Clear Sky Science · sv
Geolokalisering av sociala användare baserat på K-medoids och Gaussiskt kernel graph attention-nätverk
Varför dina tweets kan avslöja var du bor
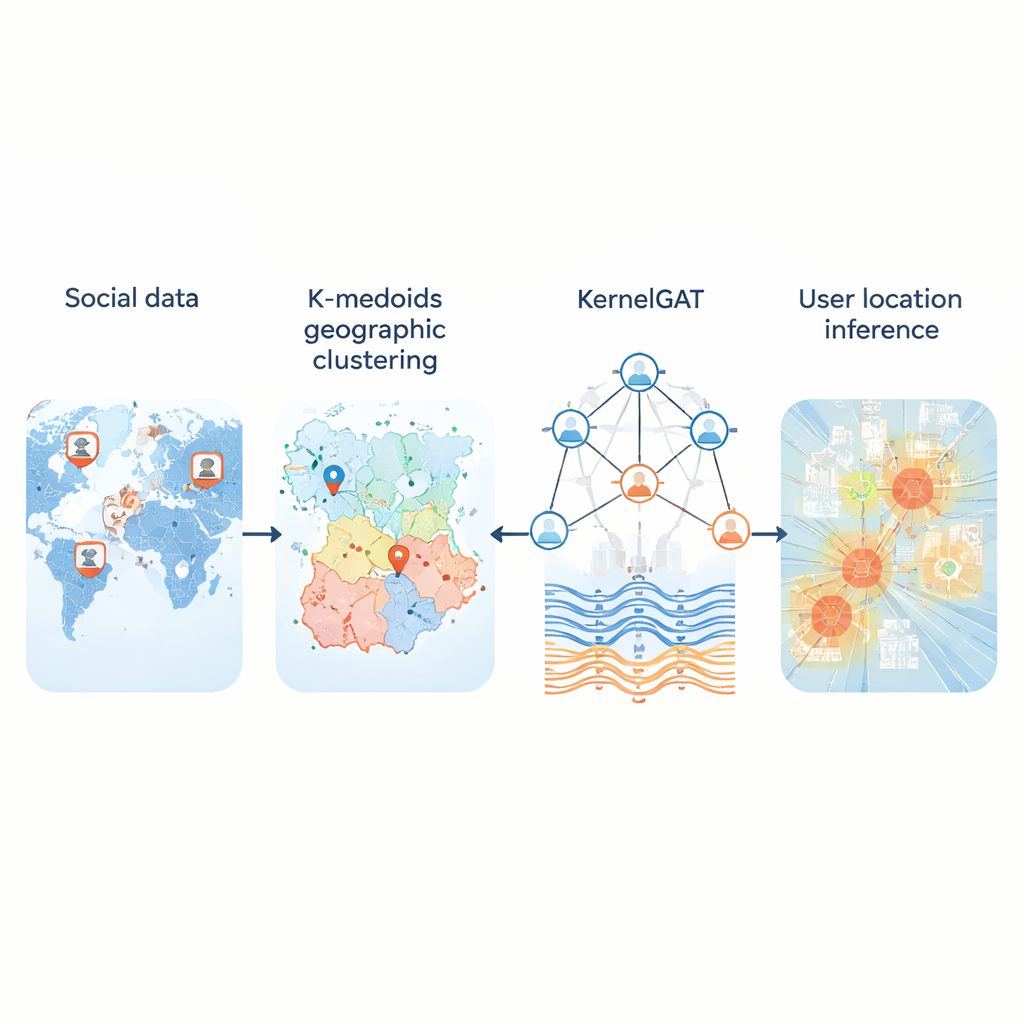
Varje dag postar miljontals människor på sociala medier utan att dela sina GPS-koordinater. Ändå lämnar dessa inlägg ledtrådar om var användare bor, arbetar och reser. Att kunna härleda plats från detta offentliga spår är viktigt för allt från krisinsatser och smittspårning till lokala rekommendationer och riktade tjänster. Denna artikel presenterar en ny metod, kallad KMKGAT, som använder både vad människor skriver och hur de är kopplade online för att uppskatta var de befinner sig — mer exakt än tidigare tillvägagångssätt.
Från onlineprat till verkliga platser
När användare skriver tweets eller mikrobloggar kan de nämna platser, använda lokalt språkbruk eller interagera med närliggande vänner. Företag som Twitter (numera X) känner till en användares internetadress, men externa forskare och tjänsteleverantörer har vanligtvis inte den informationen. Istället måste de arbeta med offentlig information: själva texten, användarprofiler och vem som pratar med vem. Tidigare metoder hamnade i tre läger. Innehållsbaserade metoder grävde i ord och hashtags för att gissa platser. Nätverksbaserade metoder förlitade sig på att människor tenderar att interagera med användare i närheten. Ett tredje, mer kraftfullt spår kombinerade båda vyerna, men hade fortfarande blindzoner — särskilt för personer i glesbefolkade områden och för användare vars onlinekontakter spänner över stora avstånd.
Smartare geografisk gruppering med verkliga användarcentra
Ett nyckelproblem är hur man översätter den kontinuerliga jordytan till en uppsättning regioner som en dator kan lära sig att förutsäga. Många system delar upp kartan i ett fast rutnät. Det fungerar hyfsat i städer men misslyckas på landsbygden, där enorma rutor kan täcka flera hundra kilometer. Den nya metoden ersätter stela rutnät med k-medoids-klustring, ett sätt att gruppera användare så att varje region är centrerad på en verklig användare istället för en konstgjord punkt. Det gör regionerna mer kompakta och mindre känsliga för avvikare, särskilt där användarna är glest fördelade. I tester på tre stora Twitter-dataset som täcker USA och världen minskade denna adaptiva indelning typiska fel jämfört med rutnätsbaserade scheman och gav mer realistiska ”hemregioner” för användarna.
Låta nätverket fokusera på närliggande, liknande användare
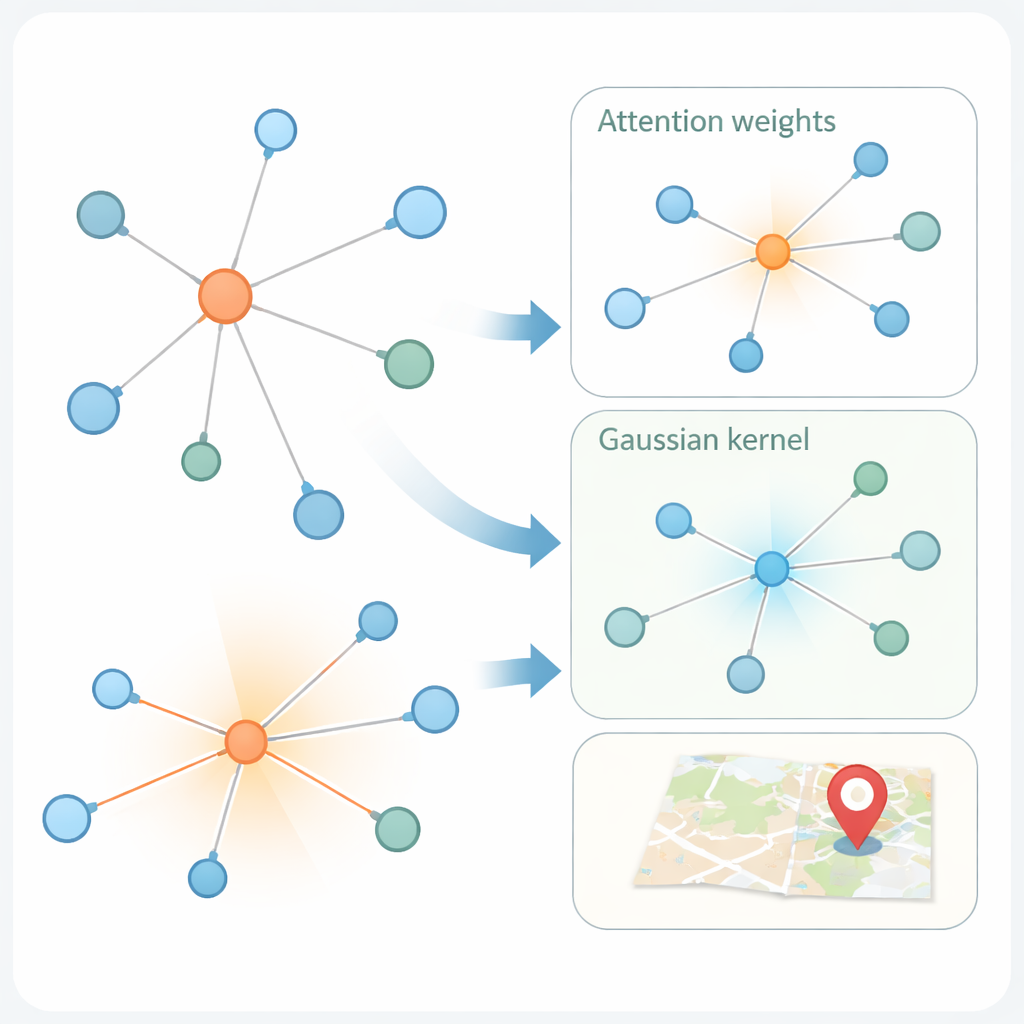
Den andra innovationen ligger i hur modellen lär från den sociala grafen. Moderna ”graph attention networks” väger redan en användares grannar olika, baserat på hur lika deras funktionsrepresentationer är. Men likhet kan vara vilseledande: ett konto i New York och ett annat i London kan använda liknande språk men vara långt ifrån varandra geografiskt. KMKGAT kompletterar uppmärksamheten med en Gaussisk kernel, ett matematiskt filter som gynnar grannar vars lärda representationer är nära målpersonen och dämpar inflytandet från avlägsna. Flera sådana kernelar, kombinerade som en blandning av linser, tillåter modellen att fånga lokalitet i olika skalor. Detta respekterar den enkla men kraftfulla principen att onlineinteraktioner ofta är starkare bland människor som är fysiskt närmare varandra.
Lätta textfunktioner som ändå bär platsledtrådar
I stället för att förlita sig på tunga djupa språkmodeller, som kan ha problem med tweets bullriga, slangfyllda stil, använder författarna en klassisk teknik kallad TF–IDF för att omvandla varje användares samling inlägg till en påse med viktade nyckelord. Vanliga ord som ”the” eller ”lol” får liten vikt, medan mer sällsynta, regionsspecifika termer klättrar uppåt. Dessa textfunktioner fästs sedan vid varje användare i den sociala grafen och skickas genom det förbättrade attention-nätverket. Intressant nog gav bäst resultat när de flesta textfunktionerna slumpmässigt släpptes under träning, vilket antyder att endast en liten andel av orden faktiskt hjälper till med platsbestämning och att resten mestadels lägger till brus.
Slår state-of-the-art i skala
För att bedöma prestanda mätte forskarna hur långt, i kilometer, den förutsagda regionens centrum låg från varje användares kända koordinater, samt hur stor andel användare som placerades inom 161 km (100 miles) från sin verkliga plats. Över tre benchmark-Twitter-dataset matchade eller överträffade KMKGAT konsekvent starka befintliga system och förbättrade noggrannheten inom 161 kilometer med upp till några procentenheter — en meningsfull förbättring på denna mognadsnivå. Vinsterna var tydligast i små och medelstora nätverk, medan metoden på en massiv global graf begränsades av att man under träning bara kunde sampla omedelbara grannar.
Vad detta betyder i vardagliga termer
För icke-specialister är slutsatsen att det blir alltmer möjligt att uppskatta var användare på sociala medier befinner sig, även om de aldrig delar en platsflagga. Genom att gruppera användare i realistiska regioner baserat på verkliga konton, och genom att lära modellen att främst lita på närliggande, liknande grannar i det sociala nätverket, kan KMKGAT begränsa var någon sannolikt bor eller postar ifrån. Det kan hjälpa räddningsinsatser att hitta människor vid katastrofer, förbättra lokal sökning och rekommendationer och stödja studier av hur information sprids över platser. Samtidigt belyser det hur mycket våra vanliga onlineinteraktioner kan avslöja om vårt offlineliv, vilket understryker vikten av genomtänkt dataanvändning och integritetsskydd.
Citering: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Nyckelord: geolokalisering i sociala medier, Twitter-användares plats, graf-neurala nätverk, platsbaserade tjänster, online integritet