Clear Sky Science · sv
En hybrid förutsägelsemodell för PM2.5‑koncentration baserad på högfrekventa och lågfrekventa IMF:er med EMD‑dekomposition
Varför renare luftprognoser spelar roll i vardagen
Finkorniga partiklar i luften, kända som PM2.5, är så små att de kan tränga djupt ner i våra lungor och till och med nå blodomloppet. I norra Kina, där tung industri och vinteruppvärmning är koncentrerade, når dessa partiklar ofta nivåer som kan föranleda hälsovarningar, störa transporter och till och med stänga fabriker och skolor. Denna studie ställer en mycket praktisk fråga: kan vi förutse tim‑för‑tim PM2.5‑nivåer mer exakt, så att städer och invånare får tidigare och mer tillförlitliga varningar innan luften blir hälsofarlig?
En närmare titt på norra Kinas smutsiga luft
Forskarna fokuserade på sex större städer i norra Kina: Peking, Tianjin, Shijiazhuang, Taiyuan, Jinan och Zhengzhou. Dessa städer representerar tätbefolkade, industrialiserade områden där föroreningshändelser är frekventa, särskilt på vintern. Med hjälp av officiella övervakningsdata samlade teamet timvisa PM2.5‑avläsningar för hela året 2021, vilket gav 8 760 datapunkter för varje stad. De fann att föroreningsnivåerna varierade stort mellan städerna; till exempel hade Taiyuan den högsta genomsnittliga PM2.5‑halten, medan Peking hade den lägsta. Extremhändelser var slående: i Taiyuan steg koncentrationerna till 652 mikrogram per kubikmeter under ett damm‑ och föroreningsutbrott i mars, vilket pressade luftkvalitetsindexet till dess högsta nivå — ett tydligt tecken på allvarlig luftförorening.
Varför det är så svårt att förutsäga PM2.5
PM2.5‑nivåerna påverkas samtidigt av många krafter — lokala utsläpp från trafik och fabriker, regional transport av damm och rök, vindhastighet, luftfuktighet och mer. Som ett resultat beter sig föroreningskurvan mindre som en jämn linje och mer som ett ojämnt, rastlöst hjärtslag. Traditionella statistiska verktyg eller moderna neurala nätverk kan ha svårt med den här typen av data: de kan fånga den övergripande trenden men missa plötsliga toppar, eller fungera i en stad men misslyckas i en annan. Tidigare studier försökte förbättra prognoserna antingen genom att lägga in mer fysisk detalj (såsom kemiska transportmodeller) eller genom att enbart förlita sig på sofistikerade maskininlärningsmetoder. Den här artikeln kombinerar istället flera metoder, var och en vald för att hantera en annan "rytm" i datan.
Att dela signalen i snabba och långsamma rytmer
Det centrala steget är en teknik kallad empirisk modedecomposition (EMD), som bryter ner den ursprungliga PM2.5‑tidsserien i flera enklare komponenter. Några av dessa komponenter svänger snabbt och fångar kortsiktiga toppar och brus; andra ändras långsamt och speglar den underliggande trenden. Författarna grupperar de första fem komponenterna som "högfrekventa" delar och de återstående, plus ett residualt trendled, som "lågfrekventa" delar. De högfrekventa delarna, som är mer oregelbundna och starkt icke‑linjära, matas in i ett LSTM‑nätverk (long short‑term memory), en typ av djupinlärningsmodell som är väl lämpad att lära sig mönster över tid. De jämnare, lågfrekventa komponenterna går till en klassisk tidsseriemetod känd som ARIMA, vilken är effektiv när datan beter sig mer regelbundet och nära linjärt.
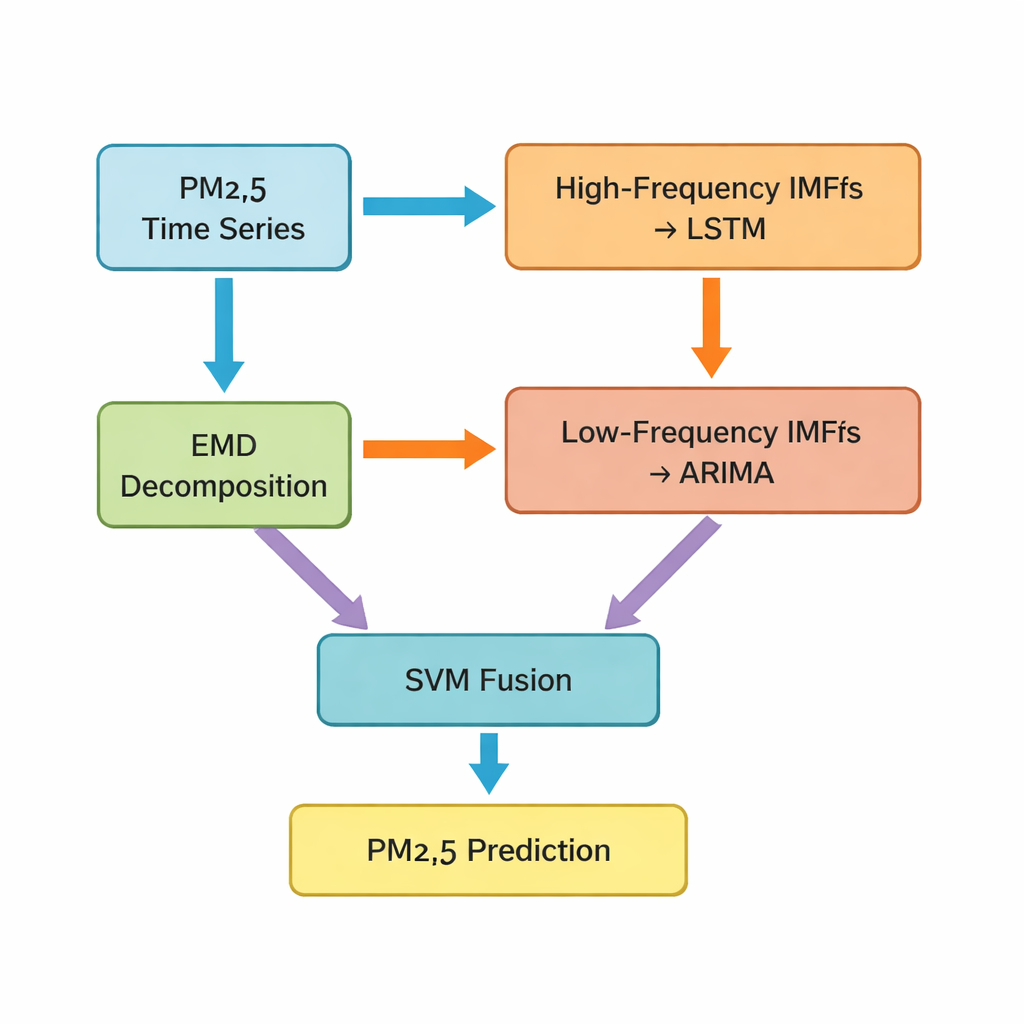
Att blanda olika modeller till en smartare prognos
När LSTM‑ och ARIMA‑modellerna vardera producerar sina delprognoser återstår en utmaning: hur man slår ihop dessa separata förutsägelser till ett slutgiltigt, bästa gissningsvärde för PM2.5 nästa timme. För detta använder författarna en supportvektormaskin (SVM), en annan maskininlärningsmetod som lär sig hur de två insatserna ska viktas och kombineras. I praktiken fungerar SVM:en som en domare som avgör när den "snabba" bilden (högfrekventa mönster) är viktigare och när den "långsamma" bilden (långsiktiga trender) ska dominera. Det kombinerade systemet, som författarna kallar Hybrid‑EMDHL, utvärderas därefter med flera prestandaindikatorer, inklusive genomsnittligt fel, hur väl prognoserna matchar observerade värden och hur bra modellen fångar förändringsriktningen — om nivåerna stiger eller sjunker.
Tydligare varningar och bättre planering
Den hybrida modellen presterar bättre än någon av dess huvudkomponenter var för sig i samtliga sex städer. Den minskar inte bara genomsnittliga och kvadrerade fel utan förbättrar också avsevärt förmågan att korrekt förutse om PM2.5 kommer att stiga eller falla nästa timme — en avgörande egenskap för att utfärda snabbhälsovarningar. I många fall halverar den hybrid‑baserade metoden felmåtten jämfört med en enskild neuronnätsmodell, och dess "riktningsexakthet" överstiger 0,69, vilket betyder att den i klart över två tredjedelar av testfallen korrekt förutsäger trenden. För en lekman innebär detta väderliknande luftkvalitetsprognoser som är både skarpare och mer pålitliga. För stadsplanerare och hälsomyndigheter erbjuder det ett praktiskt verktyg för att stödja riktade, tidiga åtgärder — såsom att justera industriverksamhet eller trafikregler — innan en föroreningshändelse når sin kulmen, vilket hjälper till att minska exponering och skydda vardagslivet i några av Kinas mest förorenade urbana områden.
Citering: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Nyckelord: PM2.5‑prognoser, luftföroreningar, Norra Kina, maskininlärning, tidsserieuppdelning