Clear Sky Science · sv
Transformer-förstärkt tvågrens Siamese-spårare med förtroende-medveten regression och adaptiv malluppdatering
Att lära datorer följa ett objekt i en trång scen
Från självkörande bilar till hemlarm och drönare behöver många moderna enheter följa ett enda rörligt objekt genom en rörig, föränderlig värld. Denna uppgift, kallad visuell objektspårning, låter enkel för människor men är förvånansvärt svår för maskiner: personer går framför kameran, ljusförhållanden ändras, objekt krymper på avstånd eller döljs kortvarigt. Denna artikel presenterar TSDTrack, ett nytt spårningssystem som använder nyare framsteg inom djupinlärning och transformers för att hålla låsningen på ett mål mer pålitligt under sådana verkliga förhållanden.
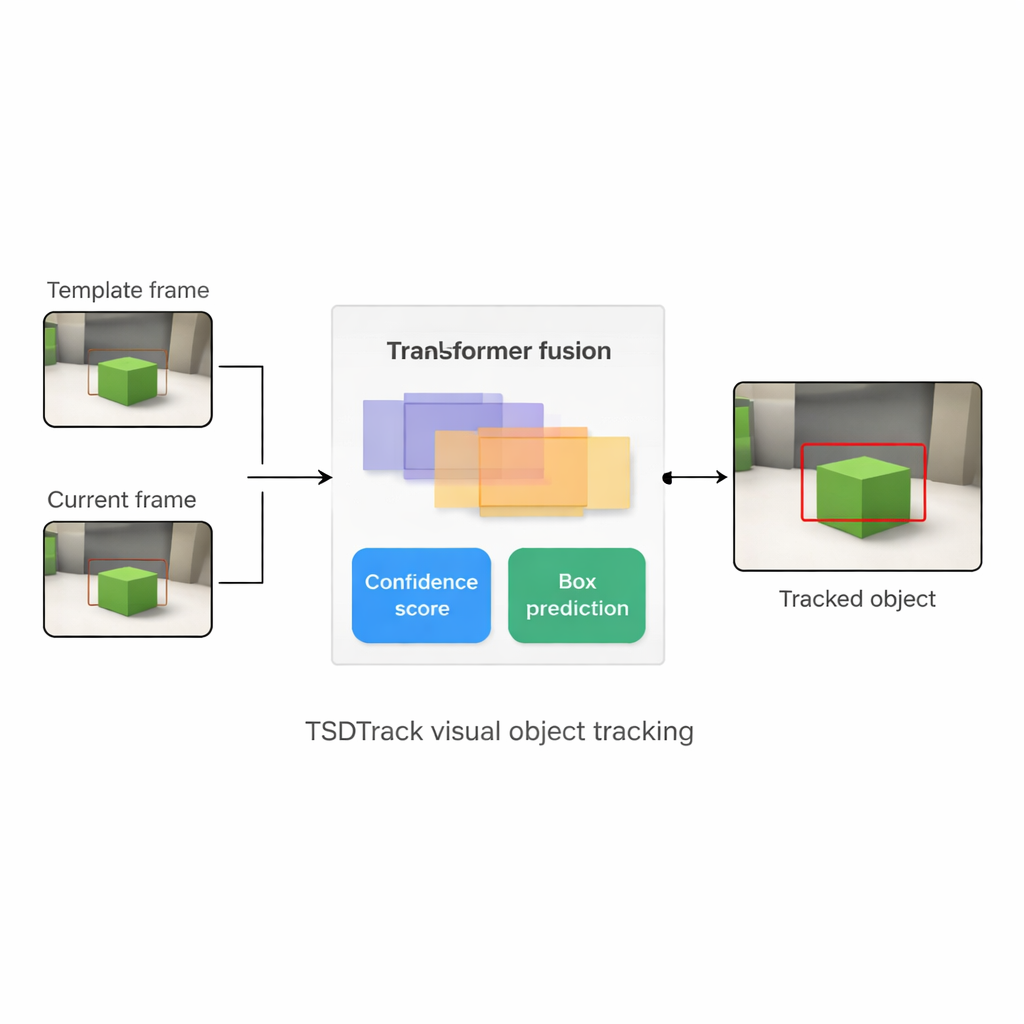
Varför det är så svårt att följa en sak
En spårare ser vanligen objektet tydligt bara i den första bildrutan i en video och måste sedan fortsätta hitta det när scenen förändras. Traditionella metoder förlitade sig antingen på handgjorda bildfunktioner eller på ett neuralt nätverk som jämförde första rutan ("mallen") med varje ny ruta. Dessa äldre system hade tre stora svagheter. För det första höll de vanligen den ursprungliga mallen fast, så om objektet vände sig, blev delvis täckt eller ändrade storlek blev spåraren svag. För det andra fokuserade de ofta på en enda detaljnivå i bilden och missade kombinationen av fina kanter och bredare kontext som hjälper människor att känna igen saker. För det tredje visste de inte när de skulle tvivla på sig själva: de producerade en ruta runt det påstådda objektet utan någon tydlig uppfattning om hur tillförlitlig gissningen var, vilket gjorde dem benägna att driva ut på bakgrunden.
Att blanda global kontext med fina detaljer
TSDTrack adresserar dessa problem genom att kombinera en klassisk "Siamese"-spårningsuppsättning med en transformer, samma typ av attention-baserad modell som förändrat språk- och bilduppgifter. Systemet använder ett djupt nätverk för att extrahera funktioner från två indata: en liten delbild som definierar målet och en större delbild som innehåller det aktuella sökområdet. Istället för att förlita sig på bara en funktionsskala hämtar det information från flera lager i nätverket, som representerar kanter, former och objekt-nivåmönster. En transformer-baserad fusionsmodul lär sig sedan hur dessa lager ska blandas så att spåraren förstår både var saker finns i bilden och hur de relaterar till den bredare scenen. Det hjälper den att skilja målet från liknande föremål och stök, även när vyn är brusig eller delvis blockerad.
Att veta hur säker spåraren faktiskt är
Hjärtat i TSDTrack är ett tvågrensat prediktionshuvud som delar upp uppgiften i två relaterade frågor: "Var är objektet?" och "Hur mycket ska vi lita på detta svar?" Den ena grenen uppskattar en förtroendepoäng som speglar inte bara hur likt målet ser ut utan också hur väl den förutsagda rutan överlappar sannolika objektregioner. Den andra grenen behandlar rutans koordinater inte som en enda gissning utan som en sannolikhetsfördelning över många möjliga positioner, vilket gör det möjligt för modellen att representera osäkerhet. När bilden är tydlig blir fördelningen spetsig och rutan exakt; när objektet är suddigt eller delvis dolt breder fördelningen ut sig. Detta probabilistiska synsätt leder till mjukare, mer stabil placering av rutor jämfört med äldre spårare som gjorde ett enda styvt predikt.
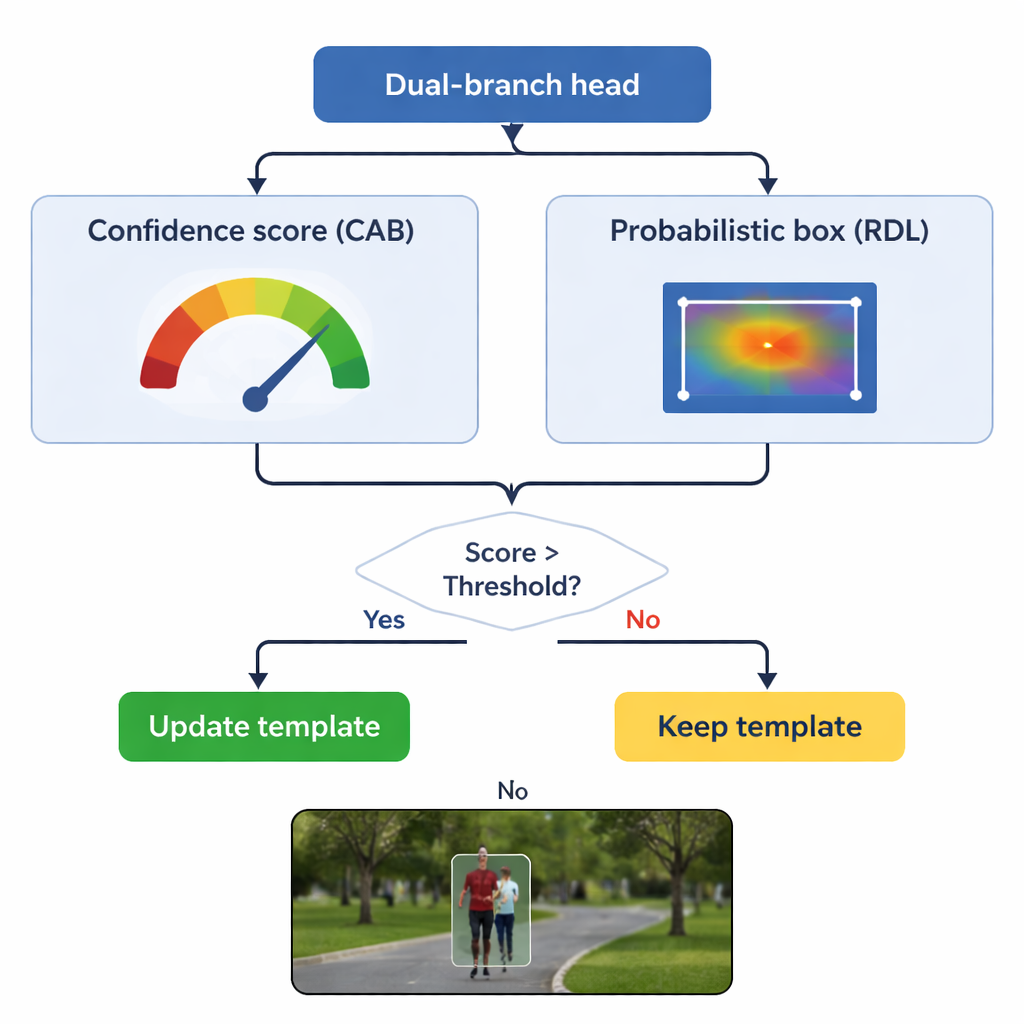
Att uppdatera minnet utan att glömma originalet
En central fara i spårning är "malldrift": om modellen fortsätter uppdatera sin bild av objektet med dåliga rutor kan den långsamt lära sig bakgrunden istället. TSDTrack tacklar detta genom att låta sin förtroendegren fungera som grindvakt. Systemet uppdaterar sin interna mall bara när förtroendepoängen är över en vald tröskel, och även då blandar det ny information försiktigt med ursprungsbilden snarare än att ersätta den helt. Denna selektiva uppdatering låter spåraren anpassa sig till verkliga förändringar, som en person som vänder sig eller en bil som roterar, utan att luras av tillfälliga ocklusioner eller distraktioner. Den ursprungliga mallen hålls också i reserv som en stabil referens om senare uppdateringar visar sig vara missvisande.
Vad resultaten betyder i praktiken
Författarna testade TSDTrack på flera välanvända spårningsbenchmarks, inklusive långa videor, snabb rörelse, flygfoton från drönare och scener med kraftig rörighet. I dessa tester slog den nya metoden konsekvent många ledande spårare både i noggrannhet (hur nära rutan är det verkliga objektet) och robusthet (hur sällan den förlorar objektet helt), samtidigt som den fortfarande kördes tillräckligt snabbt för realtidsanvändning på modern hårdvara. För en icke-specialist är slutsatsen att TSDTrack kan hålla ögonen på ett valt mål mer pålitligt i de röriga förhållanden som finns i verkliga kameror. Genom att kombinera multiskalig transformerresonemang, en känsla för sitt eget förtroende och noggrann malluppdatering erbjuder det en mer trovärdig byggsten för tillämpningar som autonoma fordon, smart övervakning och intelligenta robotar.
Citering: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Nyckelord: visuell objektspårning, transformer-baserad spårning, Siamese-nätverk, datorseende, autonoma system