Clear Sky Science · sv
Oenighet mellan mänsklig och AI-utvärdering av behandlingsplaner
Varför detta är viktigt för vardaglig medicinsk vård
När artificiella intelligensverktyg (AI) börjar hjälpa läkare att välja behandlingar uppstår en central fråga: vems omdöme kan vi lita mest på — människors eller maskiners? Denna studie undersöker en enkel men oroande möjlighet: att läkare och AI-system inte bara kan vara oense om vilken behandling som är bäst, utan även om vad som räknas som en "bra" behandlingsplan överhuvudtaget. Att förstå detta glapp är avgörande om vi vill att AI ska stödja, snarare än tyst förvränga, verkliga medicinska beslut.
En direkt jämförelse av behandlingsråd
Forskarnas fokus låg på dermatologi, ett område där läkare hanterar långvariga hudbesvär som sällan har ett enda "korrekt" svar. Tio erfarna dermatologer och två stora språkmodeller (LLM)—en allmänmodell och en resonemangsinriktad modell—bad man var att skriva behandlingsplaner för fem utmanande, fiktiva fall, såsom svår eksem, psoriasis med samtidig sjukdom och graviditetsrelaterad akne. För att göra det rättvist redigerades alla 60 planer till ett gemensamt format: liknande längd, struktur och ton. Alla tydliga ledtrådar om huruvida en människa eller AI skrivit planen togs bort, så att senare bedömare skulle bedöma innehåll och inte stil.
Hur människor och AI gjorde bedömningarna
Planerna genomgick sedan två omgångar blindpoängsättning med samma bedömningsmall. Först betygsatte samma grupp av tio dermatologer varje plan på en skala från 0 till 10 utifrån övergripande kvalitet, med hänsyn till hur effektiv, säker, praktisk och patientcentrerad den var. Därefter poängsatte en separat AI-modell—använd bara som domare, inte som planförfattare—de exakt samma planerna med samma instruktioner. Avgörande var att varken de mänskliga bedömarna eller AI-domaren visste vem som skrivit någon given plan. Denna uppställning gjorde det möjligt för författarna att isolera en nyckelfaktor: om utvärderaren var människa eller AI.
Människor stöder människor, AI stöder AI
Resultaten visade en tydlig "utvärderareffekt." När människor betygsatte planerna gav de högre poäng till planer skrivna av deras kollegor än till de som skrivits av något av AI-systemen. De mänskligt framtagna planerna hade ett något högre genomsnittsbetyg och intog de fem översta placeringarna i rankningen. En av AI-modellerna, den avancerade resonemangsmodellen, hamnade nära botten. Men när AI-domaren tog över vände bilden. Nu avancerade de två AI-skrivna planerna till toppen av listan, och varje människodermatologs plan föll under dem. I genomsnitt gav AI-domaren högre poäng åt AI-genererade planer än åt människogenererade, även om den läste exakt samma standardiserade text som dermatologerna sett.
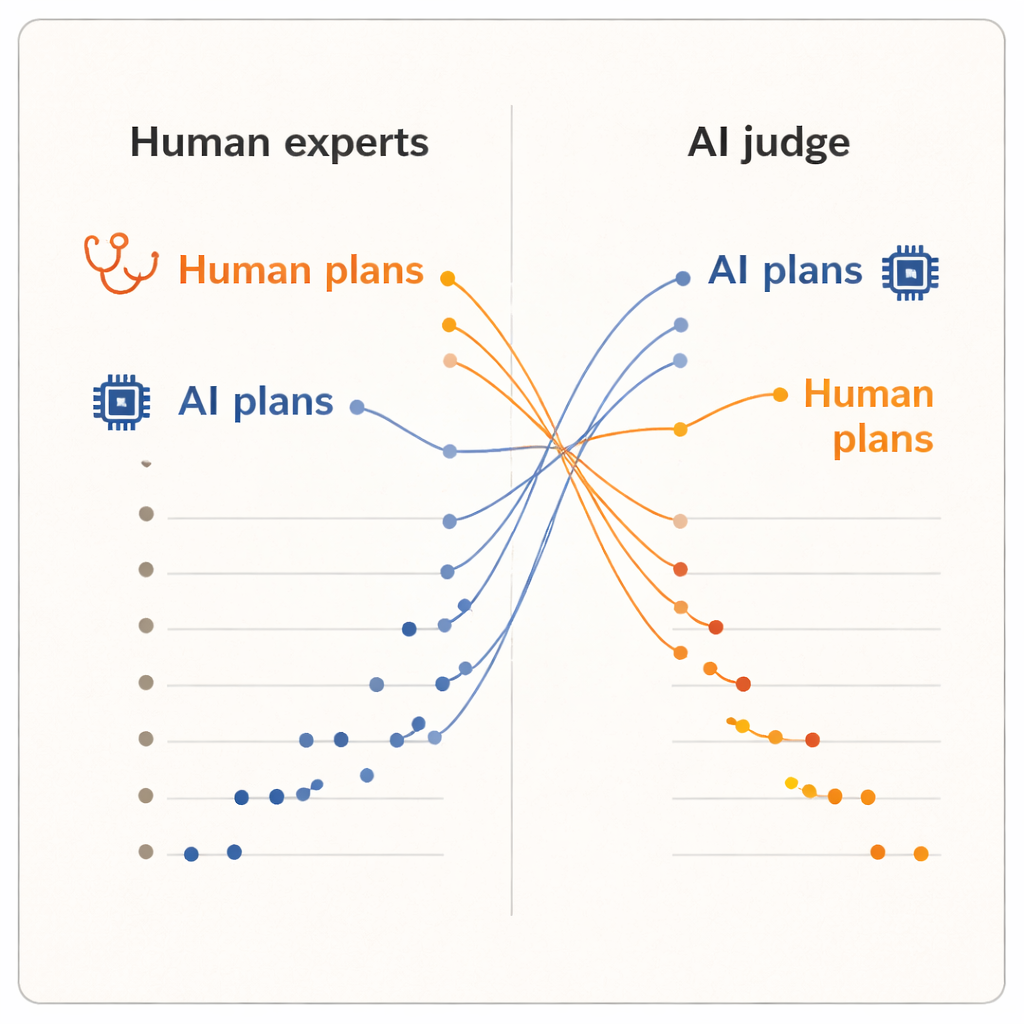
Olika uppfattningar om vad som gör en "bra" plan
Eftersom planerna normaliserades vad gäller ordval och domarna hölls blinda för källan menar författarna att denna delning inte kan förklaras av ytlig polering. Snarare tyder det på att människor och AI-system använder olika interna måttstockar. Kliniker lutar sannolikt mot verklighetserfarenhet: vad som brukar vara genomförbart i deras kliniker, hur patienter reagerar och vilka avvägningar som känns acceptabla i praktiken. AI-domaren, tränad på stora textmängder, kan däremot föredra planer som följer mönster vanliga i medicinsk litteratur eller riktlinjer, även om dessa mönster inte fullt ut fångar lokala begränsningar eller patientpreferenser. Studien är modest i omfattning — bara tio kliniker, fem fall och en enda AI-domare — och den mäter upplevd kvalitet, inte faktiska patientutfall. Ändå är vändningen tillräckligt iögonfallande för att väcka djupare frågor om hur vi utvärderar klinisk AI.
Ompröva hur vi testar och använder klinisk AI
Av dessa fynd drar författarna två breda slutsatser. För det första missar traditionella "rätt-svar"-tester för medicinsk AI mycket av det som är viktigt i verklig vård, där planer måste balansera effektivitet, säkerhet, kostnad, logistik och patientens önskemål. De argumenterar för rikare, multimetriska utvärderingsramverk som uttryckligen poängsätter dessa dimensioner, använder flera mänskliga och AI-domare och analyserar var och varför oenigheter uppstår istället för att slå ihop allt till en enda poäng. För det andra föreslår de att skillnader mellan mänskliga och AI-bedömningar kan vara en egenskap, inte bara en bugg. Om de används varsamt kan AI-genererade planer fungera som en genomtänkt second opinion som får läkare att ompröva sina antaganden, medan läkare tillför den verkliga kontexten och etiska omdömen som AI saknar. Att bygga pålitliga, transparenta gränssnitt som blottlägger antaganden, låter kliniker justera prioriteringar och inbjuder till kritisk granskning kan hjälpa till att omvandla denna spänning mellan mänskliga och AI-perspektiv till säkrare, mer balanserade beslutsprocesser.
Citering: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Nyckelord: kliniskt beslutsstöd, artificiell intelligens inom medicin, människa-AI-samarbete, behandlingsplanering, utvärderingsbias