Clear Sky Science · sv
Automatiserad identifiering av kontextuellt relevanta biomedicinska entiteter med grundade LLM:er
Varför smartare taggning av medicinska artiklar är viktig
Varje år publiceras tusentals biomedicinska studier, fyllda med detaljer om gener, celltyper, sjukdomar och behandlingar. Ändå förblir det mesta av denna information inlåst i långa PDF-filer, vilket gör det svårt för andra forskare att hitta exakt de data de behöver. Den här artikeln undersöker hur modern artificiell intelligens — stora språkmodeller, eller LLM:er — automatiskt kan plocka ut dessa viktiga biomedicinska termer från forskningsartiklar och på så vis hjälpa till att förvandla spridda publikationer till välorganiserade, sökbara resurser.
Från röriga artiklar till sökbara byggstenar
Biomedicinska forskningscentra, som Tysklands Collaborative Research Centers, är beroende av tydliga, strukturerade data för att göra studier återanvändbara under många år. Traditionellt har forskare behövt manuellt märka sina dataset med viktiga entiteter såsom organismer, cellinjer och gener — en mödosam och tidskrävande uppgift. LLM:er kan läsa fullständiga artiklar och förstå kontext, vilket gör dem till lovande verktyg för att automatisera denna taggning. Men det finns en hake: att avgöra vilka termer som verkligen är relevanta beror på den vetenskapliga frågan och hur data ska återanvändas. Författarna arbetar inom ett noggrant utformat metadataschema från det nefrologifokuserade CRC ”NephGen”, som talar om för AI vad för slags entiteter den ska leta efter och hur de ska organiseras.
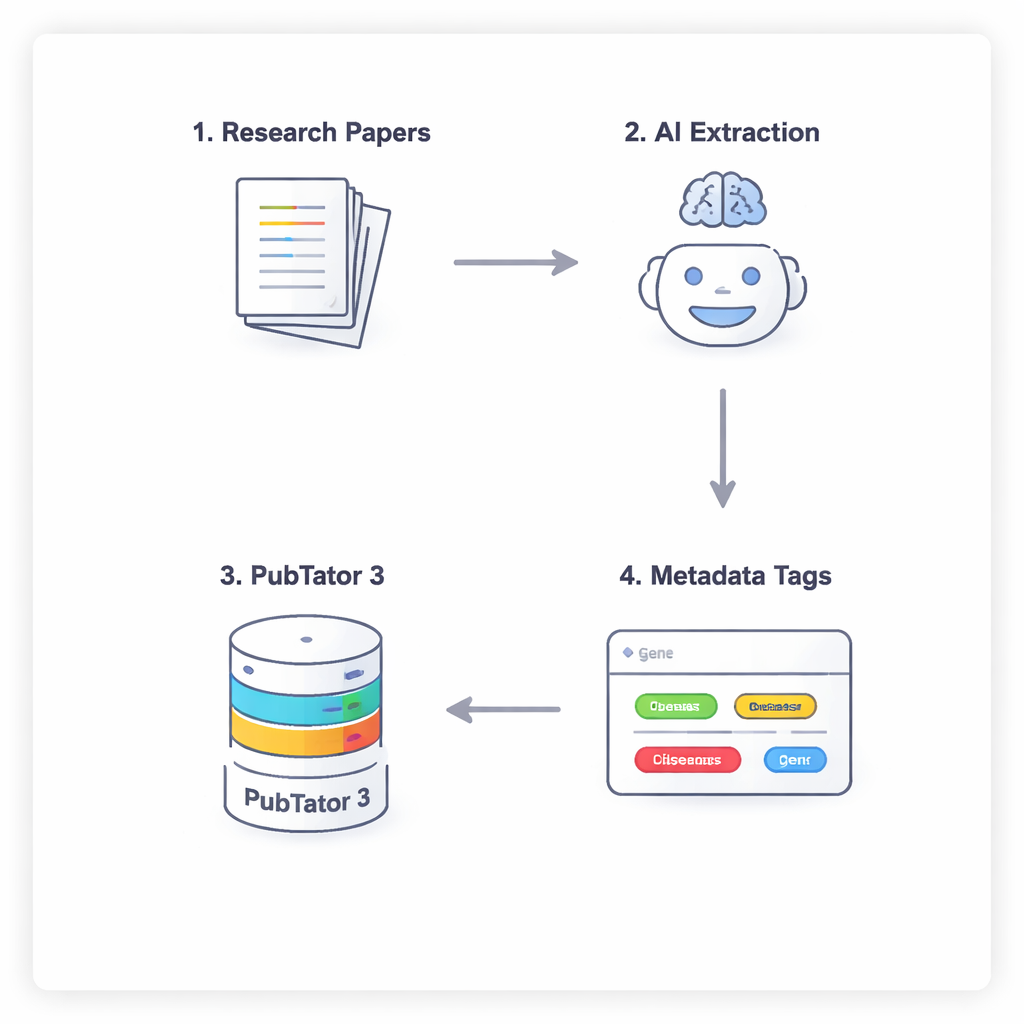
En fyrastegs konversation mellan AI och en biologidatabas
För att hindra AI från att gissa eller ”hallucinera” biomedicinska fakta använder forskarna en fyrastegsprocess som tvingar modellerna att resonera noggrant och dubbelkolla sig själva. Först skannar modellen hela texten i en artikel (med undantag för diskussion och referenser) för att föreslå potentiellt relevanta entiteter. För det andra måste den konsultera ett externt verktyg, PubTator 3, en stor biomedicinsk databas, för att bekräfta att varje föreslagen term faktiskt existerar och har en erkänd identifierare. För det tredje tilldelar AI varje bekräftad entitet en plats i NephGen-metadataschemat, som grupperar entiteter i en hierarkisk, människodesignad struktur. Slutligen konsoliderar modellen allt detta till en strukturerad JSON-utdata — i praktiken en prydlig maskinläsbar sammanfattning av artikels viktigaste biomedicinska entiteter.
Test av åtta AI-modeller med verklig njurforskning
Gruppen implementerade detta arbetsflöde med API:er för 14 olika LLM:er och fann att endast åtta konsekvent kunde följa de strikta kraven, såsom att returnera giltig JSON och korrekt använda verktyg. De applicerade sedan dessa åtta modeller på sex nefrologiska forskningsartiklar och bad varje artikels författare att granska AI:ns slutliga lista över entiteter i en kort, ansikte-mot-ansikte-intervju. Eftersom det inte finns något fast ”korrekt” antal entiteter att extrahera fokuserade författarna på precision: vilken andel av de föreslagna entiteterna som forskarna bedömde vara korrekta. Med statistiska meta-analysmetoder anpassade för proportioner nära 100 % uppskattade de precisionen för varje modell samtidigt som de tog hänsyn till variation mellan artiklar.
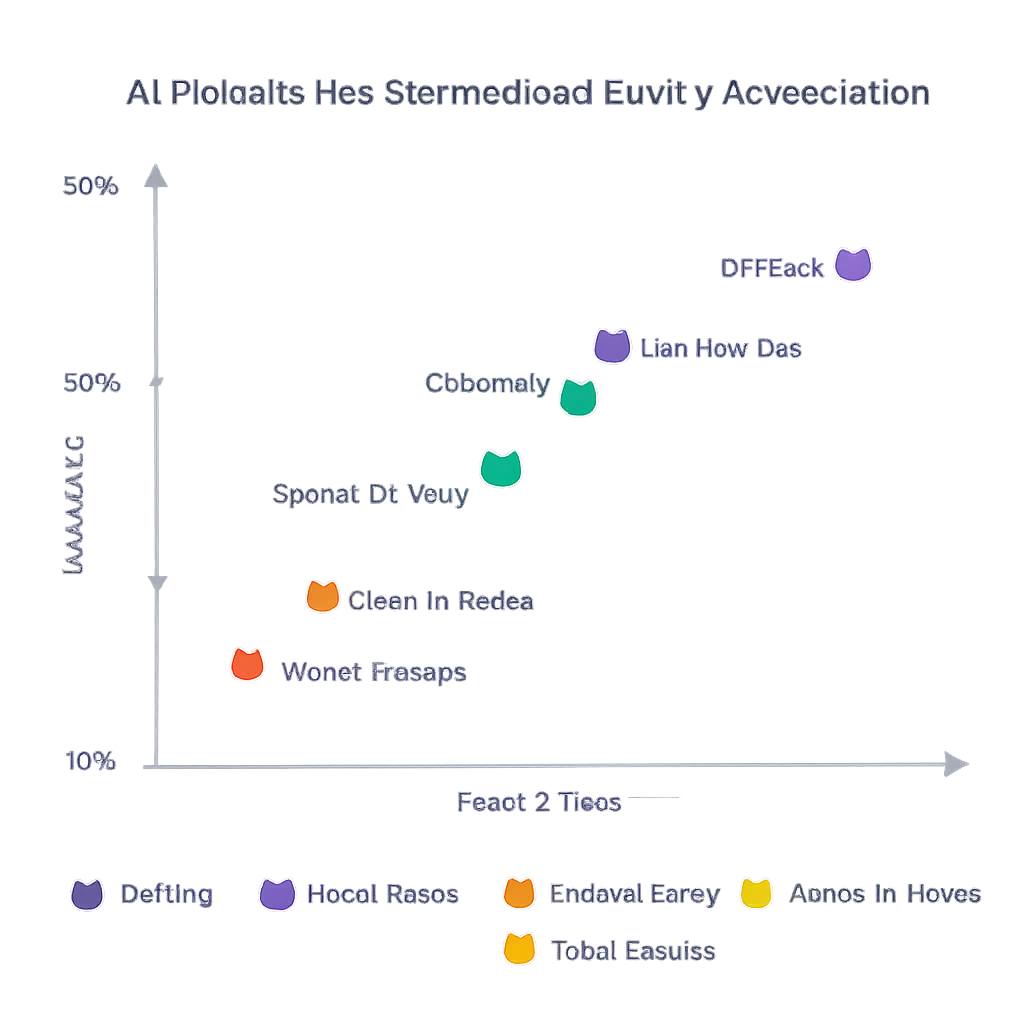
Hög noggrannhet, men avvägningar i ansträngning, kostnad och hastighet
Över alla modeller uppnådde systemen en total precision på cirka 91 %, vilket betyder att majoriteten av de föreslagna entiteterna bedömdes som korrekta. GPT-4.1, GPT-4o Mini och Gemini 2.0 Flash hade högst precision — ungefär 94 % till 98 % — även om skillnaderna inte var statistiskt tydliga. Gemini-modellerna tenderade att föreslå fler entiteter totalt, vilket gav fler korrekta taggar men också mer för människor att kontrollera. Några mindre eller billigare modeller, som GPT-4.1 Nano, var snabbare och billigare men avsevärt mindre precisa. Författarna visualiserade dessa spänningar med Pareto-frontier, och identifierade kombinationer av modeller som balanserade precision, antal korrekta entiteter, kostnad och bearbetningstid: till exempel framstod GPT-4o Mini som särskilt attraktiv när både noggrannhet och låga kostnader är prioriterade.
Varför människor fortfarande behövs i arbetsflödet
Trots goda prestanda lyfter studien fram viktiga begränsningar. Modellerna blandade ibland ihop information om den publicerade artikeln med detaljer som egentligen inte var relevanta för det underliggande dataset som framtida användare kan vilja återanvända. Denna förvirring speglar en större utmaning i automatiserad textutvinning: vetenskapliga artiklar diskuterar långt mer än vad som faktiskt ingår i ett delat dataset. Författarna rekommenderar därför att mänskliga experter fortsätter att granska AI-genererade annoteringar innan de publiceras. De noterar också att deras utvärdering täcker endast sex nefrologiska artiklar, så bredare tester över fält krävs. Med tiden kan ett rutinmässigt ”human-in-the-loop”-arbetsflöde bygga upp ett konsensusreferensset, vilket gör det möjligt att mäta inte bara precision utan också hur många entiteter AI missade.
Vad detta betyder för framtida delning av biomedicinska data
Studien visar att moderna LLM:er, när de vägleds noggrant och grundas i betrodda databaser, pålitligt kan hjälpa till att annotera biomedicinska artiklar och därigenom kraftigt minska det manuella arbetet för forskare. De bästa modellerna närmar sig expertlik precision samtidigt som de erbjuder olika avvägningar mellan noggrannhet, kostnad och hastighet. För närvarande är mänsklig granskning fortsatt väsentlig för att säkerställa att annoteringarna verkligen överensstämmer med dataset och forskningskontext. Men i takt med att verktyg och öppen källkodsmotorer mognar kan arbetsflöden som detta bli en standardryggrad för att förvandla dagens flod av medicinska artiklar till morgondagens välorganiserade, återanvändbara datakommuner.
Citering: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Nyckelord: biomedicinsk textutvinning, stora språkmodeller, metadatabearbetning, grundad AI, nefrologiforskning