Clear Sky Science · sv
Identifiering av nätfiske i realtid genom maskininlärningsförstärkta webbläsartillägg
Varför falska webbplatser är allas problem
Varje dag får människor meddelanden som ser ut att komma från deras bank, ett leveransföretag eller arbetsplatsen — men vissa av dem är noggrant utformade fällor. Nätfiske använder liknande e‑postmeddelanden och webbplatser för att stjäla lösenord, kreditkortsnummer och annan personlig information. När brottslingar blir skickligare på att efterlikna riktiga sajter räcker varken enkla blockeringslistor eller magkänsla längre. Denna artikel beskriver ett nytt webbläsartillägg som tyst övervakar sidorna du besöker och använder maskininlärning för att i realtid markera farliga sajter, med målet att ge vanliga användare starkt skydd utan att de behöver bli säkerhetsexperter.
Hur moderna nätfiskeattacker lurar oss
Nätfiske har vuxit till ett av de vanligaste internetsbrotten globalt och ligger bakom en stor del av rapporterade cyberincidenter och ekonomiska förluster. Angripare skickar övertygande e‑postmeddelanden som kräver snabba åtgärder — ”verifiera ditt konto”, ”uppdatera din betalning”, ”spåra ditt paket” — och leder offren till falska webbplatser som starkt liknar riktiga bank-, handels- eller molntjänstsidor. Många av dessa sajter använder nu giltiga HTTPS‑certifikat och polerad design, så gamla varningar som ”ingen hänglåsikon” eller ”ful sida” fungerar inte längre. Enkäter och brottsrapporter visar att vuxna i 20–40‑årsåldern är hårt utsatta, och säkerhetsteam oroar sig fortfarande för e‑postbaserade bedrägerier som smyger förbi filter.
En smartare blick på webbadresser och sidans utseende
Forskarna menar att den säkraste platsen att stoppa nätfiske är inne i webbläsaren, i det ögonblick en sida laddas. Deras tillägg för Google Chrome (och kompatibla webbläsare) undersöker två huvudspår: själva webbadressen och hur sidan ser ut. Från varje sajt samlar det in ”lexikala” detaljer från URL:en, såsom längd, ovanliga symboler eller misstänkta underdomäner; ”strukturella” och domänrelaterade uppgifter, som trafik- och registreringsdata; samt ”visuella” ledtrådar som layoutblock, färger och logotyper. En headless‑webbläsare renderar varje sida i ett kontrollerat läge, delar upp den i rektangulära regioner och registrerar var formulär, logotyper och navigeringsfält finns. Den jämför sedan detta visuella fingeravtryck med betrodda sidor och letar efter nära kopior som kan vara bedrägerier.
Att använda digitala ’vargar’ för att välja de mest talande ledtrådarna
Eftersom systemet samlar dussintals mätvärden från varje sajt måste det avgöra vilka som verkligen hjälper till att skilja bedrägerier från säkra sidor. För detta lånar författarna en algoritm inspirerad av hur gråa vargar jagar. I denna ”Grey Wolf Optimizer” tävlar många kandidatuppsättningar av funktioner, och algoritmen konvergerar gradvis mot en kompakt delmängd som ger den bästa balansen mellan att fånga nätfiskesajter och undvika falska larm. Dessa utvalda funktioner matas sedan in i tre maskininlärningsmodeller — Support Vector Machine, Decision Tree och särskilt Random Forest, som kombinerar många beslutsstammar till ett kraftfullt ensemble. Träningen använder 80 000 webbplatser hämtade från publika samlingar som PhishTank och akademiska arkiv, med extra tekniker för att hantera obalansen mellan legitima och skadliga sajter.
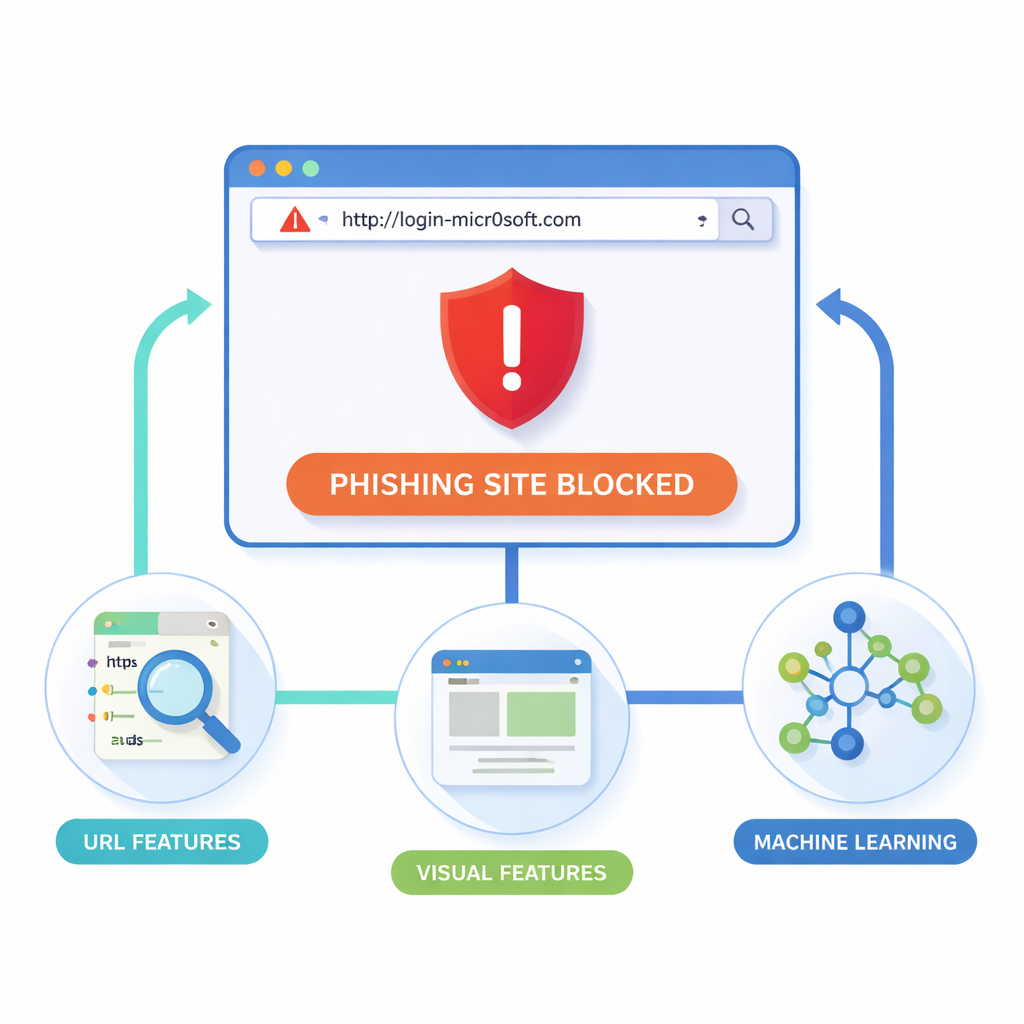
Att omvandla laboratoriemodeller till ett användbart webbläsarverktyg
Den optimerade Random Forest‑modellen nådde ungefär 98–99 % noggrannhet och en Matthews Correlation Coefficient nära 0,96, ett strängt mått som tar hänsyn till både missade attacker och falska larm. I live‑tester med ett Chrome‑tillägg skannade systemet varje URL på cirka 200 millisekunder, tillräckligt snabbt för att användarna inte skulle märka någon fördröjning. När en riskfylld sida upptäcktes visade tillägget en tydlig varning och gav användarna möjlighet att gå tillbaka eller fortsätta på egen risk. Jämfört med populära verktyg som Google Safe Browsing och befintliga anti‑phishing‑tillägg visade det nya systemet högre detektionsnivåer, färre felaktiga varningar och förmågan att upptäcka vilseledande adresser — även när de var förkortade, lätt förvanskade eller nyskapade.
Vad detta betyder för vardagligt surfande
För icke‑specialister är huvudpoängen att nätfiskeskydd inte längre måste förlita sig enbart på gissningar eller manuella svartlistor. Genom att kombinera hur en länk är skriven med hur en sida ser ut, och genom att automatiskt välja de mest informativa signalerna, kan det föreslagna tillägget känna igen många bedrägerier första gången de dyker upp, inte bara efter att någon rapporterat dem. Författarna medger att angripare kommer att fortsätta utvecklas och att modeller måste tränas om och utökas till telefoner och andra webbläsare. Ändå visar deras arbete att ett intelligent, integritetsbevarande tillägg som körs på din egen enhet kan fungera som ett outtröttligt andra par ögon — tyst kontrollerande varje sida du besöker och ingripande när något känns fel, långt innan ett förhastat klick blir ett kostsamt misstag.
Citering: Dandotiya, M., Goyal, N., Khunteta, A. et al. Real time identification of phishing attacks through machine learning enhanced browser extensions. Sci Rep 16, 6612 (2026). https://doi.org/10.1038/s41598-026-35655-7
Nyckelord: detektion av nätfiske, webbläsartillägg, maskininlärning, cybersäkerhet, falska webbplatser