Clear Sky Science · sv
QPSODRL: en förbättrad kvantpartikelsvärmsoptimering och djup förstärkningsinlärningsbaserad intelligent klustrings- och routningsprotokoll för trådlösa sensornätverk
Smartare sensornät för en uppkopplad värld
Från precisionsjordbruk till varningssystem vid katastrofer övervakar trådlösa sensornät tyst vår omvärld och samlar in data från hundratals eller tusentals små enheter utspridda över stora områden. Deras största svaghet är också deras kännetecken: varje sensor drivs av ett litet batteri som är svårt eller omöjligt att byta ut. Denna artikel presenterar ett nytt sätt att organisera och styra dataflödet i dessa nätverk så att batterierna räcker längre, informationen färdas mer pålitligt och nätverket anpassar sig när förhållandena förändras.
Varför små enheter behöver stor intelligens
I ett trådlöst sensornät kan varje nod mäta, beräkna och kommunicera, men energi är en bristvara. Om vissa noder gör för mycket arbete dör de tidigt och skapar ”döda zoner” där ingen data kan samlas in. För att undvika detta grupperar man ofta noder i kluster. Inom varje kluster blir en nod klusterhuvud: den samlar in mätningar från sina grannar och vidarebefordrar dem mot en central basstation. Att välja vilka noder som ska bli klusterhuvuden och hur data ska hoppa genom nätverket är ett komplicerat pussel som förändras när batterierna urladdas. Traditionella regelbaserade eller enstaka-algoritmlösningar tenderar ofta att snabbt fastna i suboptimala mönster eller misslyckas när nätverkets topologi och energinivåer utvecklas över tid.
Att blanda kvantinspirerade svärmar med lärande maskiner
Denna studie introducerar QPSODRL, ett protokoll som förenar två kraftfulla idéer: en kvantinspirerad svärmsmetod för att bilda kluster och en djup förstärkningsinlärningsmotor för routning. I det första steget utforskar virtuella ”partiklar” olika sätt att tilldela klusterhuvuden och medlemmar. Deras beteende styrs av ett mått på hur jämnt energin är fördelad i nätverket, känt som entropi. När energianvändningen är obalanserad uppmuntrar algoritmen bred utforskning av nya klusterlayouter; när läget ser stabilt ut finjusterar den lovande arrangemang. Ett särskilt steg med ”elitstörning” skjuter ibland de bästa kandidaterna i nya riktningar, vilket hjälper sökningen att undkomma lokala återvändsgränder och undvika överanvändning av samma högenergianoder. 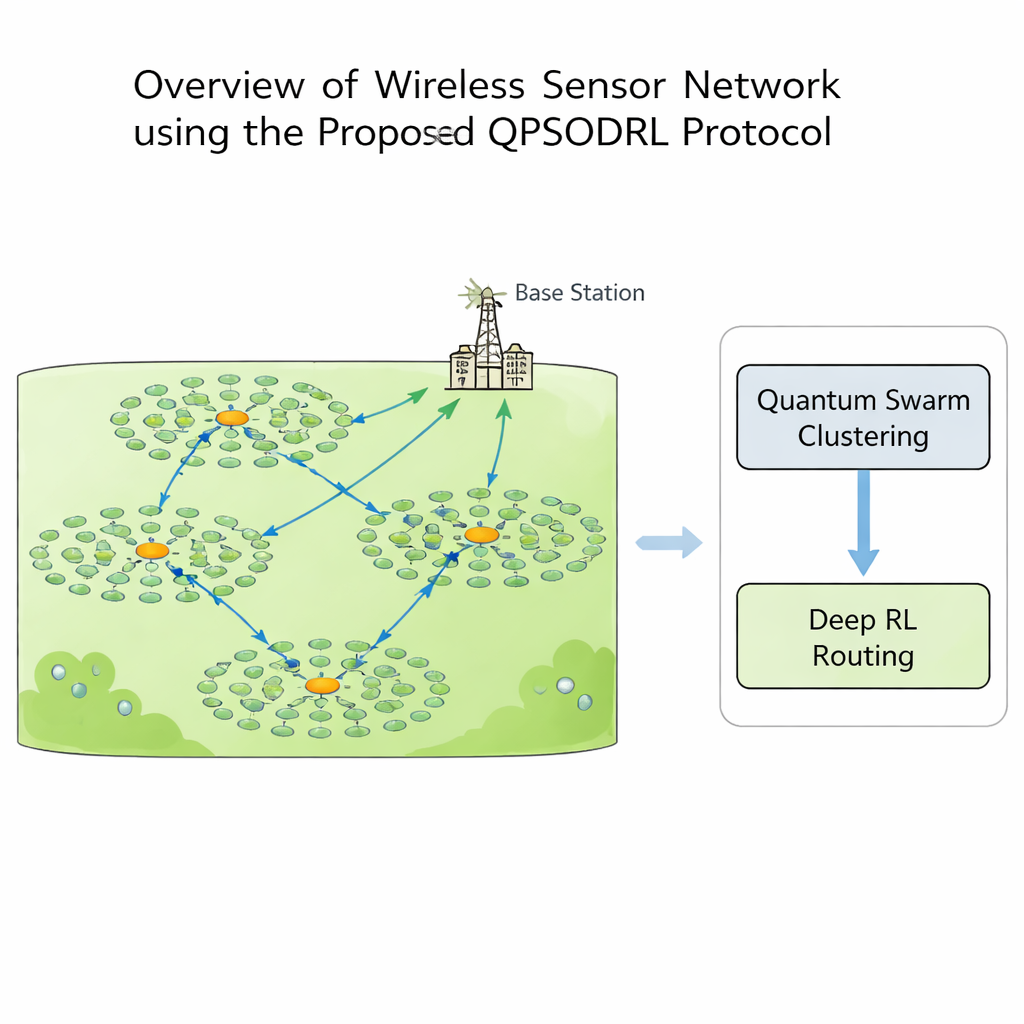
Lära nätverket att hitta bättre vägar
När klustren väl är bildade bestämmer det andra steget hur varje klusterhuvud ska skicka sina data till basstationen. Istället för att följa fasta rutter behandlar QPSODRL varje klusterhuvud som en agent i en lärandeprocess. Vid varje steg observerar agenten sin kvarvarande energi, energin och avståndet hos närliggande huvuden samt uppskattade fördröjningar, och väljer sedan nästa hopp. En specialiserad form av djup Q‑inlärning, kallad Dueling Double Deep Q‑Network, uppskattar hur bra varje val är på lång sikt. Författarna lägger till en ”entropi”-term för att avskräcka systemet från att bli för säkert för snabbt, så att det fortsätter att utforska alternativa rutter. De utformar också en förbättrad mekanism för erfarenhetsuppspelning som medvetet fokuserar inlärningen på de mest informativa situationerna — till exempel när energin är låg eller fördröjningarna ökar — så att modellen förbättras snabbare i de scenarier som är viktigast. 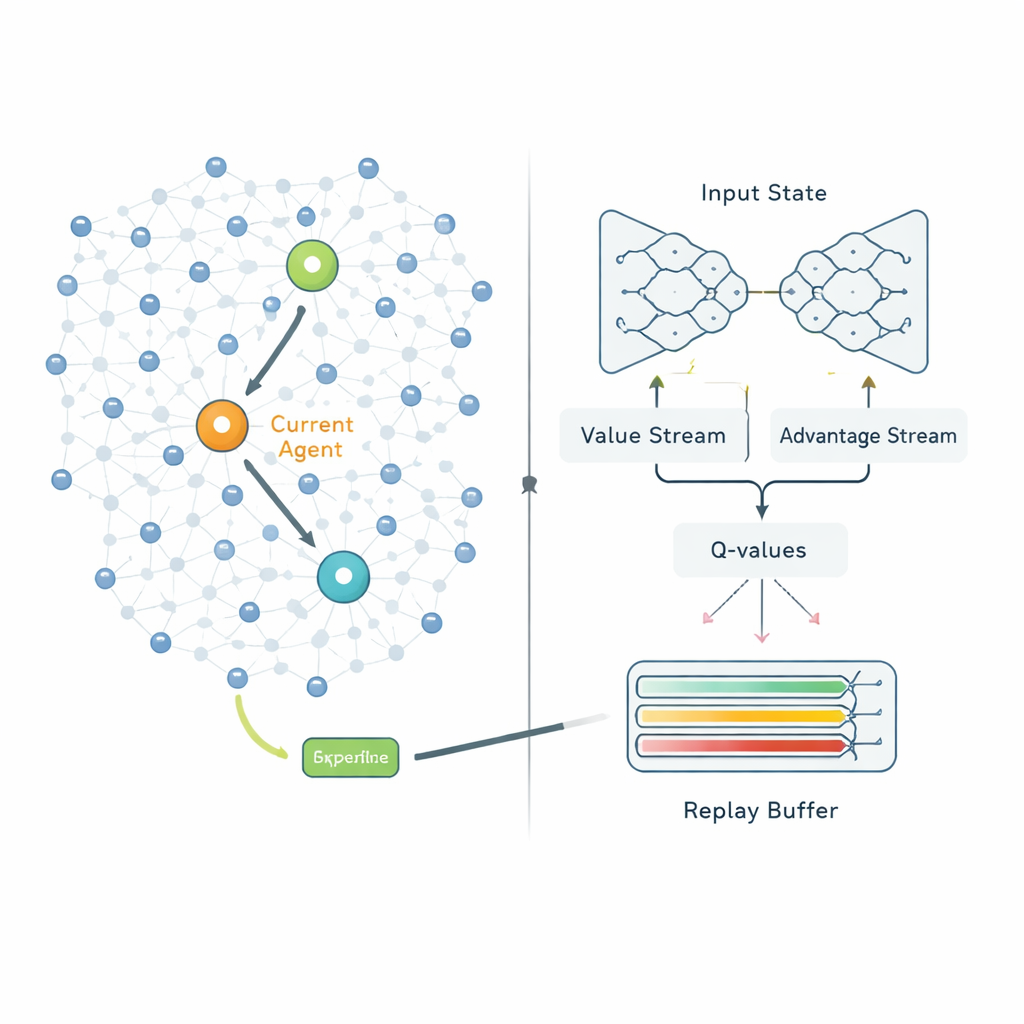
Sätta metoden på prov
För att utvärdera QPSODRL kör författaren detaljerade datorbaserade simuleringar av nätverk med 100 och 200 noder utspridda över områden av olika storlek och med varierande andel noder som fungerar som klusterhuvuden. Det nya protokollet jämförs med fyra nyligen framtagna och avancerade konkurrenter som använder partikelsvärmar, valoptimering, fuzzylogik eller andra hybrid- och inlärningsbaserade scheman. I samtliga testade konfigurationer håller QPSODRL nätverket vid liv under fler kommunikationsrundor, levererar fler datapaket till basstationen och förbrukar mindre total energi. Det fördelar också arbetsbelastningen bland klusterhuvudena mer jämnt, vilket visas av en lägre variation i hur mycket trafik varje huvud hanterar. Dessa vinster är särskilt uttalade i tuffare layouter där basstationen är placerad i fältets kant och tvingar längre hopp för vissa noder.
Vad detta innebär för system i verkligheten
För icke-specialister är huvudbudskapet att ge sensornät förmågan att både optimera sin struktur globalt och lära sig lokalt från erfarenhet kan avsevärt förlänga deras användbara livslängd. QPSODRL:s kvantinspirerade klustring håller energianvändningen i balans, medan dess djupinlärningsbaserade routning anpassar sig till förändrade förhållanden utan ständig manuell justering. Även om resultaten bygger på simuleringar med fasta, icke-rörliga noder antyder de att framtida sensordistributioner — från smarta städer till miljöövervakningsstationer — skulle kunna köra längre, falla mindre ofta och göra bättre nytta av begränsad batterikapacitet genom att anta liknande intelligenta styrstrategier.
Citering: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Nyckelord: trådlösa sensornätverk, energisnål routning, djup förstärkningsinlärning, svärmsoptimering, nätverksklustring