Clear Sky Science · sv
Fusion av infraröda och synliga bilder via visuell förbättring och semantisk koppling
Skarpare syn från dag- och nattkameror
Moderna bilar, drönare och säkerhetssystem bär ofta två slags ögon: en vanlig kamera som ser färg och textur, och en infraröd kamera som ser värme. Var och en har sina styrkor och svagheter, och att kombinera dem till en enda klar bild är förvånansvärt svårt. Denna artikel presenterar ett nytt sätt att föra samman dessa två vyer till en bild som inte bara är lättare att se på, utan också lättare för datorprogram att tolka.
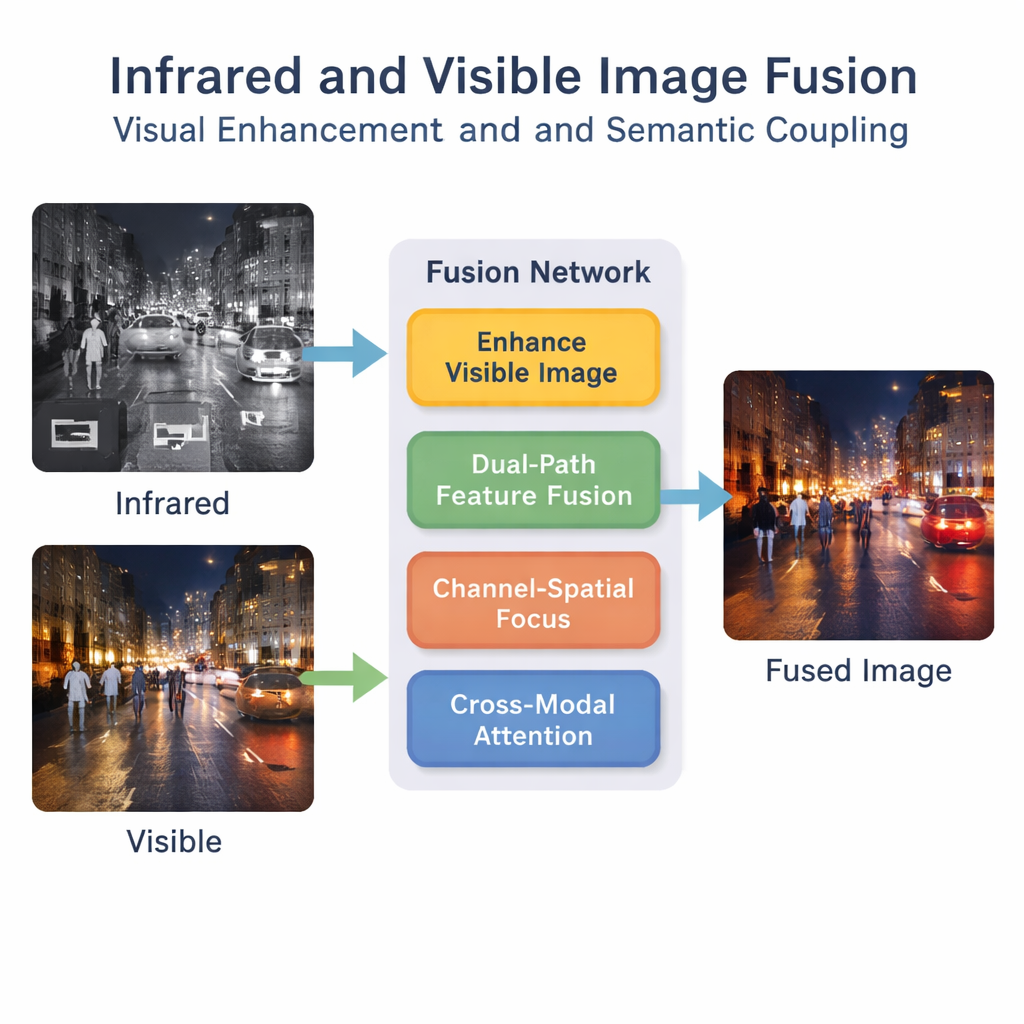
Varför två ögon är bättre än ett
Synliga ljuskameror fångar skarpa detaljer som vägmarkeringar, byggnadskanter och kläders ytor, men de har svårt i mörker, dimma eller när objekt smälter in i bakgrunden. Infraröda kameror gör tvärtom: de framhäver varma objekt som människor och fordon även i mörker, men deras bilder ser suddiga ut och saknar fina detaljer. Att slå samman dessa två vyer till en "det bästa av två världar"-bild kan hjälpa i uppgifter från fotgängardetektering i förarassistanssystem till övervakning och räddningsinsatser. Många befintliga fusionsmetoder fokuserar dock bara på ytliga egenskaper — ljusa fläckar från infrarött och texturer från synliga bilder — samtidigt som de försummar den djupare, scen-nivåbetydelsen som är viktig för smarta maskiner.
En smartare metod för att blanda bilder
Författarna föreslår ett djuplärande-ramverk som ser fusion som mer än en enkel överläggning. Först ljusar och balanserar ett särskilt förbättringssteg den synliga bilden, särskilt i scener med svagt ljus, så att värdefulla detaljer inte går förlorade innan fusionen ens börjar. Därefter bearbetar ett tvågreningat nätverk både infraröda och synliga ingångar parallellt. Den ena grenen koncentrerar sig på lokala mönster såsom kanter och texturer, medan den andra ser till den bredare kontexten i scenen. Genom att kombinera dessa grenar skapar systemet en rikare intern beskrivning av vad som händer i bilderna.
Lära nätverket vad det ska uppmärksamma
Att bara extrahera många funktioner räcker inte; nätverket måste lära sig vilka som är viktiga. En "kanal–rumslig" modul hjälper modellen att framhäva kritiska regioner och informationsslag, som fotgängare eller starka strålkastare, samtidigt som mindre användligt bakgrundsstörning tonas ner. Utöver detta uppmuntrar en bimodal interaktiv uppmärksamhetsmekanism de infraröda och synliga strömmarna att kommunicera med varandra. Den lär sig hur värmesignaturer och visuella texturer linjerar upp över scenen och fångar högre nivåers begrepp som "denna ljusa fläck i infrarött motsvarar den personen i den synliga bilden." Denna semantiska koppling hjälper den sammanfogade bilden att förbli logiskt konsekvent snarare än bara visuellt blandad.

Sätta metoden på prov
För att kontrollera att de sammanfogade bilderna inte bara är tilltalande utan också realistiska, lägger författarna till ett diskriminatornätverk liknande de som används i generativa adversariella nätverk. Detta extra nätverk lär sig att skilja verkliga synliga bilder från sammanfogade, vilket driver fusionprocessen att producera resultat som ser naturliga ut för både människor och maskiner. Metoden tränas och testas på tre utmanande samlingar av infraröda–synliga bildpar, som täcker dag- och nattvägar samt militärt inspirerade scener. Över en rad standardmått för kvalitet överträffar den nya metoden i allmänhet tio befintliga fusionsmetoder och producerar bilder med skarpare kanter, bättre kontrast och mer informativt innehåll.
Bättre bilder för säkrare maskiner
Utöver visuell kvalitet ställer författarna en praktisk fråga: hjälper dessa sammanfogade bilder datorer att fatta bättre beslut? Genom att använda ett populärt system för objektigenkänning för att hitta fotgängare visar de att deras sammanfogade bilder förbättrar detekteringsnoggrannheten jämfört med både enkel-sensorbilder och tidigare fusionsmetoder. I vardagstermer skapar tekniken bilder som är lättare för både människor och algoritmer att tolka, särskilt under svåra förhållanden som nattkörning. Även om systemet fortfarande behöver finjusteras för realtidsanvändning i resurssnåla enheter, utgör det ett lovande steg mot säkrare och mer tillförlitlig syn i självkörande fordon, övervakning och andra teknologier som måste se klart när det verkligen gäller.
Citering: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
Nyckelord: bildfusion, infraröd avbildning, svagt ljus-seende, djuplärande, objektigenkänning