Clear Sky Science · sv
En satellitbaserad maskininlärningsmetod för att uppskatta högupplöst dygnsmedeltemperatur i en megastad i Brasilien
Varför stadsvärmen inte är densamma överallt
På en het dag i en stor stad kan temperaturen du upplever på en trädklädd gata skilja sig mycket från vad någon upplever på ett betongtorg bara några kvarter bort. Ändå behandlar de flesta hälso- och klimatstudier fortfarande en hel stad som om den hade en enda temperatur. Denna artikel visar hur forskare använde satelliter, vädermodeller och maskininlärning för att kartlägga dagliga temperaturer över São Paulo, Brasilien, i fin detalj — vilket hjälper till att avslöja vem som verkligen utsätts för farlig värme och var kylande insatser behövs mest.
Att mäta stadens temperatur i hög upplösning
Traditionella temperaturregister bygger på ett begränsat antal väderstationer, ofta samlade runt flygplatser eller rikare stadsdelar. Det gör det svårt att se hur värmen fördelas över verkliga kvarter, särskilt i stora städer och i låg- och medelinkomstländer där övervakningsnät är glesa. Forskarna fokuserade på São Paulo, en vidsträckt och mycket varierad megastad med mer än 22 miljoner invånare. Målet var att uppskatta dygnsmedeltemperaturen för varje 500 gånger 500 meter stor ruta över storstadsområdet under fem år, från 2015 till 2019, och skapa en av de mest detaljerade stadsövergripande temperatursamlingarna som hittills funnits tillgängliga i Sydamerika.
Att blanda satelliter, vädermodeller och markbaserade sensorer
För att bygga denna högupplösta bild kombinerade teamet flera typer av fritt tillgängliga data. De samlade mätningar från 48 markstationer, som ger de mest direkta avläsningarna av lufttemperatur men bara på specifika punkter. De hämtade också satellitobservationer av markytans temperatur, solens vinkel och markens reflektionsegenskaper, tillsammans med information om luftfuktighet, vind och tryck från ett globalt väder"reanalys"-produkt som rekonstruerar timvis väder på ett grovt rutnät. Dessa komponenter omsamplades för att matcha 500‑metersrutnätet och rengjordes för att fylla luckor orsakade av moln eller uteblivna satellitpassager. Totalt testade de 23 möjliga prediktorvariabler som kan hjälpa förklara hur värmen varierar i tid och rum.
Att träna en lärande maskin att läsa av värmen
I stället för att använda en enkel rätlinjig (linjär) ekvation använde forskarna Random Forest, en populär maskininlärningsmetod som bygger många beslutsträd och medelvärdesbildar deras resultat. Detta tillvägagångssätt passar väl för att hitta komplexa, icke-linjära samband, såsom hur temperatur svarar olika på markvärme, luftfuktighet och vind i olika delar av staden eller vid olika årstider. För att undvika överanpassning till särdrag hos några få stationer användes en stegvis funktion/variabelselektion som behåller endast variabler som verkligen förbättrar prediktionerna, och de validerade modellen på två sätt: genom att upprepade gånger utelämna grupper av stationer under träning, och genom att hålla tillbaka fem hela stationer som ett strikt externt test av hur väl modellen presterar på nya platser.
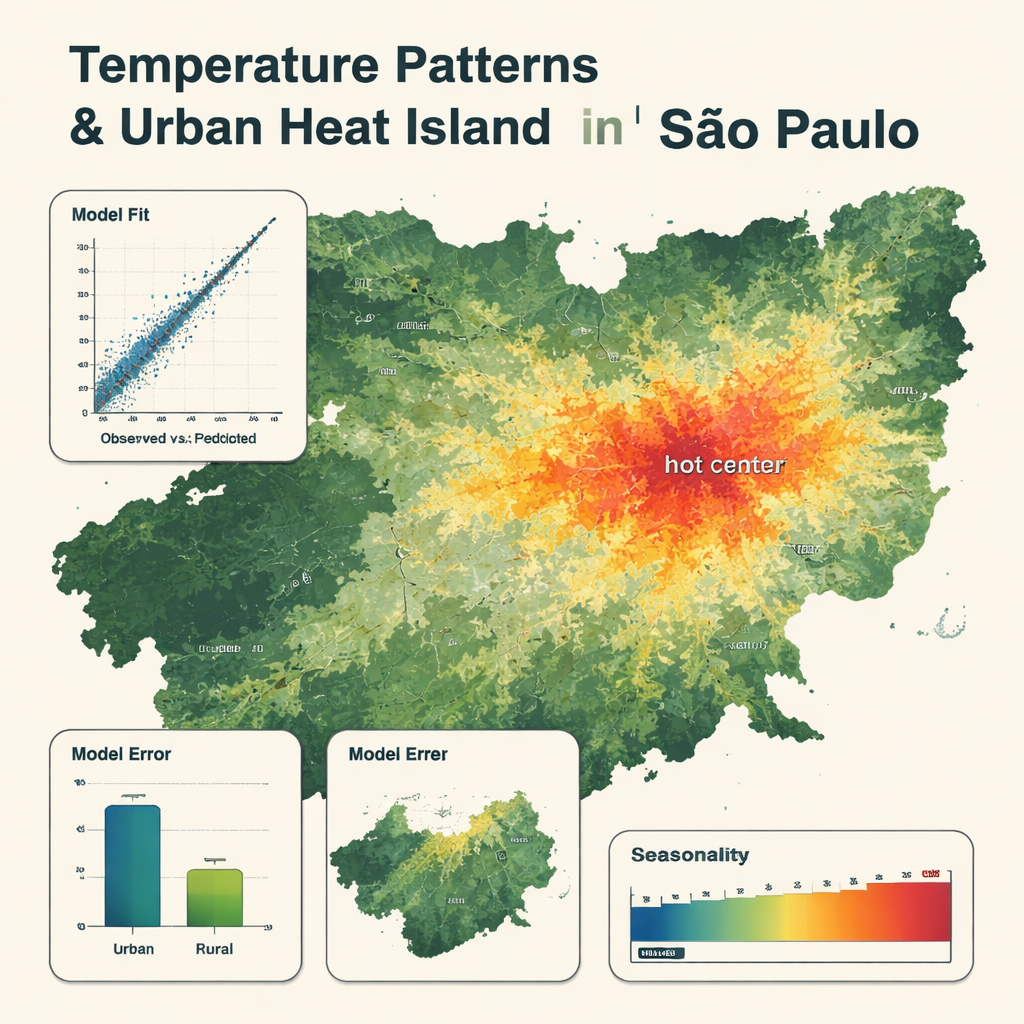
Vad de detaljerade kartorna avslöjar
Den slutliga modellen använde bara åtta nyckelvariabler, med lufttemperaturen från den globala väderprodukten i topp, och satellitens yttemperatur samt luftfuktighet som viktiga bidragande faktorer. Den återgav stationsmätningarna mycket nära, med ett genomsnittligt fel på cirka 0,8 °C och en mycket hög överensstämmelse mellan observerade och förutsagda temperaturer. Kartorna visar tydliga mönster: svalare zoner över skogar, berg och stora reservoarer, och varmare zoner i den tätt byggda stadskärnan, där temperaturerna kan vara upp till 5 °C högre än i närliggande landsbygdsområden. Modellen fångade säsongsmässiga svängningar, med varmast från december till mars och kallast från maj till augusti. Den var något mindre exakt i landsbygdsområden och tenderade att jämna ut de mest extrema varma och kalla dagarna, men den presterade ändå bättre än en mer traditionell multilinjär regressionsmodell med samma ingångar.
Varför dessa kartor betyder något för människors hälsa
Genom att omvandla spridda mätningar och satellitögonblicksbilder till dagliga temperaturuppskattningar i gatustorlek erbjuder detta arbete ett kraftfullt nytt verktyg för folkhälsa och stadsplanering i São Paulo och bortom. Forskare kan nu studera hur värme påverkar olika kvarter, inklusive informella bosättningar som ofta saknas i officiella register, och identifiera var invånare är mest utsatta under värmeböljor. Eftersom metoden bygger helt på öppna data och standardprogramvara kan den anpassas till andra städer som har några markstationer och liknande satellittäckning. Enkelt uttryckt visar studien att vi nu kan "se" stadsvärmen med mycket finare detalj, vilket ger en viktig grund för mer rättvis, riktad klimat anpassning och skydd av sårbara samhällen.
Citering: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Nyckelord: stadsvärme, maskininlärning, satellitdata, São Paulo, lufttemperatur