kvantsuveränitet. Resultaten kommer från simuleringar på en dataset, inte från storskaliga körningar på hårdvara eller många olika marknader. Deras matematiska garantier bygger också på idealiserade antaganden som kanske inte fullt ut gäller på brusiga enheter. Fortfarande visar arbetet att noggrant utformade kvantkernlar redan kan matcha eller något överträffa goda klassiska metoder i en realistisk konsumentuppgift, samtidigt som det erbjuder en tydlig väg mot större fördelar i takt med att kvantplattformar skalar upp. Slutsatsen för läsaren är att kvantmaskininlärning rör sig från abstrakta löften mot verktyg som en dag kan göra kundprognoser mer precisa och flexibla i verkliga affärssammanhang.
Citering: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Nyckelord: kvantmaskininlärning, marknadsföringsanalys, kundklassificering, supportvektormaskiner, kvantkernlar