Clear Sky Science · sv
Maskininlärning för snabb uppskattning av makroseismisk intensitet från seismometriska data i Italien
Varför snabba bedömningar vid jordbävningar är viktiga
När marken börjar skaka har räddningsteam bara minuter på sig att bestämma var de ska skicka räddningspersonal och resurser. Men det vanliga sättet att beskriva hur hårt en jordbävning känns vid ytan – makroseismisk intensitet, som Mercalli-skalan som används i Italien – kommer ofta timmar, dagar eller till och med månader senare, efter att människor fyllt i enkäter och experter undersökt skadorna. Den här artikeln undersöker hur modern maskininlärning kan omvandla de första seismometeravläsningarna till snabba, relativt precisa kartor över hur starkt en jordbävning upplevts, och därigenom hjälpa myndigheter att agera snabbare och mer säkert.
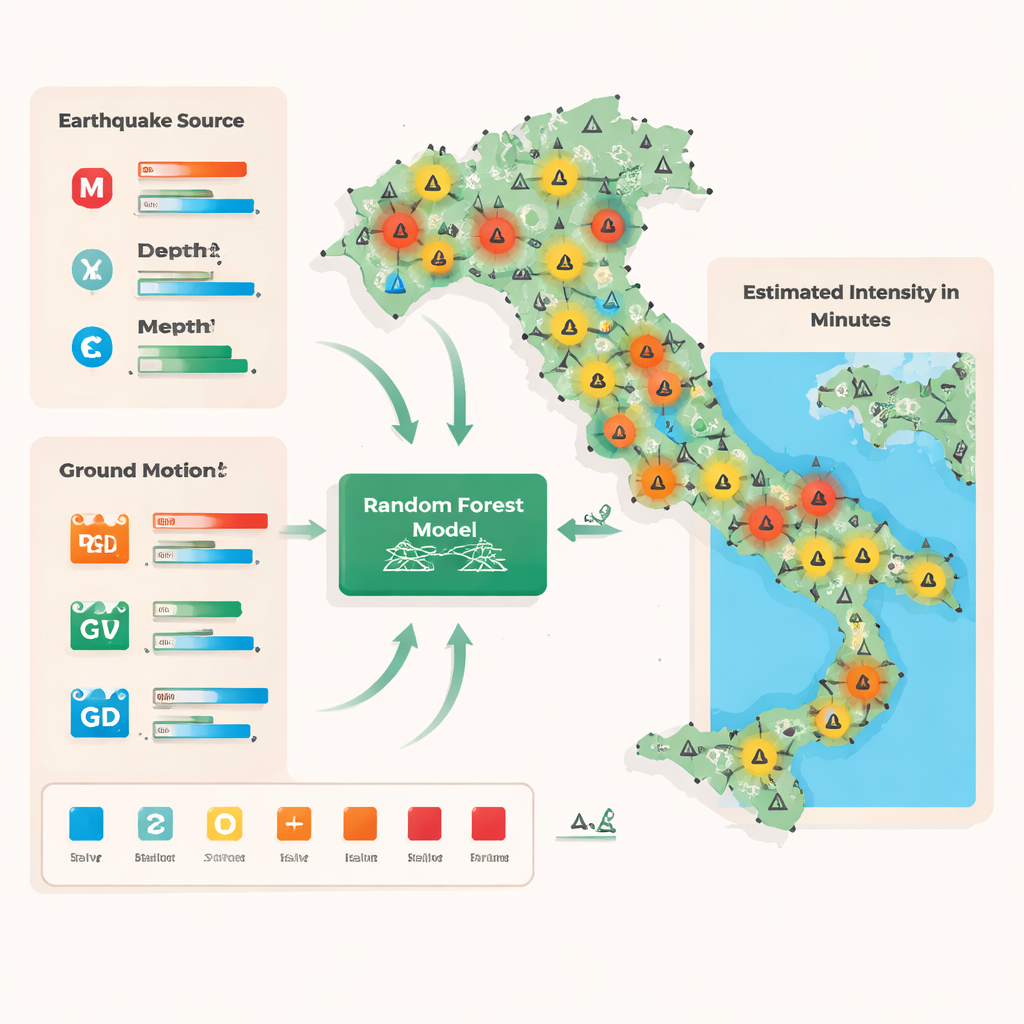
Från rapporter om känningar till snabba uppskattningar
Traditionella intensitetsuppskattningar i Italien bygger på två huvuddatakällor. Den ena består av expertfältundersökningar som loggas i en officiell databas och som fokuserar på skadade platser men som kräver tid att organisera. Den andra kommer från det webbaserade systemet “Hai Sentito Il Terremoto”, där medborgare rapporterar vad de kände och såg, vilket ger många observationer av låg och måttlig intensitet. Båda källorna mäter intensitet på Mercalli-Cancani-Sieberg-skalan, som klassar skakningar från mycket svaga till förödande baserat på mänskliga och byggnadsreaktioner. För att koppla dessa människocentrerade mått till instrumentavläsningar slog författarna samman de två datasetten kring varje seismisk station, genomsnittade alla rapporterade intensiteter inom 5 km för att få ett representativt värde för området och avrundade det till en heltalsklass från 1 till 8.
Att lära en skog av modeller att tolka skakningar
Forskarnas angreppssätt formulerade intensitetsuppskattning som ett klassificeringsproblem: givet tidiga mätningar förutsäga vilken av åtta intensitetsklasser som gäller i områdena runt varje station. De använde en Random Forest, en ensemble av många beslutsträd där varje träd gör en enkel serie “om–så”-delningar på data, som kombinationer av magnitud, djup, avstånd från källan och direkta markrörelsemått som peak ground acceleration, hastighet och förskjutning. Modellen tränades på 5 466 observationer från 523 jordbävningar i hela Italien (2008–2020) och lärde sig komplexa, icke-linjära samband mellan vad seismometrar registrerar och vad människor rapporterar. För att hantera att starka skakningar är ovanligare i datan justerade författarna träningen så att alla intensitetsnivåer räknades lika, vilket förhindrar modellen från att fokusera enbart på de vanligaste, svagare händelserna.
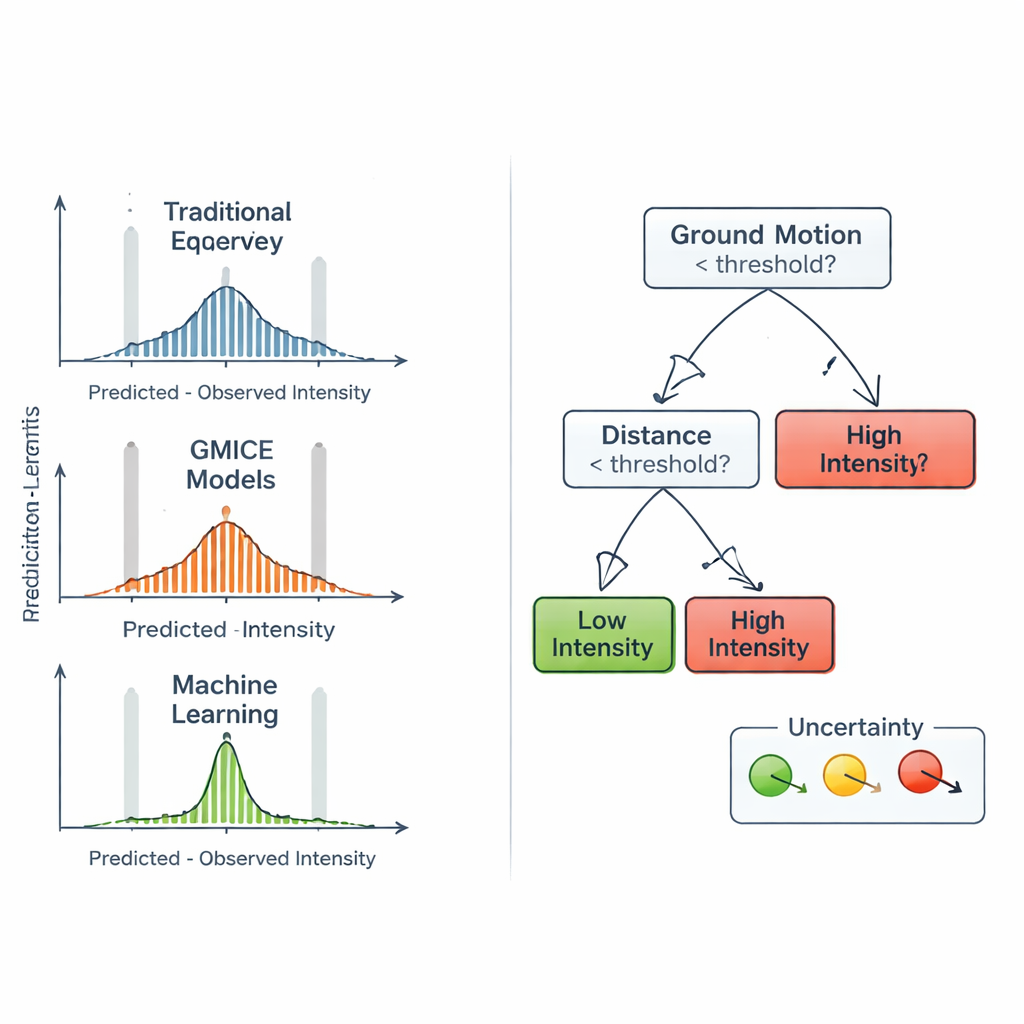
Jämförelse med etablerade samband
För att avgöra om maskininlärningsmetoden verkligen tillförde värde jämförde teamet sina prognoser med två allmänt använda familjer av empiriska samband. Den första, kallad Intensity Prediction Equations, uppskattar intensitet huvudsakligen utifrån jordbävningens magnitud, djup och avstånd, under antagandet att skakningen avtar med avstånd på ett jämnt sätt. Den andra, Ground Motion to Intensity Conversion Equations, omvandlar instrumentella mätningar av toppvärden till förväntade intensitetsklasser. Dessa formler är kompakta och lätta att tillämpa, men de kan inte fullt ut fånga hur lokal geologi, byggnadsbestånd eller vågrörelsernas riktning påverkar den skakning människor känner. I kontrast integrerar Random Forest både källparametrar och markrörelsemått naturligt, och kan anpassa sig till subtila mönster i det italienska datasetet utan att förskriva en stel matematisk form.
Insyn i "svarta lådan" och dess begränsningar
Då räddningsledare behöver förstå grunden för automatiserade beslut byggde författarna enklare ”surrogat”-beslutsträd som efterliknar Random Forests beteende. Dessa mindre träd kan ritas som diagram och visa vilka markrörelsetrösklar som skiljer låg från hög intensitet och var variabler som acceleration och hastighet dominerar. Denna analys avslöjade att direkta markrörelsemått, särskilt peak-acceleration och hastighet, väger tyngre än enbart magnitud eller djup. Författarna introducerade också ett enkelt sätt att flagga hur osäker varje surrogatträds prognos är, genom att använda mått på hur blandade träningsexemplen är inom varje slutgren. Samtidigt fann de att mycket starka intensiteter förblir svåra att förutsäga, delvis eftersom de är naturligt sällsynta i den historiska förekomsten, vilket leder till sporadiska underskattningar av de högsta skakningsnivåerna.
Verklig prövning under en nylig italiensk jordbävning
Teamet utvärderade sitt ramverk på en anmärkningsvärd verklig händelse: en magnitud 5,5-jordbävning utanför Adriatiska kusten nära Pesaro-Urbino 2022. Inom cirka 15 minuter hade seismologer nödvändig käll- och markrörelseinformation, men endast omkring 90 offentliga intensitetsrapporter hade registrerats, vilket gav en mycket fläckig bild. Genom att använda enbart instrumentdata genererade Random Forest och dess surrogatträd detaljerade intensitetsuppskattningar runt hundratals stationer på under två sekunder på en vanlig dator. När dessa senare jämfördes med den mycket tätare kartan byggd från mer än 12 000 medborgarrapporter insamlade över dagar fångade maskininlärningskartorna både det övergripande kända området och spridningen av måttliga skakningar på ett anmärkningsvärt bra sätt, och matchade eller överträffade de klassiska ekvationerna.
Vad detta betyder för människor som lever med jordbävningar
Sammanfattningsvis visar studien att ett omsorgsfullt tränat maskininlärningssystem kan ta de första minuterna av seismometerdata och producera snabba, relativt tolkbara kartor över jordbävningens påverkan. Dessa kartor ersätter inte detaljerade undersökningar eller crowd-sourcade rapporter, men de kan överbrygga den farliga tidiga luckan när myndigheter måste välja var de ska skicka ambulans, brandkår och byggnadsinspektörer med mycket begränsad information. Genom att kombinera avancerade algoritmer med tolkbara förenklade modeller och enkla osäkerhetsflaggor erbjuder ramverket ett praktiskt steg mot snabbare, mer informerade insatser vid jordbävningar i Italien och kan anpassas till andra regioner som står inför liknande seismiska risker.
Citering: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Nyckelord: jordbävningsintensitet, maskininlärning, random forest, seismisk risk, Italien