Clear Sky Science · sv
Effektiv upptäckt av AI-genererade vetenskapliga abstrakt med en lättvikts-transformer
Varför det är viktigt att upptäcka AI-skriven vetenskap
I takt med att artificiell intelligens blir skicklig på att skriva kan den nu formulera vetenskapliga sammanfattningar som nästan är omöjliga att skilja från de som skrivits av människor. Det väcker svåra frågor: hur kan tidskrifter, universitet och läsare vara säkra på att ett forskningsabstrakt verkligen återspeglar en forskares arbete och inte en maskins påhitt? Denna artikel tar itu med problemet genom att bygga ett snabbt, kompakt verktyg som kan flagga AI-skrivna vetenskapliga abstrakt med mycket hög tillförlitlighet, och erbjuder ett praktiskt försvar för akademisk integritet.
Bygga ett testfält av verkliga och syntetiska abstrakt
För att mäta och förbättra AI-textupptäckt behövde författarna först pålitliga data. De samlade 5 000 vetenskapliga abstrakt från den öppna förtryckssajten arXiv, täckande fem områden: datorseende, signalbehandling, kvantitativ biologi, fysik och andra ämnen inom datavetenskap. För varje mänskligt skrivet abstrakt använde de en stor språkmodell för att generera en AI-version utifrån artikelns titel, noggrant kontrollera närapå-duplikattexter och ta bort uppenbara ledtrådar som webbadresser eller kodutdrag. De såg också till att AI- och människotexter hade liknande längd, så att detektorn inte bara kunde förlita sig på grova statistikmått som ordantal.
En kompakt modell anpassad för verkligheten
I stället för att använda en enorm och kostsam AI-modell valde forskarna ett mindre system känt som DistilBERT, en strömlinjeformad version av en populär språkmodell. De finjusterade den för att avgöra, för varje abstrakt, om det var skrivet av en person eller genererat av AI. Modellen läser upp till 256 tokens—ungefär ett par stycken—och ger en poäng mellan noll och ett, tolkad som sannolikheten att texten är maskinskriven. Träning och utvärdering följde ett strikt protokoll: data delades upp i tränings-, validerings- och testuppsättningar utan överlappning, och teamet rapporterade inte bara noggrannhet utan också hur väl modellen beter sig när den tillåtna falsklarmfrekvensen hålls mycket låg, ett regime som spelar roll när man anklagar verkliga författare för att ha använt AI.
Hur väl detektorn presterar
På abstrakt från datorseende, huvudtestbädden, var detektorn anmärkningsvärt träffsäker. Den klassificerade korrekt 499 av 500 AI-skrivna texter och 495 av 500 mänskliga texter, vilket gav ungefär 99,4 % noggrannhet och en nästan perfekt poäng på en standardprestandakurva. När författarna tvingade systemet att göra högst ett falskt anklagande i hundra fall fångade det fortfarande omkring 90 % av AI-texterna; med en något högre tolerans på fem falsklarm per hundra fångade det omkring 97 %. Jämfört med en rad alternativ—inklusive enklare statistiska verktyg och andra transformer-modeller—visade sig den kompakta detektorn konsekvent bäst, särskilt i mer krävande scenarier.
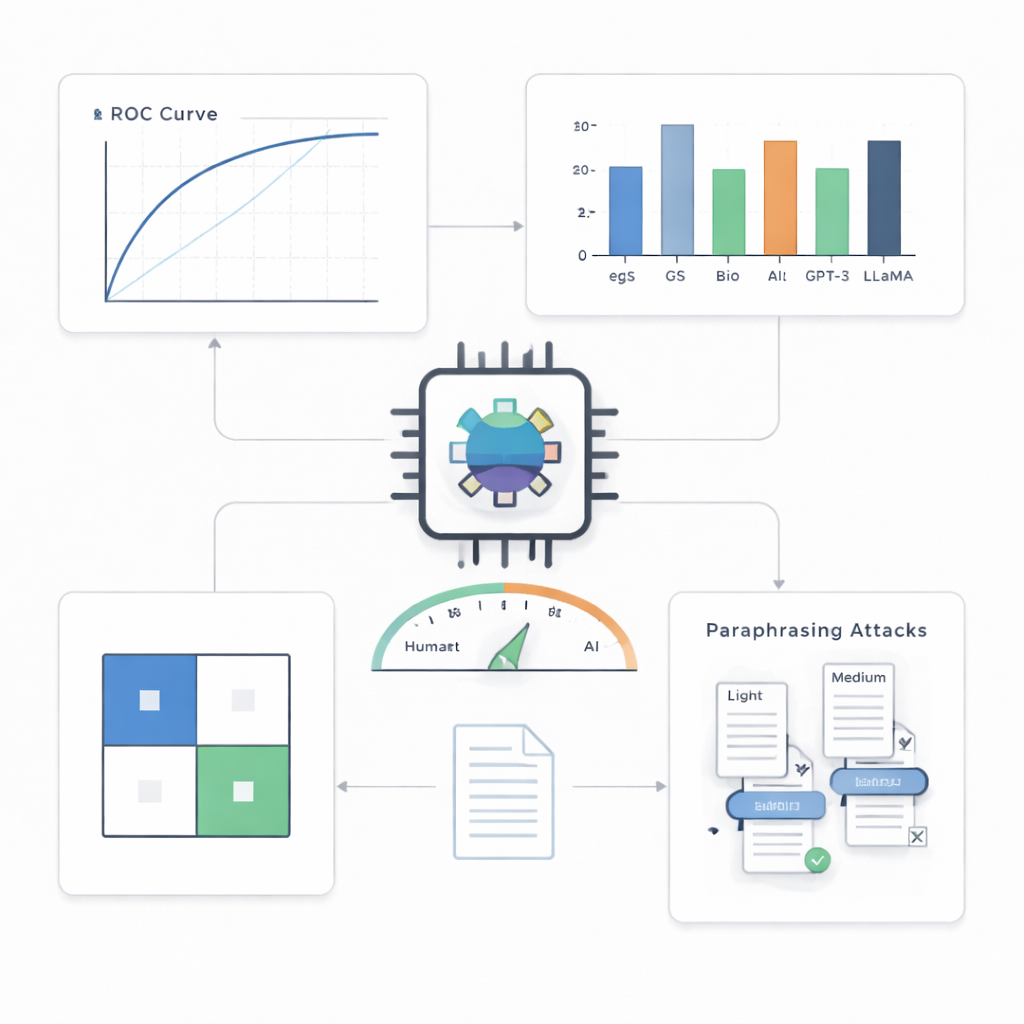
Bortom ett fält, en modell och enkla knep
En nyckelfråga är om en sådan detektor klarar av skrivstilar och AI-system den aldrig sett tidigare. Författarna testade den på abstrakt från andra vetenskapliga fält och på texter skrivna av flera olika avancerade språkmodeller. Över domäner höll prestandan sig stark med bara måttliga nedgångar, vilket tyder på att systemet fångar generella mönster i AI-skrivande snarare än egenheter hos ett ämnesområde. Mot osedda AI-modeller presterade den också väl, om än inte lika perfekt som i hemmamiljön. Den tuffaste utmaningen kom från parafraseringsattacker: när en annan AI omskrev maskingenererade abstrakt för att låta annorlunda samtidigt som meningen bevarades blev detektorn märkbart sämre. Vid omskrivning av medelstyrka steg andelen AI-texter som smet igenom till nästan 30 %, vilket visar att även sofistikerade detektorer kan luras av avsiktlig fördunkling.
Vad detta innebär för vetenskap och dess skyddsåtgärder
Studien visar att AI-skrivna vetenskapliga abstrakt fortfarande lämnar subtila spår som en väl utformad modell kan plocka upp, även när modellen är tillräckligt liten för att köras på måttlig hårdvara. Det gör det praktiskt möjligt för förlag, konferenser och universitet att granska stora volymer inskick utan enorma beräkningskostnader. Samtidigt understryker sårbarheten för parafrasering att sådana verktyg inte är någon universalmedel. Författarna argumenterar för att AI-textupptäckt bör kombineras med andra skyddsåtgärder—såsom redaktionellt omdöme, plagiatkontroller och krav på transparens—för att skydda trovärdigheten i vetenskaplig kommunikation i takt med att AI-systemen fortsätter att förbättras.
Citering: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
Nyckelord: Upptäckt av AI-text, vetenskapliga abstrakt, akademisk integritet, stora språkmodeller, maskingenererad text