Clear Sky Science · sv
Kinesisk modell för extraktion av rumsliga relationer genom integration av geografiska semantiska funktioner
Lära datorer att förstå var platser ligger
Varje dag beskriver vi platser i enkla uttryck: en stad ligger söder om en flod, en park är nära ett universitet, en motorväg går genom en provins. Att omvandla den här typen av vardagsspråk till exakt digital kunskap är avgörande för smarta kartor, navigationsappar och geografisk forskning. Denna artikel presenterar en ny metod, kallad PURE‑CHS‑Attn, som hjälper datorer att läsa kinesiska texter och automatiskt förstå de rumsliga relationerna mellan platser mer exakt än tidigare.
Varför rumsligt språk spelar roll
Rumsliga relationer är ord och fraser som berättar hur platser hänger ihop i rummet, till exempel ”inne i”, ”bredvid”, ”norr om” eller ”30 kilometer från”. De bildar en bro mellan den verklighet vi ser på kartor och de begrepp vi använder i våra huvuden. I geografiska informationssystem (GIS) ligger dessa relationer till grund för hur data organiseras, söks och analyseras. De är också centrala i andra områden: till exempel att kombinera satellitbilder, följa rörelser i video, planera industrilayout eller studera hur klimat och landformer formar biodiversitet. Eftersom mycket av denna information är skriven i naturligt språk blir tillförlitliga verktyg som kan läsa text och extrahera rumsliga relationer automatiskt allt viktigare.
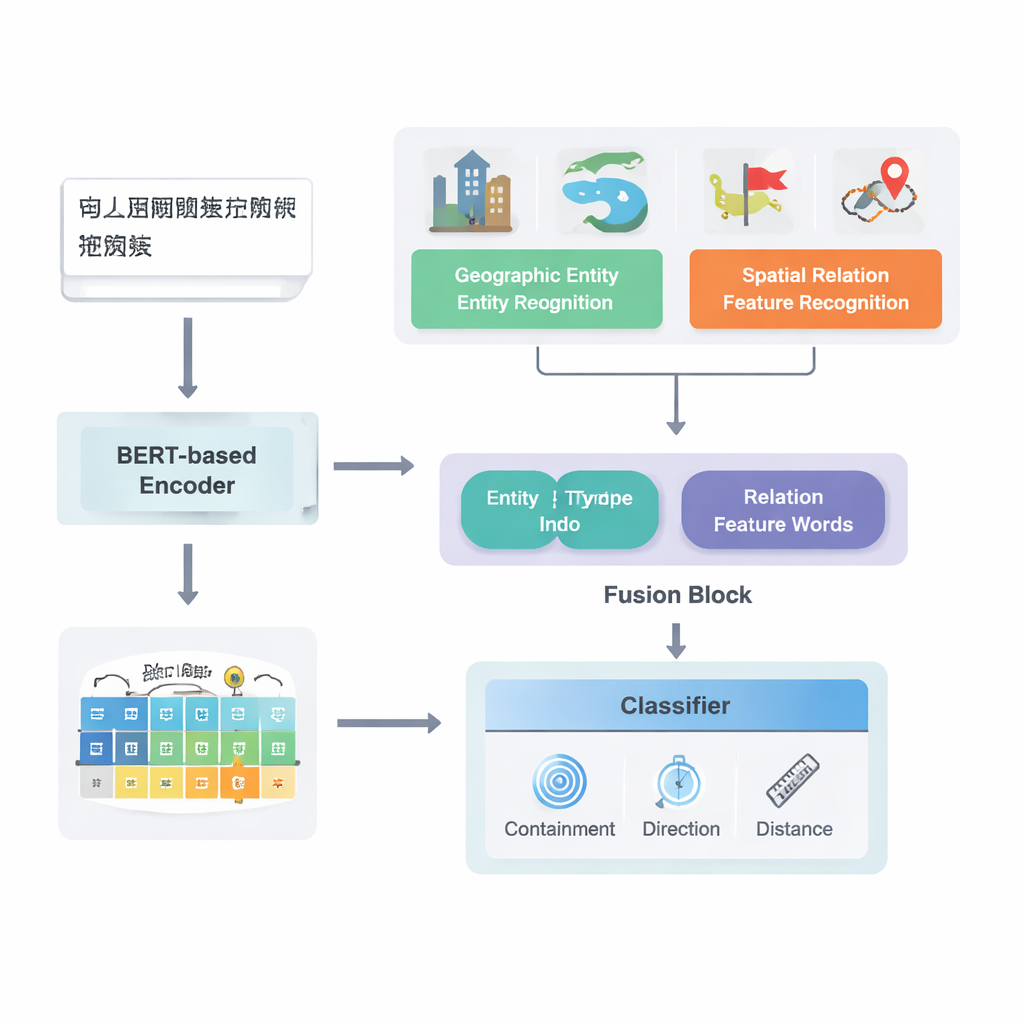
Från rå text till kartlagda relationer
Författarna fokuserar på kinesiska texter och bygger vidare på en redan stark djupinlärningspipeline känd som PURE. Deras förbättrade modell, PURE‑CHS‑Attn, arbetar i flera steg. Först skannar den meningar för att hitta geografiska enheter som berg, floder, städer och administrativa regioner, och etiketterar varje enhet med en typ (till exempel landyta, vattendrag, allmän anläggning, historisk plats eller administrativ indelning). Därefter upptäcker den rumsliga relations"nyckelord" som ”gränsar till”, ”rinner genom”, ”söder om” eller ”nära”, vilka signalerar hur två platser förhåller sig till varandra. En kraftfull språkmodell, BERT‑wwm‑ext, omvandlar tecknen i varje mening till numeriska vektorer som fångar deras betydelse och kontext. Dessa vektorer matas in i separata komponenter som känner igen enheter och relationsord och vidarebefordrar sedan sina resultat till en fusionsmodul.
Att blanda mänsklig kunskap med maskininlärning
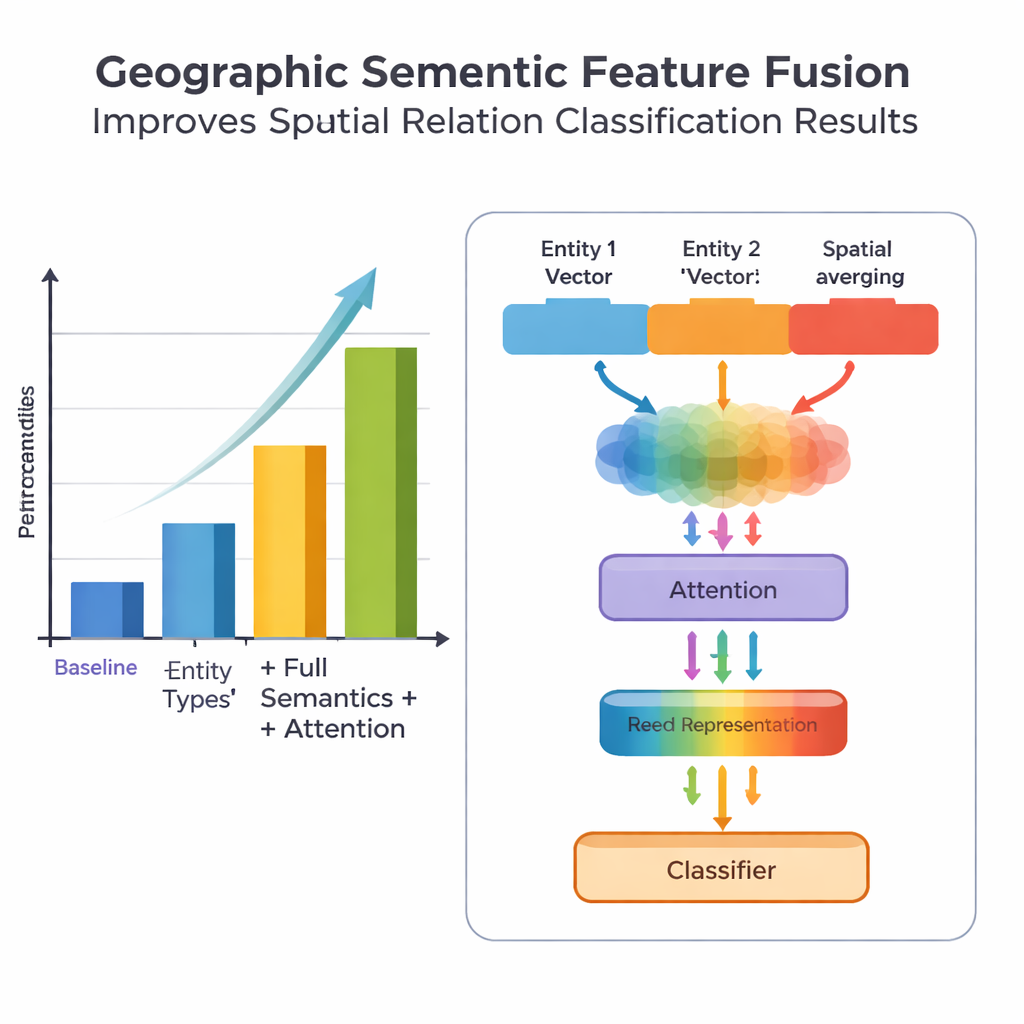
En central nyhet i arbetet ligger i hur det smälter samman geografisk kunskap med inlärda textmönster. Istället för att behandla varje ord lika utnyttjar modellen två slags semantisk information som människor naturligt använder: typen av varje geografisk enhet och de specifika rumsliga relationsorden som förbinder dem. Fusionsmodulen kombinerar först vektorerna för de två enheterna med vikter som beror på hur ofta olika typer av platser (till exempel två administrativa områden versus en flod och ett län) förekommer i olika relationstyper. Därefter blandas vektorerna för de rumsliga relationsorden in. Utöver denna ”grundläggande fusion” lägger författarna till en attention‑mekanism som låter modellen dynamiskt fokusera på de mest informativa delarna av enhets–ord‑kombinationen. Den slutliga sammansatta representationen skickas till en klassificerare, som kan tilldela en eller flera relationstyper—topologiska (som innehåll eller angränsning), riktning (norr, söder osv.) eller avståndsbaserade—mellan varje par platser i meningen.
Sätta modellen på prov
För att utvärdera sitt tillvägagångssätt samlade teamet och noggrant annoterade en dataset från Encyclopedia of China: Chinese Geography, innehållande 1381 meningar och 368 rumsliga relationspar. De jämförde flera versioner av modellen: en baslinje som endast använder grov platsinformation, en version med finare enhetstyper, en version som också lägger till rumsliga relationsord, och deras fullständiga PURE‑CHS‑Attn‑modell med den nya fusionen och attention‑designen. Enligt standardmått för precision, recall och F1‑poäng förbättrade PURE‑CHS‑Attn prestandan med cirka 7 % i precision, 6,5 % i recall och 6,7 % i F1 jämfört med baslinjen. Den var särskilt stark i att känna igen topologiska och riktningbaserade relationer, och hanterade sällsynta ”få‑skotts” relationstyper bättre än enklare modeller. När den jämfördes med tre nyliga toppmoderna system, inklusive ett baserat på stora språkmodeller, hamnade PURE‑CHS‑Attn på en nära andraplats samtidigt som den förblev mycket lättare och enklare att driftsätta.
Utmaningar och framtida riktningar
Trots dessa framsteg har modellen fortfarande svårt med avståndsrelationer, särskilt när det finns endast några få träningsexempel. Författarna visar att deras dataset innehåller väldigt få sådana fall, vilket begränsar vad någon dataintensiv metod kan lära sig. De noterar också att en blint genomsnittlig hantering av många rumsliga relationsord i en mening kan introducera brus, vilket deras attention‑mekanism hjälper mot men inte helt löser. Framåt föreslår de två lovande vägar: att utöka och balansera träningsdata med hjälp av augmentation, och att kombinera deras geografiska semantiska fusion med tekniker från stora språkmodeller och promptbaserad inlärning för att ytterligare förbättra prestanda i datasvaga scenarier samtidigt som systemet hålls effektivt.
Vad detta betyder för vardaglig kartläggning
Enkelt uttryckt lär denna forskning datorer att läsa rumsliga beskrivningar på kinesiska mer som människor gör, genom att uppmärksamma vilka slags platser som nämns och exakt hur deras relationer formuleras. PURE‑CHS‑Attn visar att en kombination av strukturerad geografisk kunskap och modern djupinlärning leder till mer exakt och robust extraktion av ”vem är var, i relation till vad” från text. Detta banar väg för smartare, mer automatiserade GIS‑system, rikare geografiska kunskapsgrafer och bättre verktyg för att utforska hur rum beskrivs inom vetenskap, politik och vardaglig kommunikation.
Citering: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Nyckelord: extraktion av rumsliga relationer, geospatial AI, geografisk semantik, kinesisk textutvinning, GIS‑automation