Clear Sky Science · sv
Exakt generering av utskrivningssammanfattningar med finjusterade stora språkmodeller och självvärdering
Varför pappersarbete på sjukhuset verkligen spelar roll
När en patient lämnar sjukhuset tar inte sjukdomens berättelse slut vid utgångsdörren. Läkare på andra kliniker, allmänläkare och patienterna själva förlitar sig alla på ett nyckeldokument kallat utskrivningssammanfattning för att förstå vad som hände på sjukhuset och vad som bör göras härnäst. Att skriva dessa sammanfattningar är dock långsamt och repetitivt arbete som kan ta upptagna kliniker en halvtimme eller mer per patient. Denna studie undersöker hur moderna AI-språkverktyg kan hjälpa till att utarbeta utskrivningssammanfattningar snabbare och mer korrekt, samtidigt som patientdata hålls privata och under sjukhusets kontroll.
Att förvandla utspridda journaler till en tydlig berättelse
Sjukhusinformation är utspridd över många elektroniska system: laboratorieresultat i en tabell, operationsanteckningar i en annan, omvårdnadsobservationer i en tredje, och så vidare. Varje patients vårdtid genererar tusentals små textstycken. Forskarna byggde först en pipeline för att förvandla denna utspridda, röriga information till ett rent input som en AI-modell kan förstå. Genom metoder för att slå ihop och ta bort dubbletter av överlappande poster, filtrera bort privata uppgifter såsom namn och ID:n, rätta stavfel och standardisera medicinska termer skapade de strukturerat input för varje vårdtillfälle. Denna process tillämpades på data från mer än 6 000 patienter som genomgått sköldkörteloperationer på ett stort kinesiskt sjukhus, vilket gav parvisa exempel på verkliga utskrivningssammanfattningar och de rådata som de skrevs från. 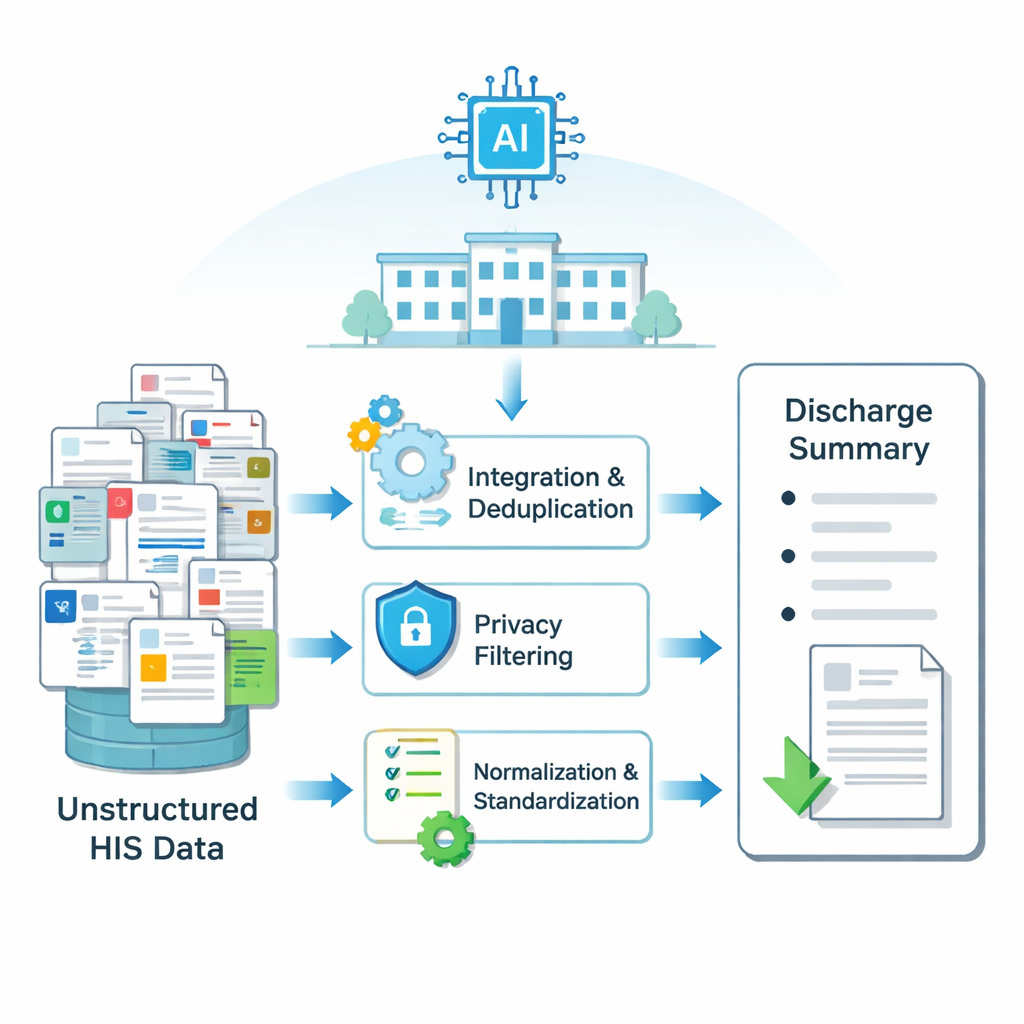
Finjustera AI för att tala medicinens språk
Färdiga stora språkmodeller är tränade på allmän text från internet och böcker, så de har ofta svårt med specialiserat medicinskt språk och lokala dokumentationsstilar. Teamet jämförde flera sätt att "finjustera" befintliga modeller så att de bättre förstår kinesiska medicinska journaler. En ny metod kallad vikt-dekomponerad låg-rank-anpassning, eller DoRA, justerar modellens interna vikter på ett mer riktat sätt än äldre tekniker såsom LoRA och QLoRA. Över olika modeller, inklusive Qwen2, Mistral och Llama 3, producerade DoRA konsekvent sammanfattningar som var mer flytande, närmare människoskrivna i betydelsen och mindre förvirrade (mätt med en standardmetrik kallad perplexity). I praktiken hjälpte DoRA AI:n att lära sig medicinsk formulering och terminologi utan att behöva full omlärning på massiv hårdvara.
Att lära AI att dubbelkolla sitt eget arbete
Även en vältränad modell kan glömma viktiga detaljer eller införa mindre fel när den skriver en lång sammanfattning i ett svep. Inspirerade av psykologiska idéer om snabba "System 1"-tankar kontra långsammare, mer noggrann "System 2"-resonemang designade författarna en självvärderingsloop. Först skriver modellen en initial utskrivningssammanfattning från de bearbetade sjukhusdata. Sedan bryts de ursprungliga uppgifterna ner i segment—såsom patologifynd, läkarordinationer eller laboratoriepaneler—och varje segment paras om med utkastet. Modellen frågas i praktiken: "Är allt i detta segment reflekterat i sammanfattningen?" Om inte reviderar den texten för att lägga till saknad eller inkonsekvent information. Denna cykel upprepas upp till tre gånger eller tills modellen bedömer sammanfattningen som komplett, vilket ger en förfinad version som mer troget matchar patientens journal. 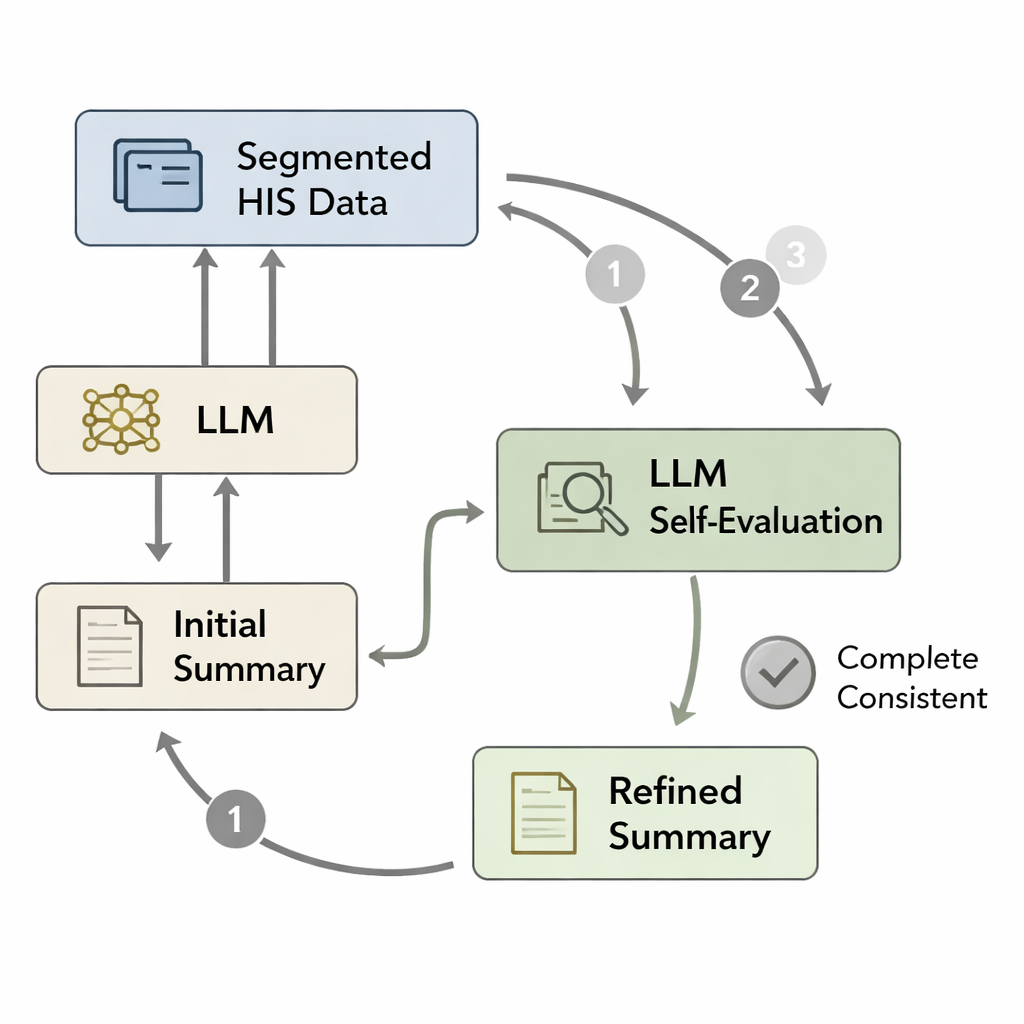
Hur bra klarade sig AI jämfört med människor?
För att bedöma kvalitet använde teamet både automatiska poäng och mänskliga granskare. Läkare och medicinska forskare bedömde sammanfattningar utifrån noggrannhet, fullständighet, tydlighet, konsekvens och användbarhet för fortsatt vård. Det bästa systemet—som kombinerade DoRA-finjustering med självvärderingsloopen—kom närmast människoskrivna sammanfattningar i alla avseenden. Det förbättrade särskilt fullständigheten, vilket innebar färre missade diagnoser, behandlingar eller viktiga laboratorievärden. I ett detaljerat exempel glömde AI:n initialt att nämna en liten sköldkörtelcancer och en specifik hormonpill; efter två självvärderingspass lades båda detaljerna korrekt till. I genomsnitt genererade systemet en utskrivningssammanfattning på cirka 80 sekunder på en sjukhusserver, jämfört med 30–50 minuter för en kliniker att utarbeta en från grunden, även om mänsklig granskning fortfarande är avgörande innan texten går in i den officiella journalen.
Vad detta kan betyda för patienter och kliniker
Studien visar att med noggrann träning och inbyggd självkontroll kan AI-system producera utskrivningssammanfattningar som är tillräckligt korrekta för att betraktas som kliniskt acceptabla efter en snabb mänsklig kontroll. Detta ersätter inte läkare, men det kan flytta deras tid från rutinmässigt skrivande till mer högre nivåns granskning och beslutsfattande. Genom att hålla all beräkning inom sjukhusets nätverk och ta bort identifierande uppgifter respekterar tillvägagångssättet också patientens integritet. Även om resultaten hittills kommer från en avdelning på ett sjukhus pekar ramen mot en framtid där AI hjälper till att förvandla komplex medicinsk data till klara, tillförlitliga berättelser över många specialiteter, vilket stödjer säkrare överlämningar i vården och bättre förståelse för patienter och familjer.
Citering: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Nyckelord: utskrivningssammanfattningar, medicinsk AI, stora språkmodeller, klinisk dokumentation, självvärdering