Clear Sky Science · sv
Utvärdering av maskinlärd precision i kärndata för fullkärne‑Monte Carlo‑neutrontik och beräkningsprestanda
Varför snabbare reaktorsimuleringar spelar roll
Kärnkraftverk förlitar sig på detaljerade datoriserade modeller för att förutsäga hur bränslet beter sig över månader och år av drift. Dessa modeller är avgörande för säkerhet, effektivitet och vid konstruktion av nya reaktorer, men de är ökända för att vara långsamma och minneskrävande. Denna artikel undersöker om maskininlärning kan krympa de stora kärndatatabeller som driver dessa simuleringar — och därigenom dramatiskt sänka beräkningskostnaderna — utan att offra den fysiska noggrannhet som ingenjörer är beroende av.
Krymper data bakom fysiken
Varje gång en simulerad neutron rör sig genom en virtuell reaktorkärna konsulterar koden stora tabeller som beskriver sannolikheten för att den ska studsas, absorberas eller dela ett atomkärna. Dessa tabeller, kallade kärndata‑bibliotek, kodar sannolikheter över tusentals energipunkter för många isotoper i bränslet och dess sönderfallsprodukter. Författarna bygger vidare på en tidigare maskininlärningsmetod som ”tunnar ut” dessa tabeller: den tar bort redundanta energipunkter samtidigt som skarpa drag bevaras, såsom reaktionströsklar och resonanstoppar där sannolikheterna ändras snabbt. Istället för att återskapa datan genom en lång, traditionell bearbetningskedja redigerar metoden OpenMC:s inbyggda HDF5‑filer direkt och behåller endast cirka 10–50 % av de ursprungliga gridpunkterna för 23 särskilt viktiga nuklider.
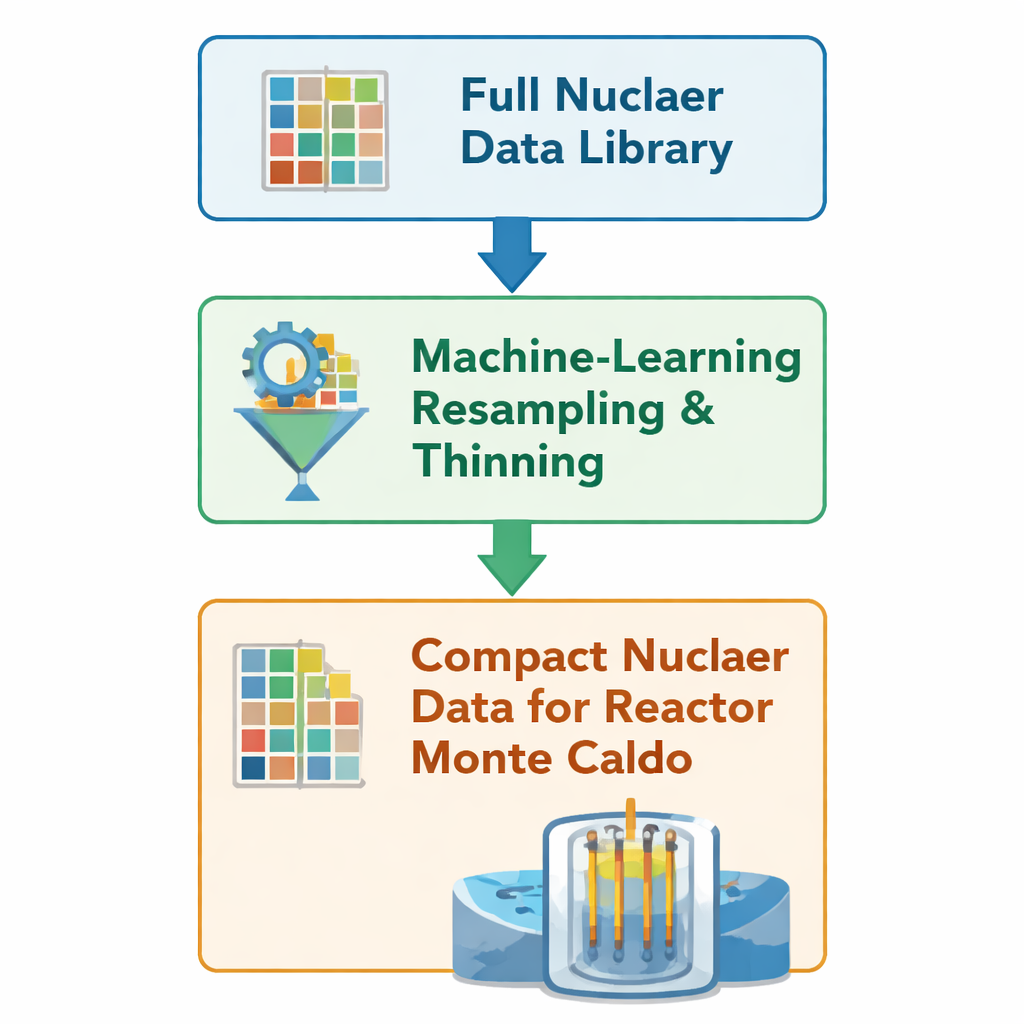
Test av idén i fullskaliga reaktorkärnor
För att se om denna slimmade data fortfarande ger pålitliga resultat i realistiska miljöer kör teamet årslånga simuleringar av två stora tryckvattenreaktorer: en European Pressurized Reactor (EPR) och en VVER‑1000, med den öppna Monte Carlo‑koden OpenMC. För varje kärna genomför de två i övrigt identiska kampanjer: en med det fullständiga kärndatabiblioteket och en med den maskin‑förtunnade versionen. All geometri, driftsförhållanden och numeriska inställningar hålls fasta; endast datatabellerna bakom fysiken skiljer sig åt. De stänger av andra accelerationsfunktioner i OpenMC så att eventuella förändringar i hastighet eller minnesanvändning direkt kan spåras till den reducerade datan, inte till förändringar i algoritmer eller inställningar.
Hastighetsvinster med snäva felgränser
Vinsterna är betydande. För EPR‑fallet sjunker total vägg‑klocktid med cirka 18 %, och för VVER‑1000 krymper körtiden med ungefär 43 %. Minnesanvändningen förändras mer måttligt: toppanvändningen faller med cirka 4 % i EPR och ökar med cirka 5 % i VVER‑1000, vilket speglar skillnader i hur mycket tid varje modell spenderar på att slå upp kärndata jämfört med att spåra partikelbanor genom geometrin. Avgörande är att de viktigaste reaktornivåmåtten förblir mycket nära originalen. Under ett helt år i VVER‑1000 avviker den effektiva multiplikationsfaktorn — i praktiken hur många neutroner varje fission i genomsnitt ger upphov till — aldrig med mer än cirka 100 delar per miljon, och vanligtvis bara med några tiotal delar per miljon. För nyckelreaktionskanaler såsom fission i uran‑235 och uran‑238 samt neutronfångst i xenon‑135 och samarium‑149 håller sig genomsnittliga skillnader långt under en tiondels procent.
Bränslets utveckling och förgiftningsämnen förblir korrekta
Då långtidsbeteendet i reaktorn inte bara beror på ögonblickliga reaktioner utan även på hur bränsle och fissionsprodukter byggs upp och förbrukas, följer författarna också de förändrade lagren av viktiga isotoper. De undersöker huvudisotoperna av uran, en serie plutoniumisotoper som bildas från uran‑238, och starka ”förgiftnings”nuklider som binder neutroner, särskilt xenon‑135 och samarium‑149. Även efter ett helt år är skillnaderna i dessa lager mellan fulla och reducerade databeroenden små: i storleksordningen några hundradels procent för xenon och samarium, och generellt under en tiondels procent för plutonium‑arterna. Uran‑235 och uran‑238, som dominerar kärnans energiproduktion och neutrontiska balans, reproduceras med betydligt bättre än en hundradels procent. Där relativa fel tillfälligt överstiger en procent för vissa plutoniumisotoper inträffar det tidigt i cykeln när deras absoluta mängder fortfarande är extremt små, så den praktiska effekten på reaktorbeteendet är försumbar.
Vad detta betyder för framtida reaktormodellering
För icke‑specialister är den väsentliga slutsatsen att en noggrant tränad maskininlärningsprocedur kan göra de kärnvetenskapliga ”uppslags-tabellerna” i avancerade reaktorsimuleringar avsevärt mindre och snabbare att använda, samtidigt som den simulerade reaktorns beteende förblir nästan omöjligt att skilja från det traditionella tillvägagångssättet. Studien visar detta för två industriskaliga reaktorkärnor över ett helt års drift, med felmarginaler som är små jämfört med andra typiska osäkerheter i reaktoranalyser. Författarna betonar att deras slutsatser för närvarande gäller stationära tryckvattenreaktorer med ett specifikt databibliotek och kodinställningar, och att mer arbete behövs för att testa andra reaktortyper och transienta förhållanden. Ändå tyder resultaten på en lovande väg mot snabbare, mer effektiva högupplösta kärnsimuleringar, vilket möjliggör fler konstruktionsstudier och säkerhetsanalyser med begränsade datorkapaciteter.
Citering: Hashemi, A., Macián-Juan, R. & Ohlerich, M. Evaluating machine learned nuclear data precision in full core nuclear reactor Monte Carlo neutronics and computational efficiency analyses. Sci Rep 16, 1314 (2026). https://doi.org/10.1038/s41598-026-35227-9
Nyckelord: kärnreaktorsimulering, maskininlärning, Monte Carlo‑neutronik, kärndata‑bibliotek, kokvattenreaktorer med trycksatt vatten