Clear Sky Science · sv
En djup förstärkningsinlärningsmetod för analys av dansrörelser
Lära datorer att se på dans som vi gör
Från balett till hiphop är dans full av subtila skiftningar i rytm och poser som människans öga plockar upp omedelbart — men datorer har svårt att se dem. Denna studie presenterar ett nytt sätt för artificiell intelligens att ”se” på dansvideor mer som en mänsklig expert, genom att snabbspola förbi rutinsekvenser för att fokusera på korta, avslöjande ögonblick som definierar varje stil. Resultatet är ett system som känner igen dansgenrer mer exakt samtidigt som det tittar på betydligt mindre video, vilket kan ge förbättringar för allt från digitala arkiv till sport- och underhållningsteknik.
Varför dansvideor är svåra för maskiner
På ytan låter det enkelt att lära en dator att känna igen dansstilar: mata in videor och låt djuplärande hitta mönster. I verkligheten slösar de flesta befintliga system resurser. Standardmodeller för video bearbetar antingen varje bildruta eller tar ut klipp med fasta intervaller och antar att alla ögonblick är lika viktiga. Men dansstilar skiljer sig ofta åt i små detaljer — hur en fot vrids, när en partner snurrar, eller tajmingen i en piruett — snarare än i konstant rörelse. Det innebär att många bildrutor är repetitiva eller ointressanta, och nyckelposer kan hamna mellan fasta provpunkter, vilket leder till förväxlingar mellan till exempel vals och foxtrot.
Ett smartare sätt att skumma igenom video
Forskarna föreslår ett ramverk kallat Reinforcement-based Attentive Temporal Sampling, eller RATS, som behandlar videoanalys som en aktiv sökning snarare än passivt tittande. Istället för att gå igenom bildruta för bildruta delar systemet upp en dansvideo i korta klipp och omvandlar först varje klipp till en kompakt beskrivning av dess rörelse med hjälp av ett specialiserat 3D-konvolutionsnätverk. Dessa rörelsesummeringar lagras sedan i minnet. Ovanpå detta rör sig en beslutsfattande agent genom klippsekvensen och väljer om den ska ta ett litet hopp framåt, ett större hopp, eller stanna och lämna en stilprediktion. I praktiken lär sig systemet att bläddra i tiden, stanna vid talande mönster och hoppa över mindre användbara partier.
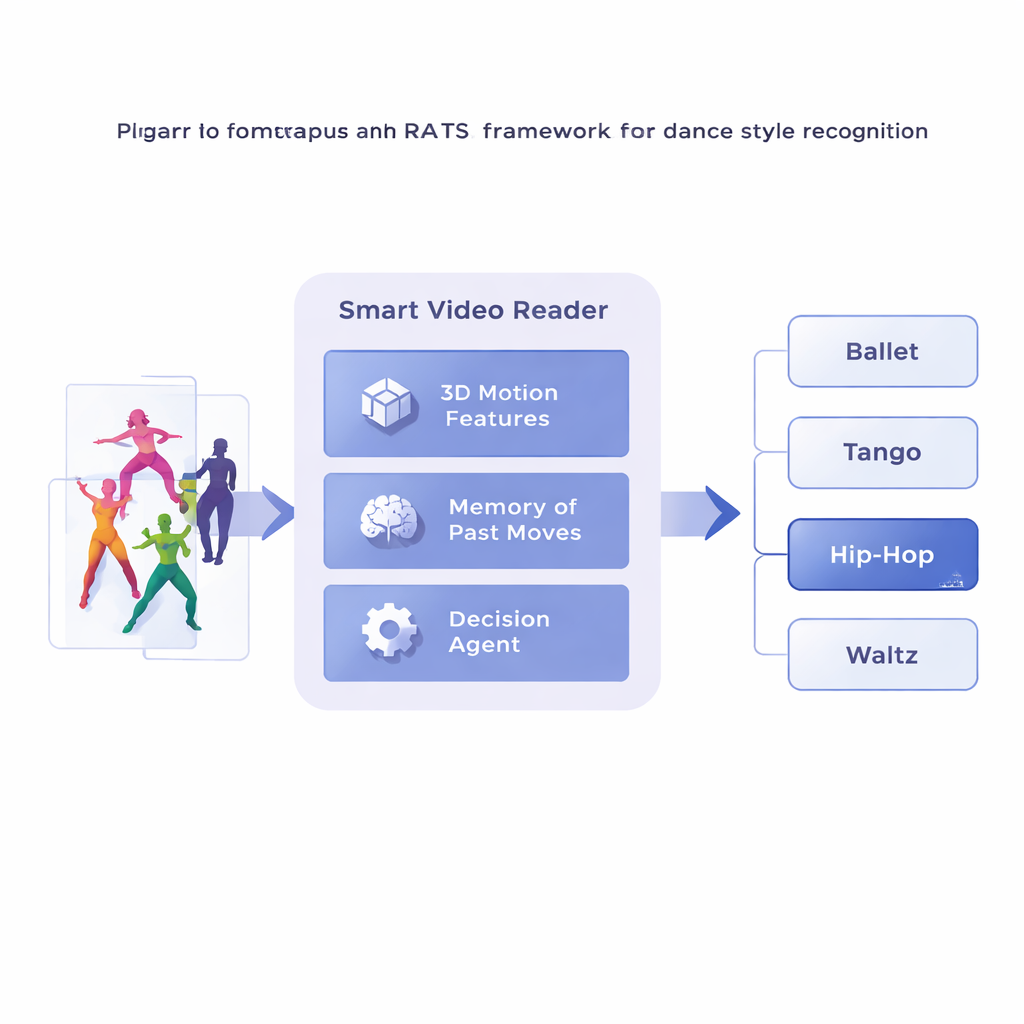
Lära sig när man ska titta och när man ska avgöra
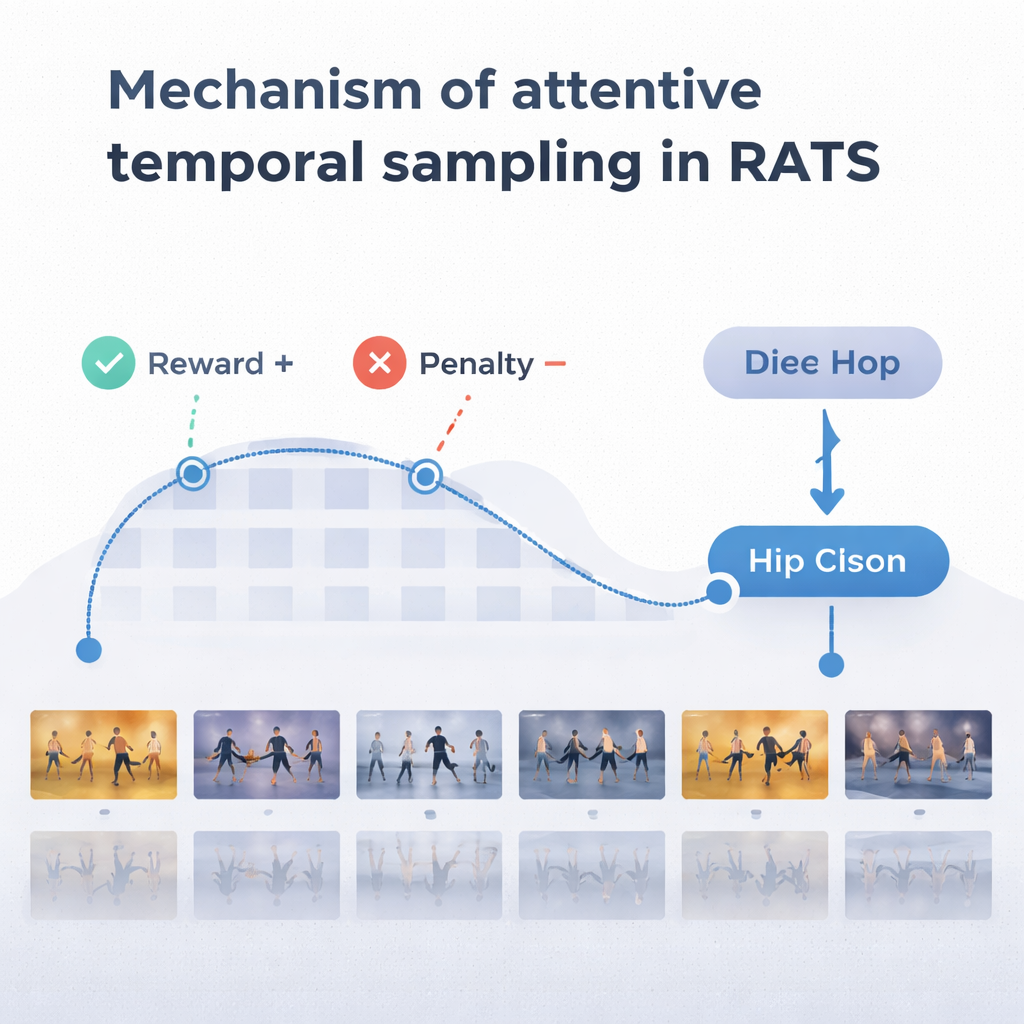
För att göra rimliga val förlitar sig agenten på en form av minne inspirerat av hur vi minns både tidigare och framväxande rörelser. Ett bidirektionellt återkommande nätverk håller reda på vad systemet redan har ”sett” och hur aktuella klipp relaterar till den historiken. Vid varje steg väger agenten tre alternativ: ta ett kort hopp för att undersöka finare detaljer som fotarbete, göra ett längre språng över repetitiv rörelse, eller stanna och klassificera dansen. Systemet tränas med belöningar och straff: det får en stor positiv poäng för ett korrekt beslut, en stor negativ poäng för ett felaktigt, och en liten kostnad varje gång det hoppar framåt. Denna balans uppmuntrar agenten att vara både noggrann och effektiv — vänta tills tillräcklig evidens finns, men inte vandra genom hela videon.
Överträffar konventionella dansklassificerare
Teamet testade RATS på Let’s Dance-datasetet, en utmanande samling av 1 000 videor som täcker tio stilar, från flamenco och tango till swing och square dance. Jämfört med flera befintliga metoder, inklusive standard djupa nätverk och andra dansfokuserade modeller, uppnådde RATS högst noggrannhet — ungefär 92 % — och bäst balans mellan precision och återkallelse. Det visade sig också vara statistiskt bättre än starka konkurrenter, inte bara en liten slumpmässig skillnad. Viktigt är att systemet nådde dessa resultat samtidigt som det i genomsnitt analyserade endast omkring 38 % av bildrutorna. En jämn provtagning var snabbare men missade avgörande ögonblick och försämrade prestationen; att bearbeta varje bildruta var långsammare och ändå mindre exakt än det riktade tillvägagångssättet.
Vad detta betyder bortom dansgolvet
För en icke-specialist är kärnbudskapet enkelt: datorer kan göra ett bättre jobb när de lär sig att vara selektiva tittare. Genom att lära en AI att koncentrera sig på ”gyllene ögonblick” i tiden visar detta arbete att maskiner kan känna igen komplexa mänskliga rörelser mer korrekt samtidigt som de använder färre resurser. Även om studien fokuserar på dans kan samma idé hjälpa system att plocka ut nyckelelement i sportrutiner, säkerhetsfilmer eller vilken lång video som helst där viktiga händelser är korta och utspridda. Med andra ord kan smartare tittande — inte mer tittande — vara framtiden för videoförståelse.
Citering: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Nyckelord: dansigenkänning, videoanalys, djuplärande, förstärkningsinlärning, mänsklig rörelse