Clear Sky Science · sv
Kombinera parameterfragmentering och gruppblandning för att försvara mot opålitlig server i federerat lärande
Varför det är viktigt att skydda delade modeller
Våra telefoner, sjukhus och banker drivs i allt större utsträckning av artificiell intelligens. Ofta vill flera organisationer träna en gemensam modell tillsammans, men lagar och sunt förnuft säger att de inte får samla sina rådata på ett och samma ställe. Federerat lärande uppfanns för att lösa denna spänning: varje deltagare tränar på sin egen enhet och delar endast modelluppdateringar. Men denna artikel visar att även dessa uppdateringar kan läcka privat information om den centrala servern är nyfiken eller oärlig — och presenterar därefter ett nytt sätt att göra både våra data och våra identiteter säkrare.
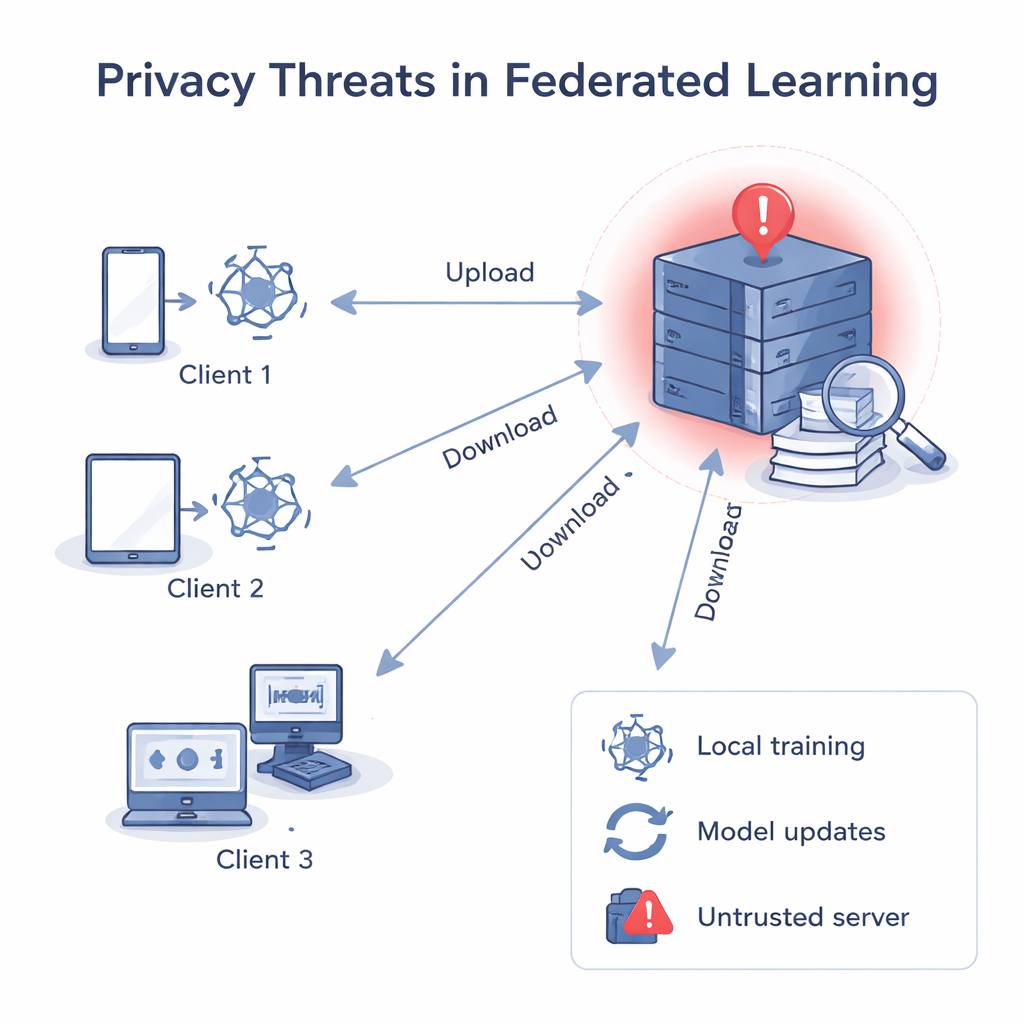
När servern inte bör vara betrodd
I klassiskt federerat lärande skickar en central server ut en gemensam modell, varje klient förbättrar den med sina egna data och skickar sedan tillbaka den uppdaterade modellen. Servern genomsnittar dessa uppdateringar till en förbättrad global modell. Även om rådata aldrig lämnar enheterna har tidigare forskning visat att gradienter och vikter — talen inuti modellen — kan ”köras baklänges” för att rekonstruera privat data, såsom bilder eller text, eller för att avgöra om en viss post användes i träningen. Om den centrala servern inte är pålitlig kan den analysera varje klients uppdatering separat, lära sig om klientens lokala data och till och med koppla en uppdatering till en viss person eller organisation.
Bryta upp uppdateringar i ofarliga bitar
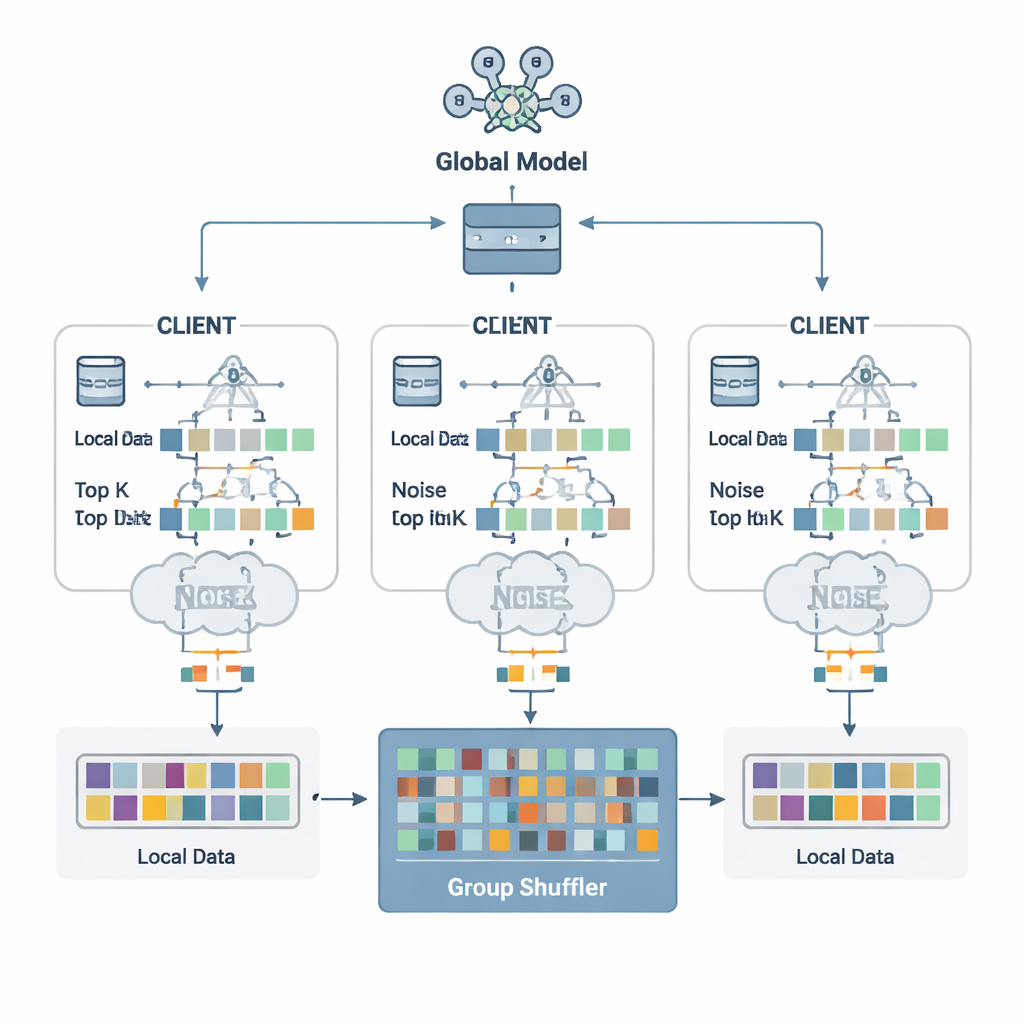
Författarna föreslår en försvarsschema kallat Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). Den första idén är enkel men kraftfull: skicka aldrig en komplett uppdatering. Istället delar varje klient sin modelluppdatering i flera konstgjorda ”fragment”. De flesta av dessa fylls med slumptal, och endast det sista justeras så att alla fragment fortfarande summerar till den verkliga uppdateringen. Ett enskilt fragment, eller till och med flera av dem, ser ut som brus och avslöjar nästan ingenting om ursprungsdatan. Denna matematiska trick liknar hemlig delning: endast genom att kombinera alla delar kan man återfå helheten.
Lägga till brus och röra om i grytan
Att skicka många fragment kan fortfarande vara ineffektivt och, om de granskas tillsammans, kunna låta en angripare dra slutsatser. För att undvika detta väljer varje klient endast de viktigaste fragmentvärdena — Top‑K posterna som betyder mest för inlärningen — och lägger till noggrant kalibrerat slumpbrus till dem enligt principerna för differential privacy. Detta brus gör det statistiskt svårt att avgöra om någon enskild persons data påverkade ett visst värde. Därefter kommer den andra nyckelingrediensen: gruppblandning. Istället för att skicka fragment direkt till servern vidarebefordrar klienter dem till en betrodd ”blandare” som mixar fragment från många klienter i grupper innan de skickas vidare. Efter denna mixning kan servern inte längre avgöra vilket fragment som kom från vilken klient, vilket bryter länken mellan uppdateringar och identiteter.
Behålla noggrannhet samtidigt som läckor minskas
Teamet testade SDPFGS på vanliga bild- och textbenchmarkar, inklusive handskrivna siffror (MNIST), klädannonser (Fashion‑MNIST) och färgbilder (CIFAR‑10 och CIFAR‑100), samt en nyhetsklassificeringsuppgift. De jämförde sin metod med flera toppmoderna integritetstekniker som använder enbart brus, enbart blandning eller enkel gradientkomprimering. I dessa experiment matchade eller överträffade SDPFGS konsekvent noggrannheten hos konkurrerande metoder samtidigt som det använde mindre kommunikation och kortare träningstid än många av dem. Särskilt under modellinversionsattacker — där en angripare försöker återskapa träningsexempel — hade SDPFGS den lägsta framgångsgraden för attacker, vilket betyder att den läckte minst om de underliggande data.
Vad detta betyder för vardagsanvändare
För en lekman är huvudbudskapet att ”gömma datan” inte räcker; vi måste också dölja vad våra enheter skickar under träning. SDPFGS gör detta genom att förvandla varje modelluppdatering till brusiga, blandade fragment som är värdelösa var för sig men ändå kan kombineras till en högkvalitativ global modell. Resultatet är en starkare sköld mot en nyfiken eller komprometterad server, med endast måttlig kostnad för noggrannhet och effektivitet. När federerat lärande sprids inom vård, finans och smarta enheter kan tekniker som SDPFGS bidra till att människor drar nytta av kraftfulla delade modeller utan att överlämna nycklarna till sina privatliv.
Citering: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Nyckelord: federated learning, datasekretess, differential privacy, modellinversionsattacker, säker aggregering