Clear Sky Science · sv
Intentklassificering för universitetsadministrativa tjänster med en tvåvägs återkommande neuronnätmodell modifierad av en utvecklad Kepler-optimeringsalgoritm
Smartare digital hjälp för vardagliga campusfrågor
Universitetsstudenter förväntar sig nu snabba, korrekta svar när som helst — vare sig de ansöker om antagning, registrerar sig på kurser eller frågar om ekonomiskt stöd. Denna artikel undersöker en ny typ av AI-driven chattbot utformad särskilt för universitetsadministrativa tjänster, med fokus på att hantera både engelska och grekiska. Genom att lära ett enda system att bättre förstå vad studenter menar och vilka detaljer som är viktiga, vill författarna göra digitala hjälpdesk-tjänster snabbare, mer pålitliga och enklare att driva.
Varför dagens chattbotar fortfarande blir förvirrade
De flesta moderna chattbotar bygger på ett område som kallas natural language understanding, vilket delar upp en students fråga i två huvuddelar. Först är intent: vad studenten vill göra, till exempel ”registrera sig på en kurs” eller ”fråga om en sista anmälningsdag”. För det andra finns entities: de konkreta informationsbitarna i frågan, som en kurskod, termin eller programnamn. Traditionella system använder separata modeller för dessa två uppgifter. Den uppdelningen slösar minne och beräkningskraft och kan leda till inkonsekventa svar — till exempel att korrekt hitta en kurskod men misslyckas med att koppla den till rätt handling. Dessa problem blir värre i flerspråkiga miljöer, där samma idé kan uttryckas på många olika sätt mellan språk.
Ett huvud i stället för två
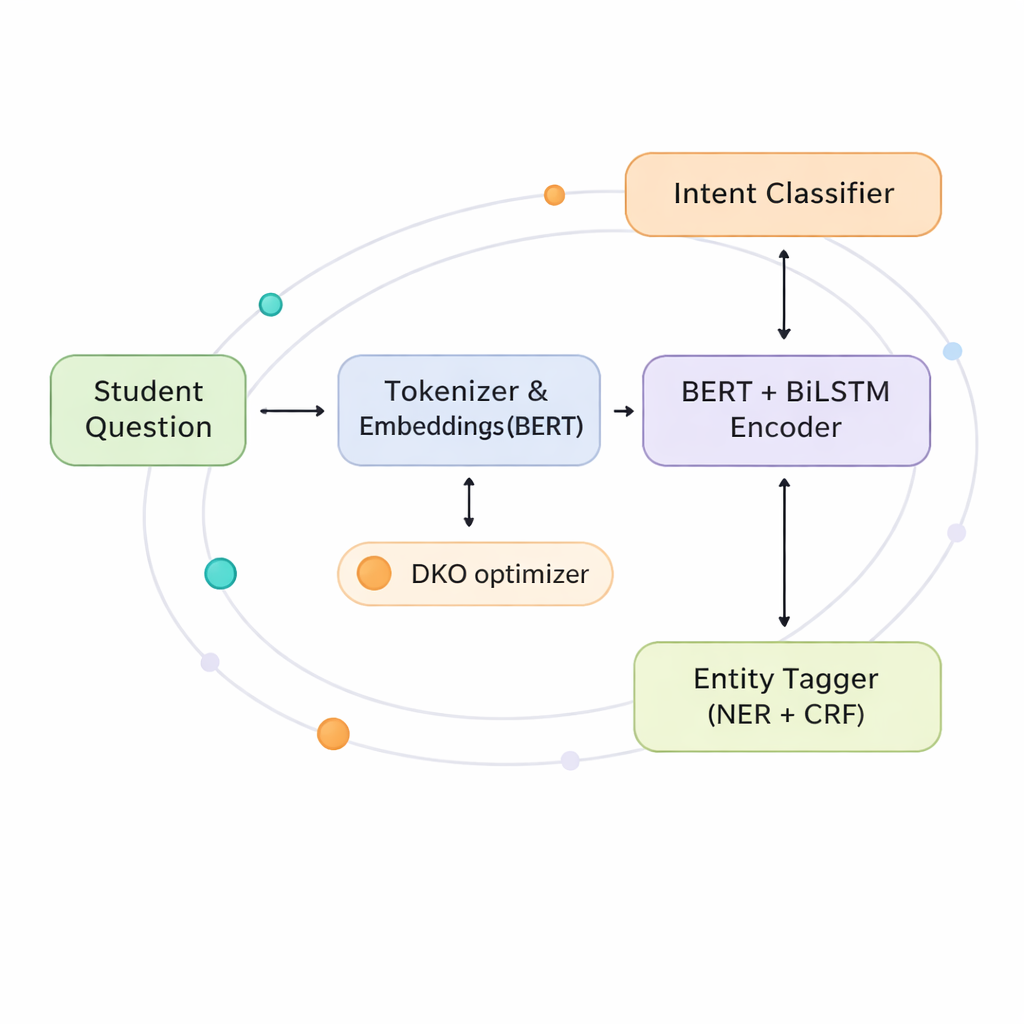
Författarna föreslår en gemensam modell som lär sig att känna igen både intents och entities samtidigt, med en delad ”hjärna” i stället för två separata. I kärnan kombineras två kraftfulla tekniker. Den första, BERT, ser på hela meningen på en gång för att fånga dess övergripande innebörd. Den andra, ett tvåvägs LSTM-nätverk, uppmärksammar ordens ordning både från vänster till höger och från höger till vänster, vilket hjälper det att följa närliggande samband, till exempel vilken kurs som hör ihop med vilken termin. Ovanpå denna delade förståelse grenar systemet ut i två huvuden: ett som förutsäger studentens intent och ett som märker varje ord med dess roll som entity eller inte.
Låta uppgifter prata med varandra
För att få ut det mesta av denna delade hjärna inkluderar modellen ett lager kallat ”co-interactive transformer” som låter de två uppgifterna informera varandra i realtid. När systemet avgör en intent kan det titta på de entities det tror finns; när det märker entities kan det förlita sig på vilken intent som verkar mest sannolik. Denna korskommunikation hjälper till att lösa tvetydigheter, som om ”drop” avser att lämna en kurs eller att avbryta en ansökan, och är särskilt värdefull i grekiska, där böjningar och ordföljd är mer flexibla än på engelska. Genom att dela representationer och uppmärksamhet på detta sätt minskar modellen antalet parametrar med nästan hälften jämfört med att köra två stora modeller separat, vilket gör den mer praktisk för universitets IT-avdelningar.
En kosmiskt inspirerad metod för att träna modellen
Att träna en sådan rik modell är svårt: standardmetoder för optimering kan vara långsamma och känsliga för finjusterade inställningar. Författarna introducerar Developed Kepler Optimization (DKO)-algoritmen, inspirerad av hur planeter kretsar runt solen. I denna analogi är olika versioner av modellen som planeter som utforskar rymden av möjliga parameterinställningar samtidigt som de dras mot den bäst presterande ”solen”. DKO startar dessa kandidater i en mer diversifierad spridning än vanligt och justerar sedan kontinuerligt deras ”banor” baserat på hur väl de presterar. Detta tillvägagångssätt påskyndar inlärningen med ungefär 42 procent jämfört med en populär metod kallad Adam, samtidigt som träningen blir mer stabil, särskilt för komplexa, flerspråkiga data.
Verklighetstester med studenter
Teamet utvärderade sitt system på flera dataset, inklusive UniWay, en samling engelska och grekiska frågor om universitetsservice, och xSID, en välkänd benchmark för förståelse av korta kommandon. I samtliga tester överträffade den gemensamma modellen konsekvent regelbaserade system, äldre neurala nätverk och även starka transformerbaser. I fälttester vid två universitet — ett enbart engelskt och ett tvåspråkigt — identifierade chattboten korrekt studenternas intents och entities i ungefär nio av tio fall, och studenterna gav sitt nöjdhetsbetyg till cirka 4,5 av 5. Prestandan förblev stark även när träningsdata minskades, vilket tyder på att metoden är robust i språk och domäner med färre resurser.
Vad detta betyder för studenter och universitet
För en lekman är huvudbudskapet att författarna har designat en mer effektiv och exakt ”lyssningsmotor” för universitetschattbotar. Genom att förena intentsdetektion och detalj-extraktion, och genom att använda en bana-inspirerad träningsmetod, kan deras system bättre greppa vad studenter frågar efter samtidigt som det använder mindre minne och träningstid. Detta kan ge snabbare svar, färre missförstånd och dygnet-runt flerspråkigt stöd utan att överbelasta personalen. Även om utmaningar återstår — såsom att anpassa sig till nya riktlinjer, fler språk och långsiktiga användarmönster — pekar arbetet mot campus-hjälpsystem som känns mer responsiva, rättvisa och skalbara.
Citering: Yang, Z., Lu, M. & Huang, S. Intent classification for university administrative services using a bidirectional recurrent neural network modified by a developed Kepler optimization algorithm. Sci Rep 16, 6263 (2026). https://doi.org/10.1038/s41598-026-35504-7
Nyckelord: universitetschattbotar, intentsklassificering, namngiven entity-igenkänning, flerspråkig AI, optimeringsalgoritmer