Clear Sky Science · sv
Kunnskapsintegration för fysikinformerad symbolisk regression med förtränade stora språkmodeller
Lära datorer att gissa naturens formler
Många av de stora idéerna i vetenskapen fångas i prydliga små ekvationer: från hur en boll faller till hur ljusvågor böljar genom rymden. Den här artikeln undersöker ett nytt sätt att hjälpa datorer att automatiskt återupptäcka sådana ekvationer från rådata, genom att låta dem konsultera en stor språkmodell—samma typ av AI som driver moderna chattbottar—så att deras gissningar inte bara blir korrekta utan också fysiskt rimliga.
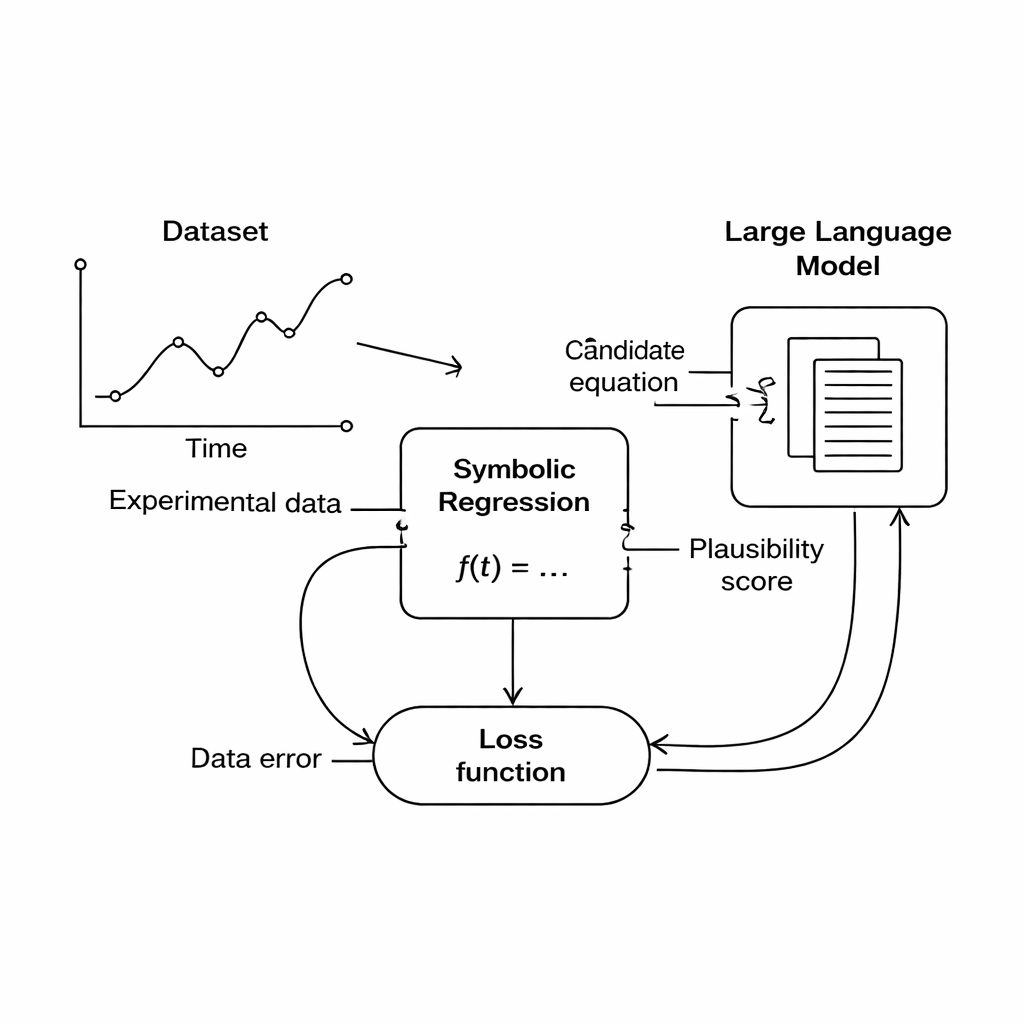
Från rådata till mänskligt läsbara lagar
Författarna fokuserar på en teknik kallad symbolisk regression, som söker efter en matematisk formel som länkar uppmätta ingångar och utgångar. Till skillnad från vanlig kurvanpassning börjar symbolisk regression inte med en fast form på formeln; istället bygger och utvecklar den kandidat-ekvationer tills en passar datan väl. Det gör metoden till ett lovande verktyg för vetenskaplig upptäckt, eftersom den potentiellt kan avslöja nya samband som ingen tidigare uttryckt. Men det finns ett problem: en formel som passar datan perfekt kan fortfarande vara nonsens ur ett fysikaliskt perspektiv—till exempel att addera en längd till en tid eller generera enheter som inte motsvarar någon verklig storhet.
Varför fysisk insikt fortfarande spelar roll
För att undvika sådant nonsens har forskare utvecklat "fysikinformerade" varianter av symbolisk regression som inbakade kända naturregler i sökningen. Dessa metoder belönar ekvationer som till exempel bevarar energi eller respekterar dimensionskonsistens. Dock har kodningen av denna kunskap vanligen krävt experter som handkonstruerar begränsningar och speciella förlustfunktioner för varje nytt problem. Det gör tillvägagångssättet kraftfullt men svårt att generalisera. Varje nytt fysikaliskt system kan behöva sitt eget omsorgsfulla designarbete, vilket begränsar tillgängligheten för icke-experter.
Låta språkmodeller bedöma ekvationerna
Denna studie föreslår en annan väg: istället för att hårdkoda domänregler, använd en stor språkmodell (LLM) som en flexibel domare av vetenskaplig rimlighet. Under sökningen producerar den symboliska regressionsmotorn kandidat-ekvationer som i någon grad passar datan. Varje ekvation översätts till text och skickas till LLM:en, tillsammans med en kort prompt som beskriver de inblandade storheterna och eventuella kända fysiska begränsningar. LLM:en returnerar poäng för tre aspekter: om ekvationens enheter är rimliga, hur enkel den är och om den verkar fysiskt realistisk. Dessa poäng vävs in i huvudobjektivet, så att datorn nu balanserar "passar datan" mot "ser ut som bra fysik" när den väljer vilka ekvationer som ska förbättras.
Sätta metoden på prov
För att se hur väl detta fungerar genomförde författarna omfattande datorexperiment på tre klassiska problem: fritt fall under jordens gravitation, enkel harmonisk rörelse för en massa på en fjäder och en dämpad elektromagnetisk våg. För varje system simulerade de tusentals brusiga mätningar under varierande förhållanden och bad sedan tre populära program för symbolisk regression att återfinna underliggande ekvationer, antingen med eller utan hjälp från en LLM. De provade tre kompakta, öppen källkod-språkmodeller—Mistral, Llama 2 och Falcon—och utforskade hur olika promptdesigner, från minimal kontext till fullständiga beskrivningar och till och med den sanna formeln, ändrade LLM:ens vägledning. I de flesta inställningar förbättrade införandet av LLM-poängen hur nära de återvunna ekvationerna kom de kända lagarna och gjorde dem mer robusta mot brus, där kombinationen av PySR (ett bibliotek för symbolisk regression) och Mistral i allmänhet presterade bäst.
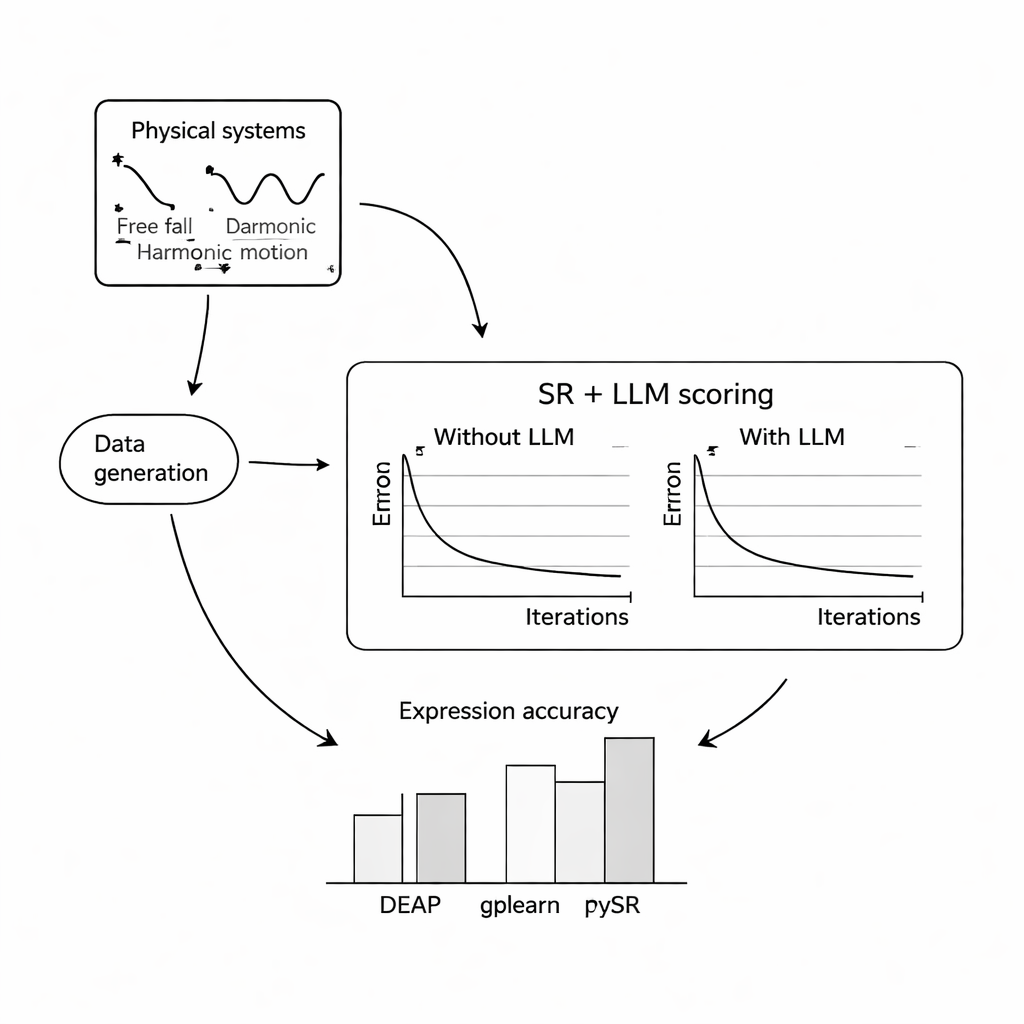
När ord styr matematiken
Ett centralt fynd är att formuleringen av prompten starkt påverkar resultaten. När promptarna innehöll tydliga beskrivningar av variabler, karaktären på experimentet och ibland den exakta målekvationen, konvergerade den LLM-styrda sökningen mer pålitligt till rätt struktur. I dessa rikare fall var de upptäckta ekvationerna ofta strukturellt identiska med sannings-enligt-lag, inte bara numeriskt nära. Författarna testade också hur tillvägagångssättet står sig vid ökande nivåer av slumpmässigt mätbrus. Medan alla metoder försämrades när datan blev brusigare och de underliggande ekvationerna mer komplexa, tenderade de LLM-augmented versionerna att tappa noggrannhet långsammare än sina standardmotsvarigheter, vilket tyder på att språkmodellens känsla för rimlighet kan fungera som en stabiliserande faktor.
Vad detta betyder för framtida upptäckter
För allmänheten är huvudbudskapet att textbaserad AI kan göra mer än att skriva essäer eller svara på frågor—den kan också vägleda andra algoritmer mot vetenskapliga ekvationer som "känns rätt" enligt vår befintliga kunskap om naturen. Metoden som presenteras här garanterar inte att varje upptäckt ekvation är korrekt, och den förlitar sig fortfarande på mänsklig översyn och omsorgsfullt utformade prompts. Men den visar att stora språkmodeller, tränade på oceaner av vetenskaplig text, kan fungera som en återanvändbar källa till domänkunskap och hjälpa automatiserade verktyg att gå från blint datamatching till att föreslå lagar som forskare kan tolka, kontrollera och bygga vidare på.
Citering: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Nyckelord: symbolisk regression, fysikinformerad AI, stora språkmodeller, vetenskaplig upptäckt, ekvationsinlärning