När regeringar, forskare eller opinionsmätare försöker ta reda på något om en hel population—som genomsnittsinkomst, skörd eller föroreningsnivåer—kan de sällan mäta alla individer. Istället tar de ett urval och skalar upp. Detta fungerar väl endast om data uppför sig väl. I verkligheten är dock undersökningar och mätningar ofta fyllda av fel och extrema värden som kan snedvrida resultaten kraftigt. Denna artikel presenterar ett nytt sätt att beräkna populationsmedelvärden som förblir tillförlitligt även när data är röriga, vilket gör beslut baserade på undersökningar mer pålitliga.
När enkla medelvärden går fel
Standardverktyg för att skatta ett populationsmedelvärde, som det rena stickprovsmedelvärdet eller ordinär regression, antar att de flesta datapunkter följer mjuka mönster utan extrema avvikare eller ovanliga fall. I sociala och ekonomiska undersökningar, miljöövervakning och jordbruksstatistik uppfylls ofta inte den förhoppningen. Några felaktiga mätningar, sällsynta men extrema händelser eller felrapporterade svar kan dra uppskattningarna bort från sanningen och öka både bias och osäkerhet. Tidigare arbete har försökt mildra effekten av sådana avvikare med så kallade robusta metoder, inklusive en populär metod känd som Huber M-skattning. Även om dessa metoder är hjälpsamma skyddar de främst mot extrema värden i den utfallande variabeln och är fortfarande sårbara för ovanliga mönster i den medföljande förklarande informationen.
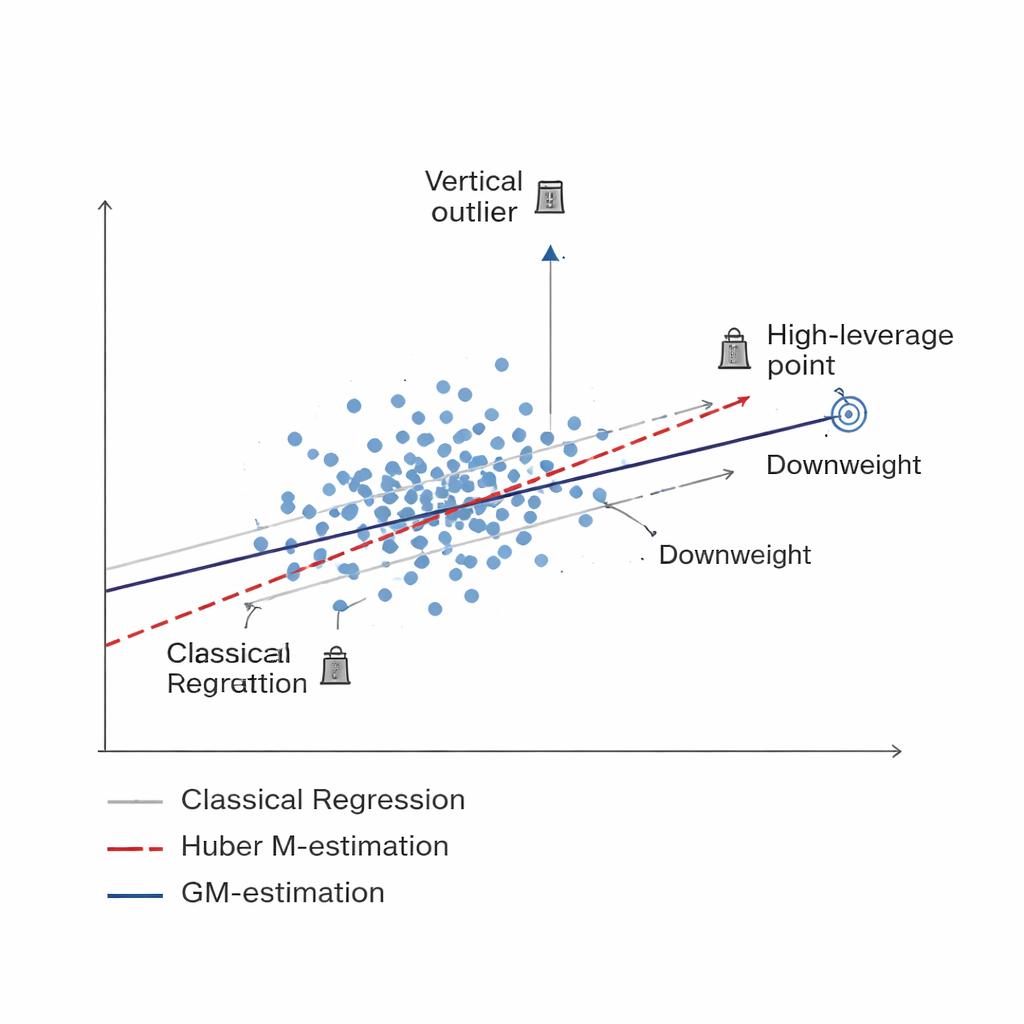
En smartare metod för att nedvikta dåliga data Figure 1.
Studien utvecklar en ny familj av estimatorer byggda på Generalized M-estimation, eller GM-skattning. Istället för att behandla varje insamlad enhet lika, tilldelar GM-metoder adaptiva vikter som beror på två saker samtidigt: hur extrem en enhets svar är (en vertikal avvikare) och hur ovanlig dess associerade information är (en hög-leverage punkt). Tre specifika versioner—kallade Mallows-GM, Schweppes-GM och SIS-GM—är utformade för vanliga undersökningsupplägg, inklusive enkelt slumpmässigt urval utan återläggning och mer komplexa stratifierade designers där populationen är uppdelad i relativt homogena grupper. Genom att gemensamt kontrollera båda typerna av problematiska observationer syftar dessa estimatorer till att hålla den slutliga uppskattningen av populationsmedelvärdet stabil även när data innehåller allvarlig kontaminering.
Sätta de nya estimatorerna på prov
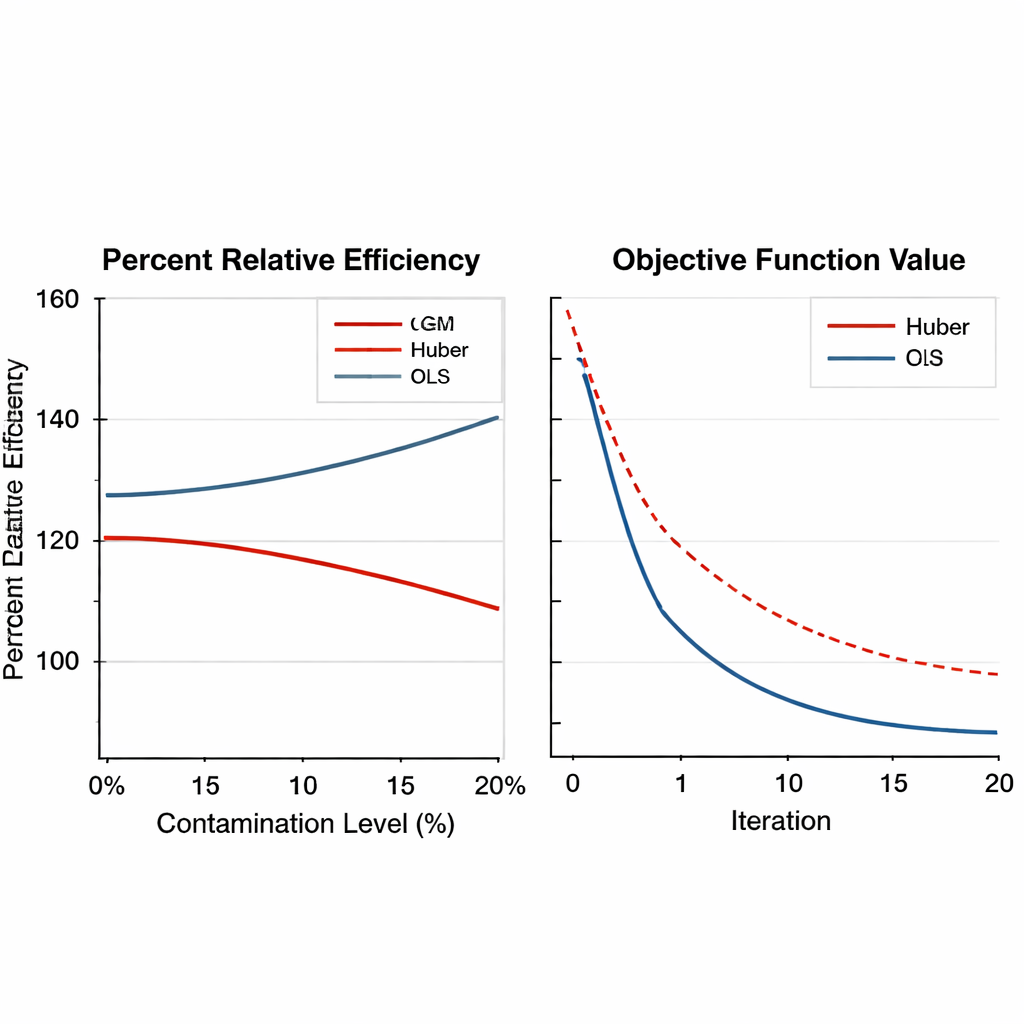
För att se hur väl de GM-baserade estimatorerna fungerar genomför författaren omfattande numeriska experiment. Först analyseras verkliga data från tobaksjordbruk i två former: en ren version och en avsiktligt kontaminerad version där en enhet ersätts med extrema värden. De nya estimatorerna jämförs med traditionell regression och Huber-baserade robusta metoder med hjälp av ett mått kallat procentuell relativ effektivitet, vilket speglar hur mycket mindre skattningsfelet är. Över ett brett spann av stickprovsstorlekar presterar GM-estimatorerna konsekvent bättre än de äldre metoderna, särskilt när datan innehåller extrema värden. I vissa scenarier minskar den bäst presterande GM-estimatorn felet med mer än 50 procent jämfört med Huber-metoden.
Robusthet över designer, miljöer och justeringsval Figure 2.
Artikeln breddar sedan testerna med storskaliga datorsimuleringar. Konstgjorda populationer genereras under flera former—normala, snedvridna och tungsvansade fördelningar—och kontamineras med varierande andel avvikare, från ingen upp till 20 procent. Både enkla och stratifierade urvalsplaner beaktas, och styrkan i sambandet mellan huvudvariabeln och dess hjälpare varieras från svagt till starkt. GM-estimatorerna bibehåller inte bara sin fördel vid kraftig kontaminering, ofta med effektivitetsvinster över 150 procent, utan visar också jämn och pålitlig numerisk konvergens. Viktigt är att deras prestanda förändras lite när de interna justeringsinställningarna ändras inom rimliga intervall, vilket innebär att praktiker inte behöver finjustera dem noggrant för varje ny undersökning.
Vad detta betyder för verkliga undersökningar
Enkelt uttryckt visar artikeln att de föreslagna GM-baserade estimatorerna ger ett säkrare sätt att omvandla ofullkomliga stickprov till uppskattningar av populationsomfattande medelvärden. Under ideala, rena datavillkor är de ungefär lika träffsäkra som klassiska metoder. Men när data innehåller mätfel, felrapporterade värden eller sällsynta extrema händelser—vilket är vanligt i nationella undersökningar, miljöövervakning och finansiell statistik—levererar de avsevärt mer tillförlitliga svar. Eftersom de är beräkningsmässigt genomförbara och fungerar väl över olika designer och inställningar erbjuder dessa estimatorer praktiker inom undersökningsfältet en praktisk uppgradering som kan göra evidensbaserade beslut mer motståndskraftiga mot den oundvikliga rörigheten i verkliga data.
Citering: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5