Clear Sky Science · sv
Visuell vägledd AI-färgbildsgenerering med förbättrad GAN
Varför smartare konstmaskiner spelar roll
Digitala verktyg kan nu måla porträtt, landskap och abstrakta scener på sekunder, men många av dessa AI-verk ser fortfarande något felaktiga ut — färger kolliderar, texturer känns platta eller ”stilen” matchar inte riktigt vad man föreställer sig. Denna artikel presenterar ett nytt sätt att lära datorer skapa färgrika konstverk som är rikare, mer sammanhängande och närmare verkliga målningar, samtidigt som användare kan styra resultatet med enkla visuella ledtrådar som skisser och färgval. Målet är att göra AI till en mer pålitlig kreativ partner för konstnärer, formgivare och vanliga användare som vill ha personligt skapad konst utan att behöva års träning.
Från slumpmässigt brus till färdiga målningar
I hjärtat av studien finns en typ av AI som kallas Generative Adversarial Network, eller GAN. En GAN byggs av två motstående delar: en ”generator” som försöker producera trovärdiga bilder från slumpmässigt brus, och en ”diskriminator” som bedömer om en bild ser verklig eller falsk ut. Genom många omgångar av träning fram och tillbaka blir generatorn bättre på att lura diskriminatorn, och bilderna blir gradvis mer livsliknande. Författarna förstärker denna kärnidé genom att infoga en djup bildbehandlingsstack — kallad ett konvolutionellt neuralt nätverk — i både generatorn och diskriminatorn, så att systemet bättre kan fånga allt från breda former ned till fina, penselliknande detaljer.
Att lära systemet var det ska titta
Medan standard-GANs kan producera skarpa bilder missar de ofta helheten: de kan överbetona små detaljer och förlora global struktur, eller inte hålla en konsekvent konstnärlig stil. För att hantera detta lägger teamet till en adaptiv uppmärksamhetsmekanism. Denna modul analyserar generatorns interna featurekartor och lär sig, under träningen, vilka regioner i en bild som är viktigast vid varje ögonblick. Den förstärker sedan dessa nyckelområden — såsom kanter, texturer och fokala objekt — samtidigt som mindre viktiga bakgrundszoner mjukas upp. Särskilda förlustmått följer hur väl den genererade bilden matchar stilen och texturen i ett målverk, vilket driver modellen att balansera igenkännligt innehåll med ett sammanhängande konstnärligt uttryck.
Vägleda maskinen med visuella ledtrådar
Till skillnad från textbaserade system låter detta tillvägagångssätt människor styra konstverket med direkt visuell vägledning. Användare kan tillhandahålla en skiss för att definiera kompositionen, en färgpalett för att sätta stämningen, ett stilprov att efterlikna eller enkla scen-taggar. Dessa insatser går in i generatorn tillsammans med det slumpmässiga bruset. Modellen beräknar sedan färgegenskaper som ton, mättnad och ljusstyrka, och justerar sin output så att den slutliga målningen respekterar både användarens färgintentioner och referensstilen. Ett färgmatchande mål ytterligare stärker kopplingen mellan vad användaren anger och vad systemet producerar, så att en kall blå sjöscen inte oväntat förvandlas till en varm solnedgång, till exempel.
Lära sig att förbättra genom trial-and-error
Systemet går ett steg längre genom att använda djup förstärkningsinlärning, en teknik inspirerad av inlärning genom försök och misstag. Här behandlar en separat beslutsmodul gapet mellan aktuell output och den vägledande målsättningen som sitt ”tillstånd”, och föreslår små justeringar av element som skissstyrka eller palettvikter som sina ”aktioner”. Efter varje ändring mäter systemet hur mycket viktiga bildkvalitetspoäng förbättras — såsom peak signal-to-noise ratio, strukturell likhet och stilförlust — och använder detta som en belöningssignal. Med tiden lär denna loop en policy som automatiskt finjusterar vägledningen för att styra generatorn mot bilder som både är visuellt trogna och konstnärligt konsekventa.
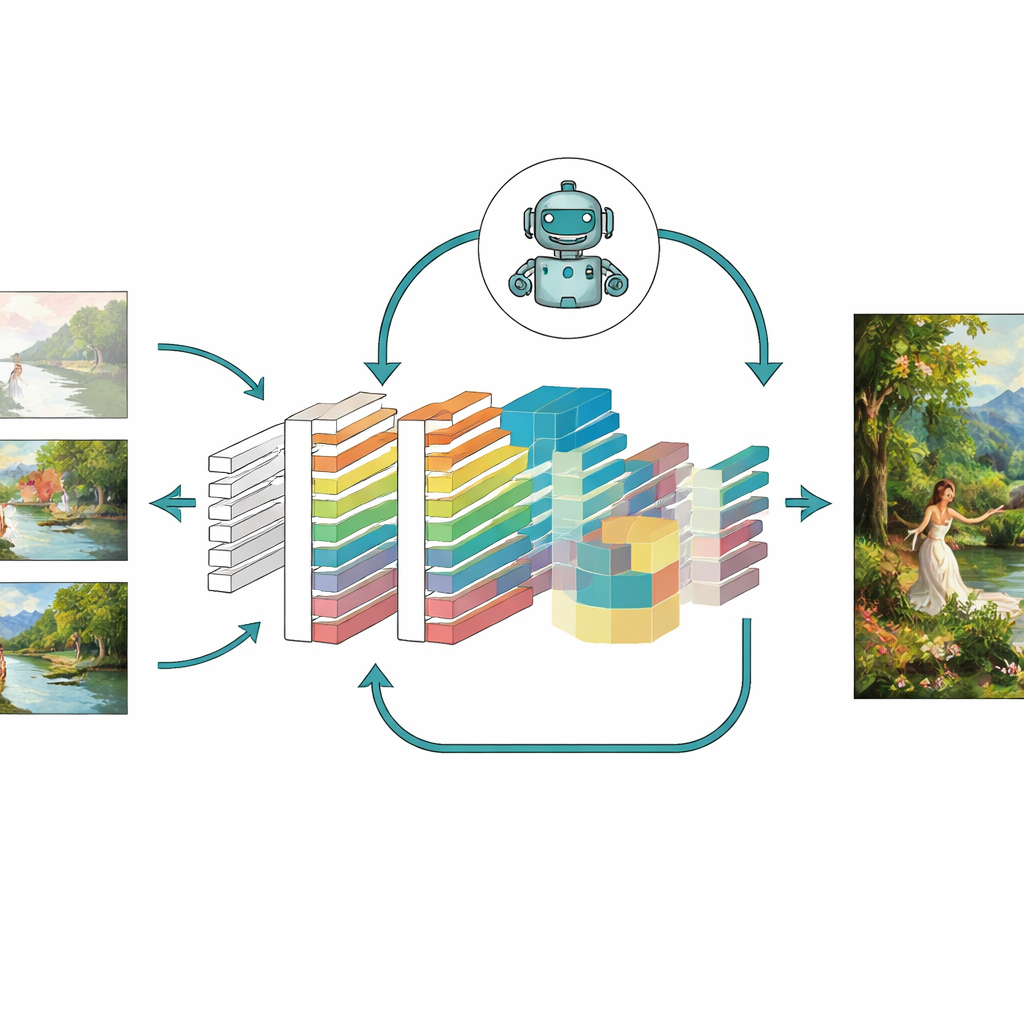
Sätta modellen på prov
För att avgöra om dessa idéer verkligen hjälper testade författarna sin förbättrade modell — kallad en CNN-GAN — på en stor samling målningar från University of Oxford och på en specialuppsättning med mer än 5 000 färgverk i stilar som porträtt, landskap och abstrakta scener. De jämförde resultat med flera välkända system, inklusive klassiska GAN-varianter, autoenkodare och till och med moderna diffusionsbaserade generatorer. Över många mått producerade den nya modellen skarpare bilder med färre artefakter, närmare strukturell matchning till verkliga konstverk, lägre perceptuell distans från målbilder och högre mångfald i de typer av scener den kunde generera. Ablationsstudier, där man tog bort en modul i taget, visade att uppmärksamheten, förstärkningsinlärningen och den kombinerade förlustdesignen var och en bidrog med meningsfulla förbättringar, och tillsammans gav de den starkaste prestandan.
Vad detta betyder för framtida kreativa verktyg
I vardagliga termer beskriver artikeln en målningsmaskin som inte bara lär sig från tusentals konstverk, utan också ägnar särskild uppmärksamhet åt viktiga regioner, lyssnar på användarens visuella ledtrådar och gradvis lär sig att justera dessa ledtrådar för bättre resultat. Resultatet är en AI som kan generera högkvalitativa, stilistiskt enhetliga bilder mer tillförlitligt än tidigare metoder, samtidigt som den lämnar utrymme för mänsklig styrning. Även om systemet fortfarande har svårigheter med extremt invecklade texturer och är beroende av betydande träningsdata, föreslår författarna framtida utvidgningar — såsom multiskaliga moduler och lättare nätverk — för att göra det mer effektivt och allmänt användbart. Tillsammans pekar dessa framsteg mot AI-konstverktyg som är snabbare, mer trogna användarens avsikt och bättre på att fånga den subtila karaktären i människoskapat måleri.
Citering: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Nyckelord: AI-konstgenerering, bildstilöverföring, generativa adversariella nätverk, artificiell kreativitet, neurals bildsyntes